-

Recruiter / Candidate Login Page
-
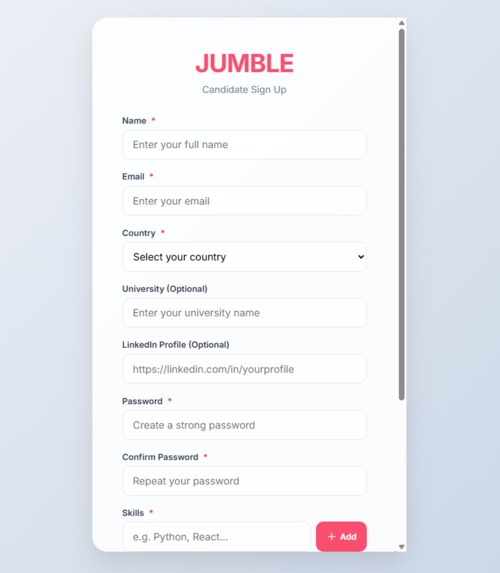
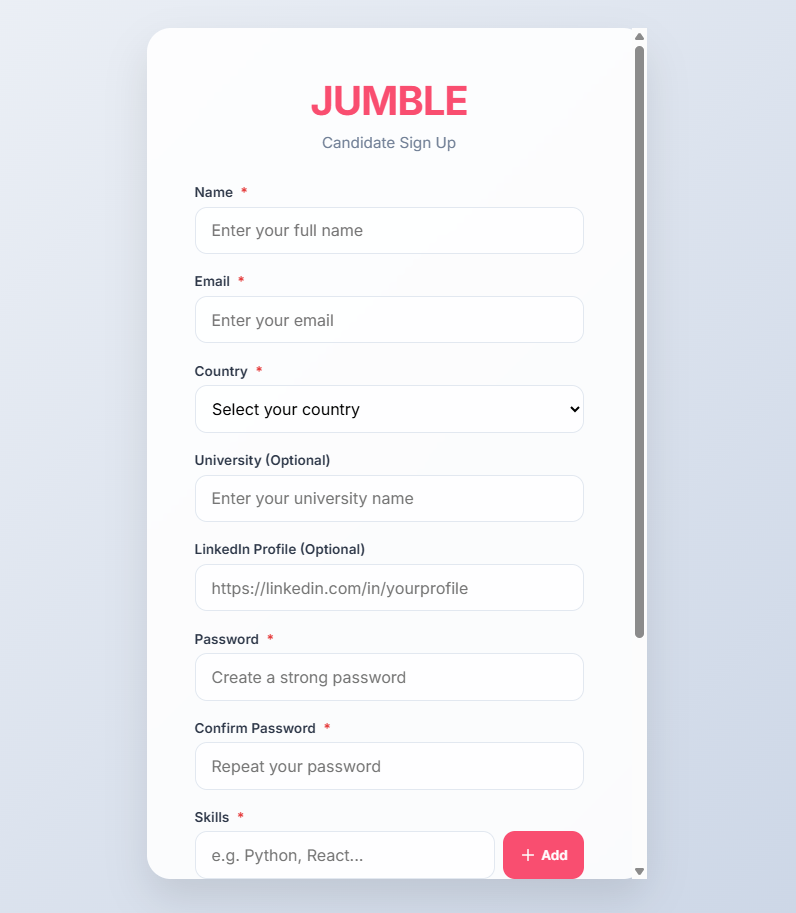
Candidate Sign Up Page
-
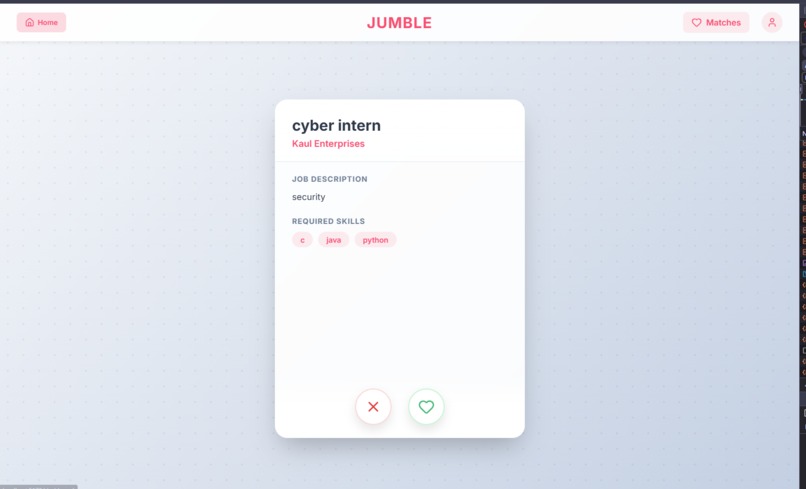
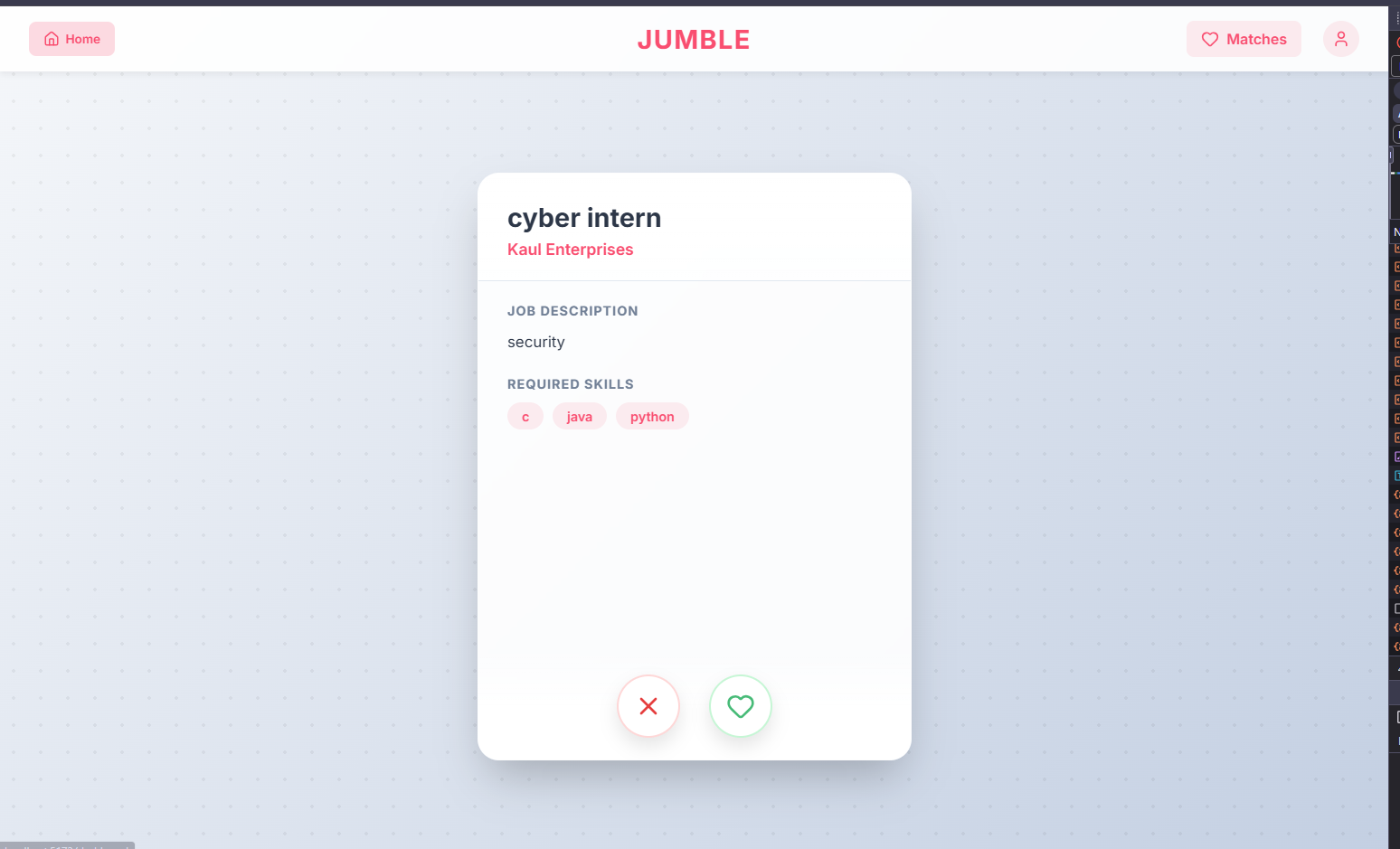
Suggested Jobs for Candidates
-
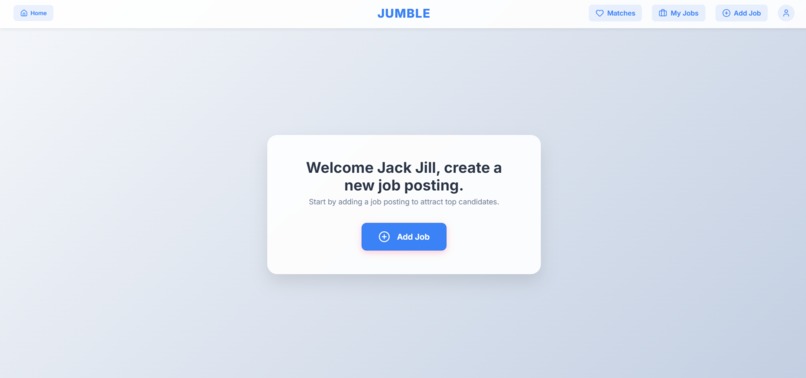
