-
-
Main Feature
-
Main Page
Inspiration
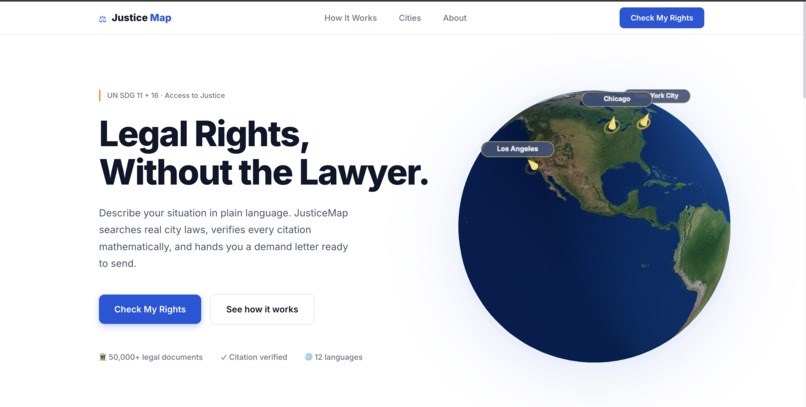
Over 80% of low-income Americans who face a legal problem never get help, not because their case isn't valid, but because legal guidance is expensive, intimidating, and inaccessible. A tenant facing an illegal eviction in Chicago has the same rights as someone who can afford a $400/hour attorney. They just don't know it. JusticeMap exists to close that gap.
What It Does
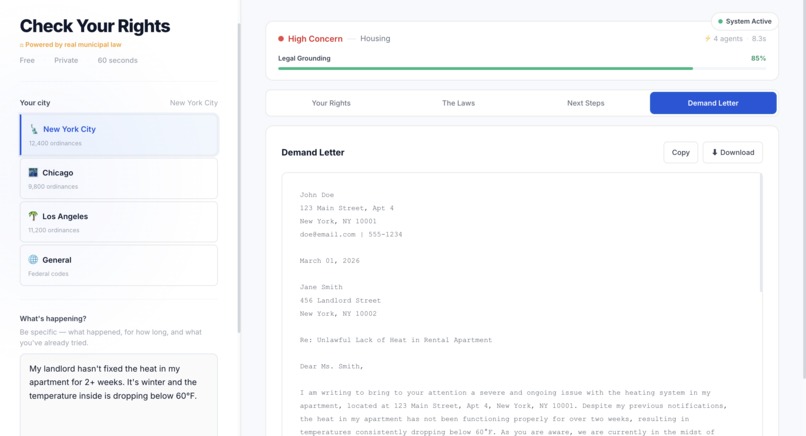
JusticeMap lets any urban resident describe their legal situation in plain language and receive:
- A verified legal analysis grounded in real municipal codes for their city
- Specific law citations with mathematical confidence scores proving accuracy
- Plain-English explanation of their rights
- A formal demand letter ready to send to their landlord or institution
- Escalation to real free legal aid organizations when the case needs a human
Supported cities: New York City, Chicago, Los Angeles. Supported languages: 12, via automatic language detection.
How We Built It
Retrieval Architecture
The core is a two-stage retrieval pipeline over a corpus of real scraped municipal codes:
Stage 1 — Bi-encoder retrieval: We embed the entire legal corpus using
sentence-transformers/all-MiniLM-L6-v2 into a ChromaDB vector store at
index time. At query time, the user's situation is embedded and we perform
approximate nearest-neighbor search to retrieve the top 20 candidate chunks.
This stage optimizes for recall.
Stage 2 — Cross-encoder re-ranking: The top 20 candidates are re-scored
by cross-encoder/ms-marco-MiniLM-L-6-v2, which reads each query-document
pair jointly and assigns a precise relevance score. We take the top 5.
This stage optimizes for precision.
This two-stage architecture mirrors how production search systems at Google and LinkedIn work, bi-encoder for speed across millions of documents, cross-encoder for precision on the shortlist.
Multi-Agent Reasoning Pipeline
Rather than a single LLM prompt, we built 4 specialized Groq based agents:
IntakeAgent — Parses the raw user input into structured facts, detects urgency, and generates optimized retrieval queries. This query rewriting step dramatically improves retrieval precision vs passing raw user text to the vector store.
ResearchAgent — Takes the retrieved law chunks and extracts the most relevant statutes, their applicability scores, and jurisdiction-specific enforcement notes.
AnalysisAgent — Reasons over the ResearchAgent output plus live Wolfram Alpha city statistics (median rent, income, population) to produce a structured legal analysis with severity rating and recommended actions.
LetterAgent — Drafts a formal demand letter using the full context from all prior agents.
Grounding Verification
The most critical component: a mathematical hallucination guard that replaces LLM self-checking with cosine similarity attribution scoring.
For every claim in the legal analysis, we compute:
$$\text{score}(c_i) = \max_{j} \frac{\vec{c_i} \cdot \vec{s_j}}{|\vec{c_i}||\vec{s_j}|}$$
where \( \vec{c_i} \) is the embedding of claim \( i \) and \( \vec{s_j} \) is the embedding of source chunk \( j \).
A claim is verified if its maximum cosine similarity to any retrieved source chunk exceeds 0.70. The overall confidence score is the mean across all claims. This gives users a mathematical proof that the analysis is grounded in retrieved law, not hallucinated from training data.
In a legal context, a confident wrong answer causes real harm. This architecture was built entirely around that constraint.
Live Contextual Data
Wolfram Alpha's computational knowledge engine provides real-time city statistics that contextualize every legal analysis (median rent, household income, population). When JusticeMap says "your rent represents 42% of typical monthly income in Chicago," that's a live computed statistic, not cached data.
Challenges
Retrieval quality on edge cases — Legal language is highly domain-specific. Early retrieval runs returned tangentially related results for non-housing queries. The query rewriting IntakeAgent was the breakthrough: transforming "my landlord is ignoring me" into "landlord failure to respond habitability obligations tenant rights Chicago" dramatically improved precision.
Hallucination guard calibration — Setting the grounding threshold required testing across dozens of query types. Too low and unverified claims slip through. Too high and even well-grounded responses get flagged. 0.70 cosine similarity emerged as the right balance empirically.
What We Learned
The most important insight: retrieval and reasoning are separate problems that require separate solutions. Mixing them (asking an LLM to both find and reason over information) produces worse results than solving each with the right tool. Vector search for retrieval, LLM for reasoning, cosine similarity for verification.
What's Next
- Expand to 10 more cities with scraped local municipal codes
- Real-time law update pipeline to keep the corpus current
- Integration with court filing systems for direct petition submission
- Mobile app for communities with lower desktop access ```
Built With
- anthropic-claude-api
- beautiful-soup
- chromadb
- d3.js
- fastapi
- framer-motion
- langchain
- langdetect
- numpy
- python
- react
- react-three-fiber
- scikit-learn
- sentence-transformers
- tailwind-css
- three.js
- typescript
- wolfram-technologies







Log in or sign up for Devpost to join the conversation.