Just Another Open Lab
An open-source data collection tool designed to meet the evolving challenges of data-driven analysis in life-science research.
This project was submitted to cuHacking2021, where it received the prize for best hardware hack. We are currently in the proof-of-concept stage and are actively raising awareness in order to gauge community interest and seek feedback/partnerships.
Introduction
As the use of machine-learning and data-driven analysis has risen in the life-sciences, so has the need for improved data collection and sharing.
- Expanded Capabilities: simultaneous data collection from multiple sources.
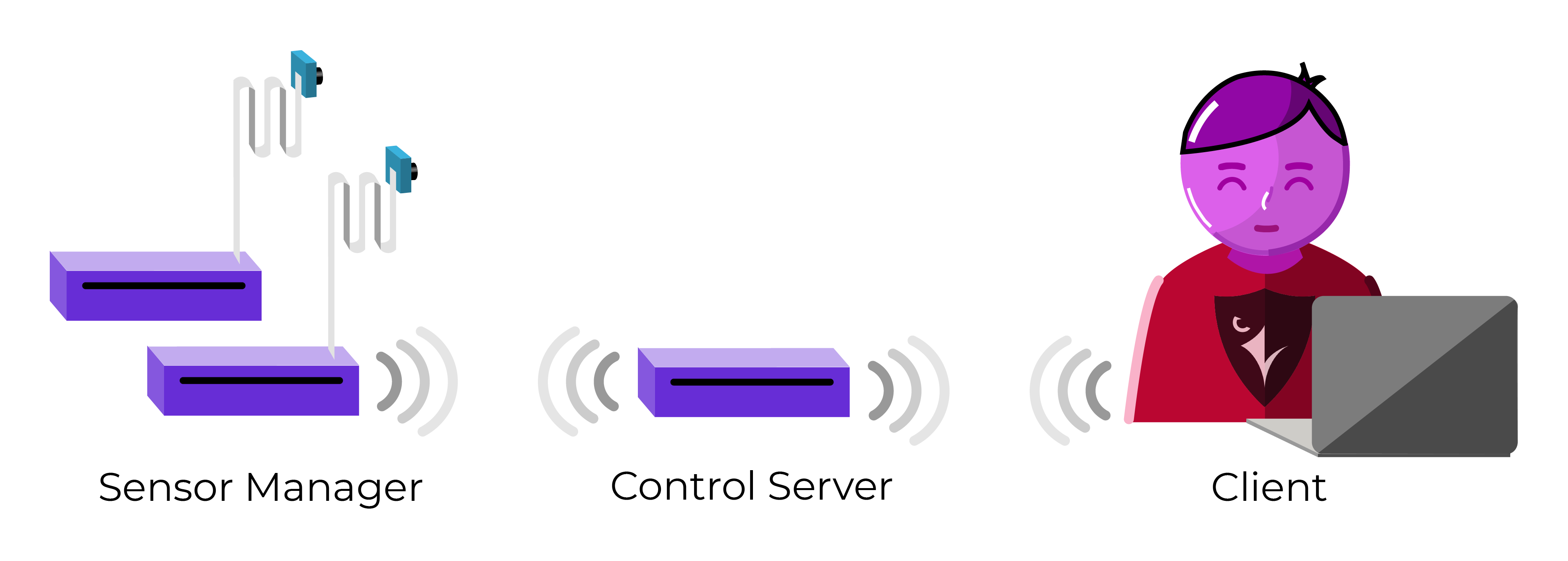
Traditionally, analysis of experimental data has often performed manually using data collected from few devices. However increasingly advanced machine-learning models allow and often require data from more sources. In animal-models, a growing number of open-source projects like DeepLabCut, SiMBA, and DeepSqueak are capable of consuming multiple types of data from multiple sources. This revolution in data-analysis is driving new types of research and is becoming increasingly deployed and relied on by groups around the world. However many labs struggle to adapt to new data collection requirements such as simultaneous collection from multiple cameras as well as other sources such as audio and EM signals.