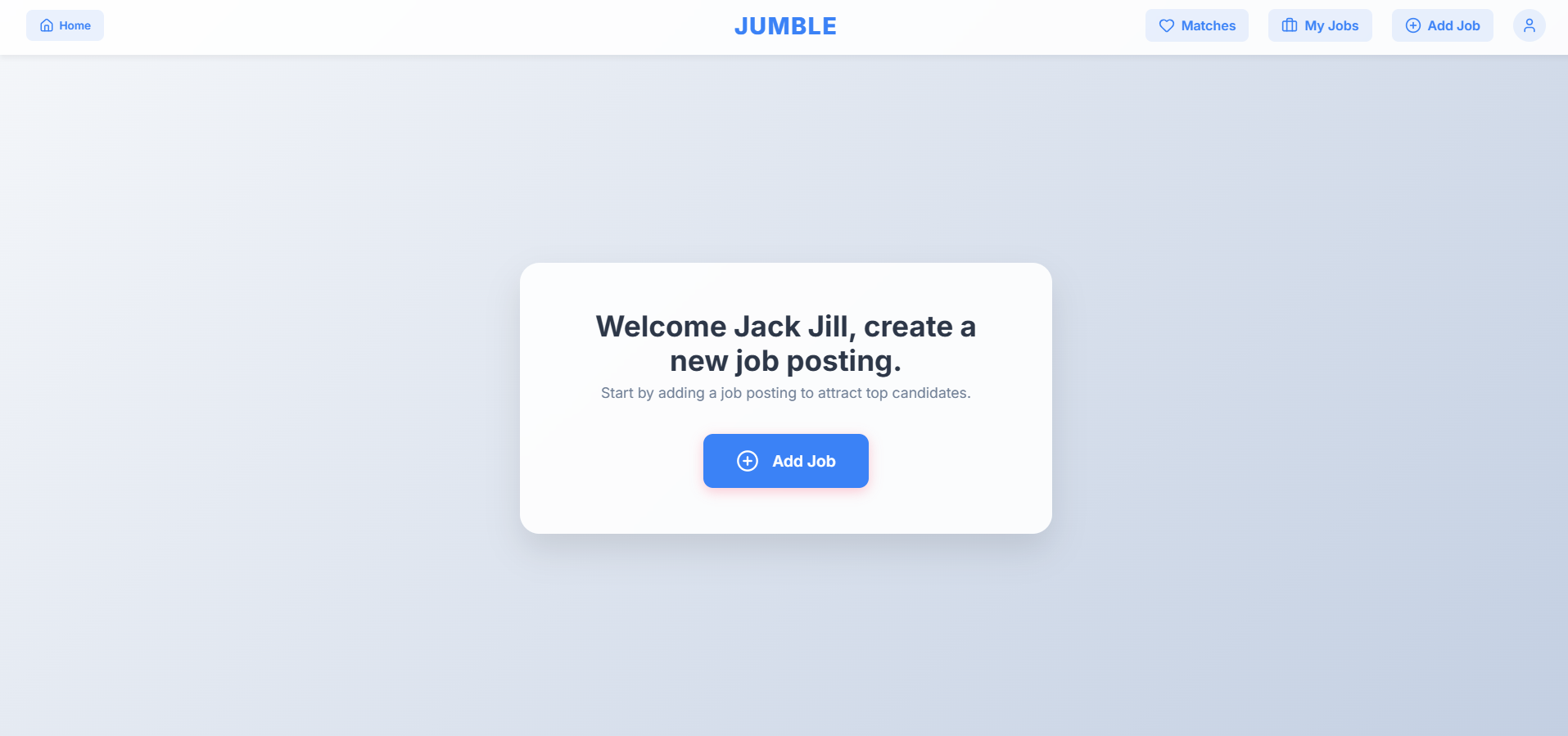
Recruiter Landing Page post login
-
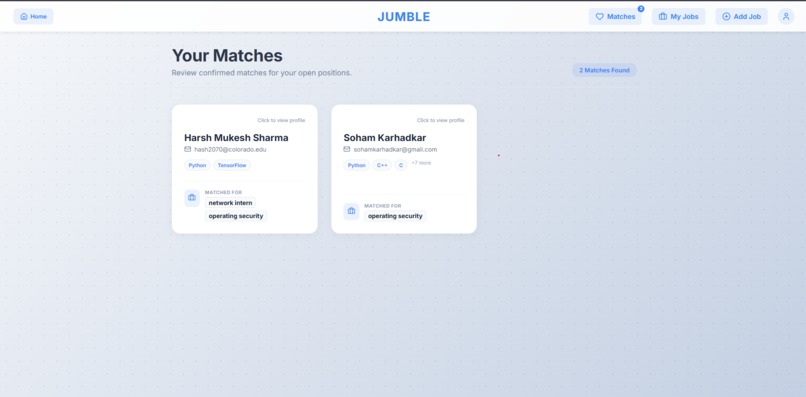
Suggested Candidates for Recruiter
-
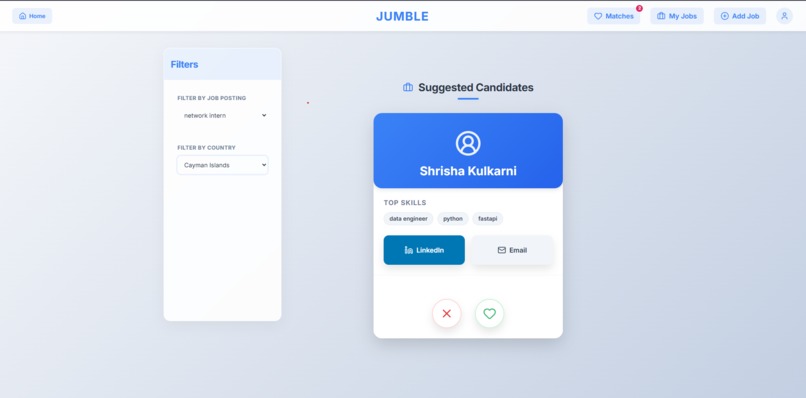
Suggested Candidates filtered

Inspiration The inspiration for JUMBLE was born out of pure exhaustion. Every software engineer knows the drill: you format your resume perfectly, write a customized cover letter, and send your application into the void. The recruitment pipeline is fundamentally broken. It is asymmetric. Candidates spend hours applying, while recruiters are overwhelmed by a deluge of thousands of unqualified applicants, resulting in a system where meaningful interaction is incredibly rare. We wanted to build something that strips away the fluff. What if hiring wasn't about forms and cover letters? What if it was about instant, mutual, high-signal intent?
What it does JUMBLE is Bumble for hiring. We gamify the grueling application process by letting candidates and companies rapidly swipe left or right on tech stacks and salary expectations. We use a Python Machine Learning backend to parse and surface the most compatible resumes and jobs to the top of the stack. When our high-speed Match Engine detects mutual interest (a reciprocal right-swipe), it instantly builds a connection, ensuring you only talk to people who actually want you.
How we built it JUMBLE is built on a modern, distributed micro-service architecture:
The Client: A highly interactive Single Page Application (SPA) using React and Vite, with dedicated dashboards for Candidates and Recruiters. The Intelligence Layer (ML): We integrated Python routines that parse features and prioritize mathematically compatible profiles. The User-Job Monolith: A Spring Boot backend that manages user authentication via JWT, Recruiter Job Posts, and Candidate Profiles. The Swipe Engine: A dedicated Spring Boot micro-service designed to handle high-throughput gamified interactions entirely decoupled from the monolith.
Distributed Database Alignment: We initially tried saving all swipes and matches strictly to Redis for speed. However, we quickly realised that losing match data due to an in-memory flush is catastrophic. Refactoring our Java models and repositories mid-hackathon to dynamically write temporary data to Redis and permanent data to MongoDB without breaking the API contract was a high-pressure challenge.
MatchDetectionService asynchronously queries this cache. The moment a mutual match is generated, the Swipe Engine seamlessly switches contexts and persists the final Match object permanently to our MongoDB Atlas cluster via Spring Data Mongo.
What we learned We learned that micro-services are a double-edged sword. While they allowed us to build an incredibly fast, decoupled Swipe Engine, the overhead of managing dual databases (Redis + MongoDB) and orchestrating network traffic taught us massive lessons in system design and data resilience. We also learned how to leverage Python ML scripts directly within a broader Full-Stack ecosystem.
What's next for JUMBLE For the future scope of JUMBLE, our primary focus is expanding the platform's automation personalisation and fortifying its architecture to handle enterprise-grade scale. We plan to introduce Dynamic Cover Letter Generation; before a candidate fully applies or right-swipes on a role, the system will instantly synthesise their parsed resume features and the specific jobId's description to generate a highly targeted, custom cover letter that is automatically attached to the candidate's application profile for that specific role. To support the massive compute load and data volume required to generate these documents at scale during traffic spikes, we will also evolve our backend architecture by introducing Apache Kafka for asynchronous, high-throughput event streaming between our microservices, and migrating our containerised deployment from Docker Compose to a fully orchestrated Kubernetes cluster to enable rapid horizontal auto-scaling.
The Role of Google Antigravity Building a polyglot, widely distributed microservice architecture from scratch in just 24 hours is a colossal technical challenge, and we relied heavily on Google Antigravity to make it possible. Antigravity served as our core AI Pair Programmer and Systems Architect throughout the entire weekend. Rather than just acting as an autocomplete engine, Antigravity actively helped us make critical structural decisions—such as designing the Hybrid Database Architecture that safely decoupled our high-throughput Redis swipe actions from our persistent MongoDB match records. When we hit severe roadblocks, like undocumented Spring Boot port collisions and MongoDB local deployment failures, Antigravity autonomously read our active terminal logs, parsed our Maven dependencies, and injected the exact custom configuration parameters needed to keep our backend online. It autonomously generated our foundational Java models, database repositories, and the core algorithmic logic of the MatchDetectionService, serving as the invisible engineering backbone that allowed us to focus entirely on product vision and ML execution.
Built With
- antigravity
- docker
- html/css
- java
- javascript
- machine-learning
- mongodb
- python
- react
- redis
- spring
- springboot
- vite





Log in or sign up for Devpost to join the conversation.