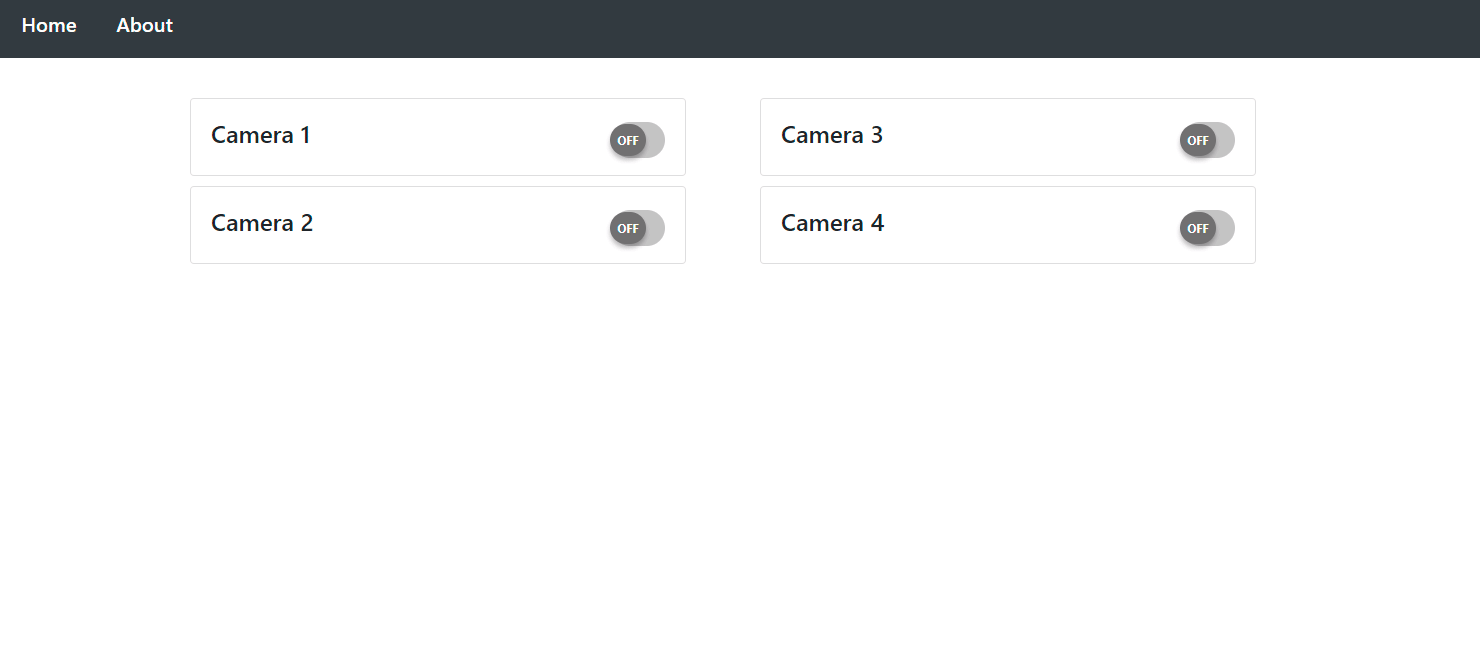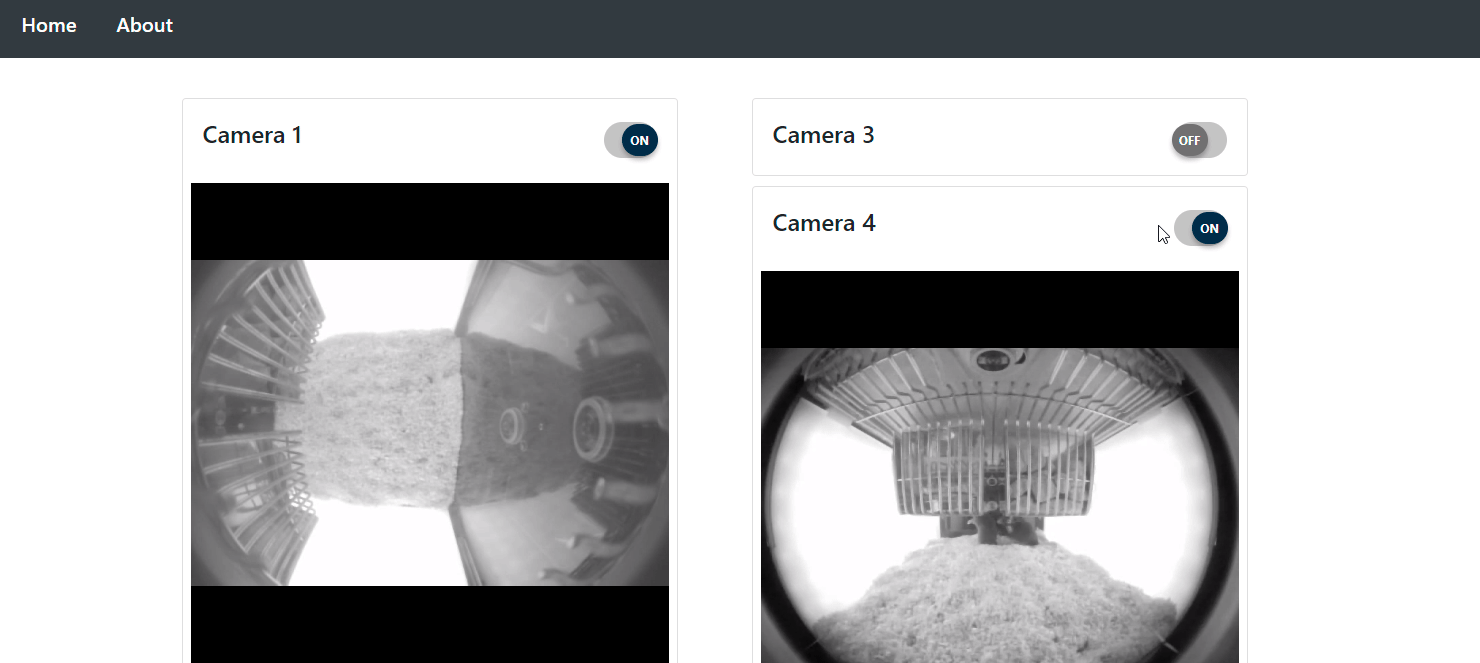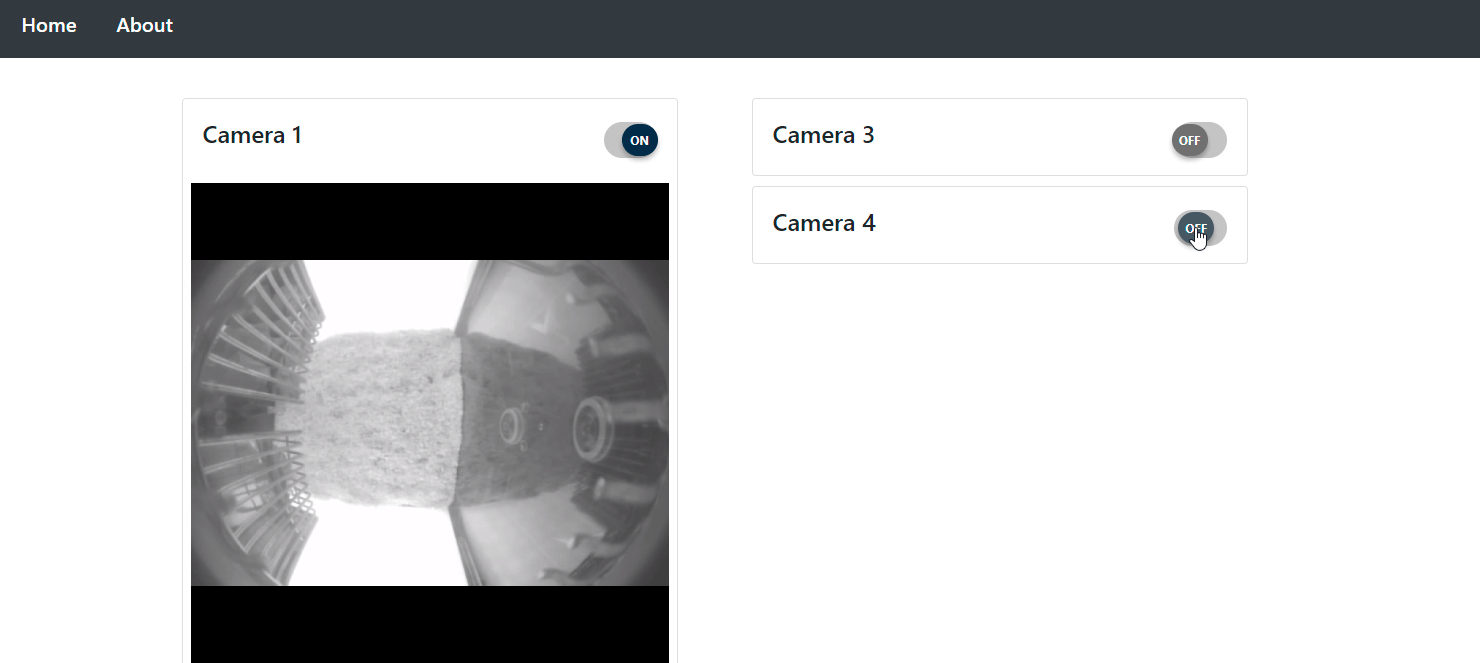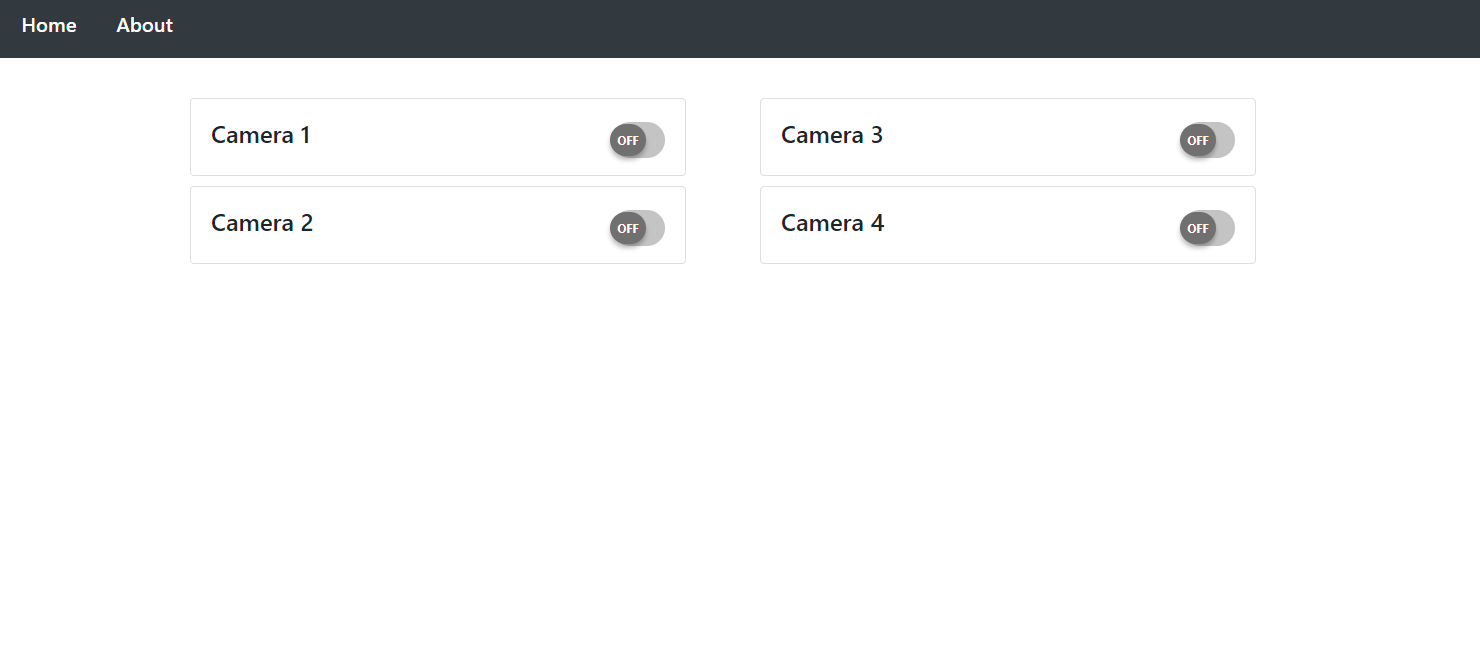
This project creates a synchronized data collection framework that can connect to any device capable of providing a data-stream. It provides web-access, which allows remote live-data viewing and control from authenticated users.
- Reproducibility: improved internal experiment documentation and packaging that encourages open-data practices.
Recent meta-research articles on scientific reproducibility have repeatedly singled out life-science domains as being acutely impacted. This project provides a streamlined interface to create structed experimental data and metadata in order to:
- Improve reproducibility by preventing the loss of important information caused by researchers leaving the team, time-drift of experimental practice, and simple forgetfulness.
- Passively encourage data sharing by storing data in popular open-data formats.
- Long Term Usage: maintainability and scaling.
Many research labs have explored custom data-collection solutions and are now facing a maintainability issues. The most frequent causes of this are that:
- Coding ability of life-science faculty and graduate students is highly variable. After the creator of a data-collection system leaves the group (ex. graduates or moves on to other research), labs struggle to modify previous code and are forced to reinvest time into a new system.
- Code is often written to solve a specific research problem and cannot be easily adapted to evolving requirements or other teams.
This project provides an open-source framework and long-term development, customization, and community support.

Log in or sign up for Devpost to join the conversation.