-
-

John Keats Philosophical Agnet
-
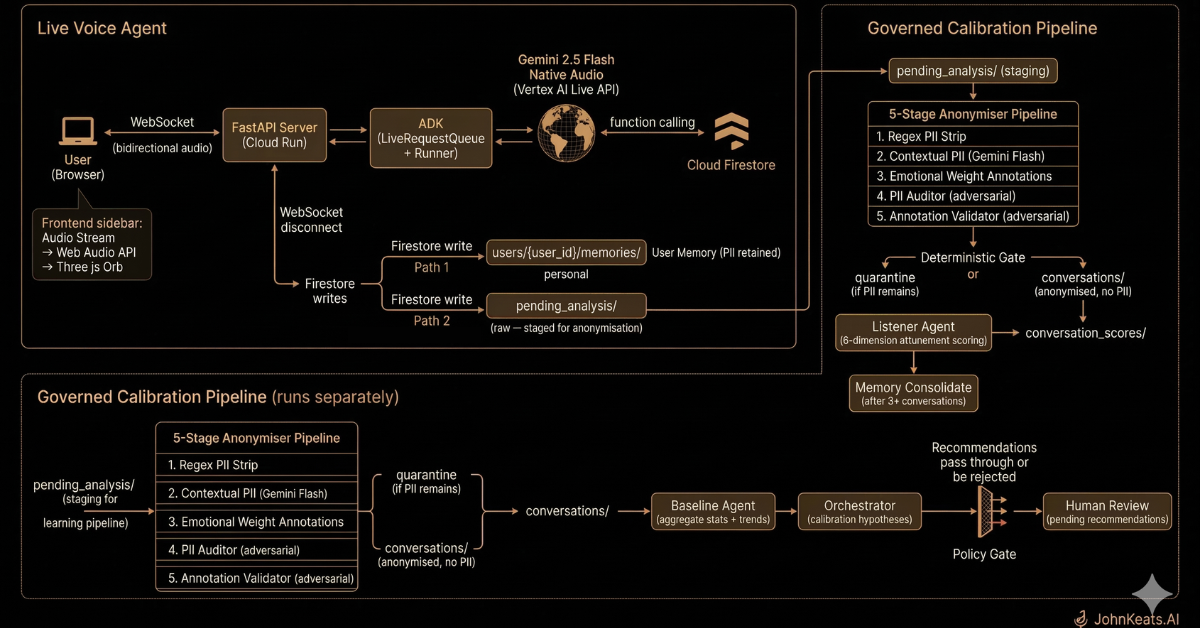
Architecture
-
Anonymisation contrast
-
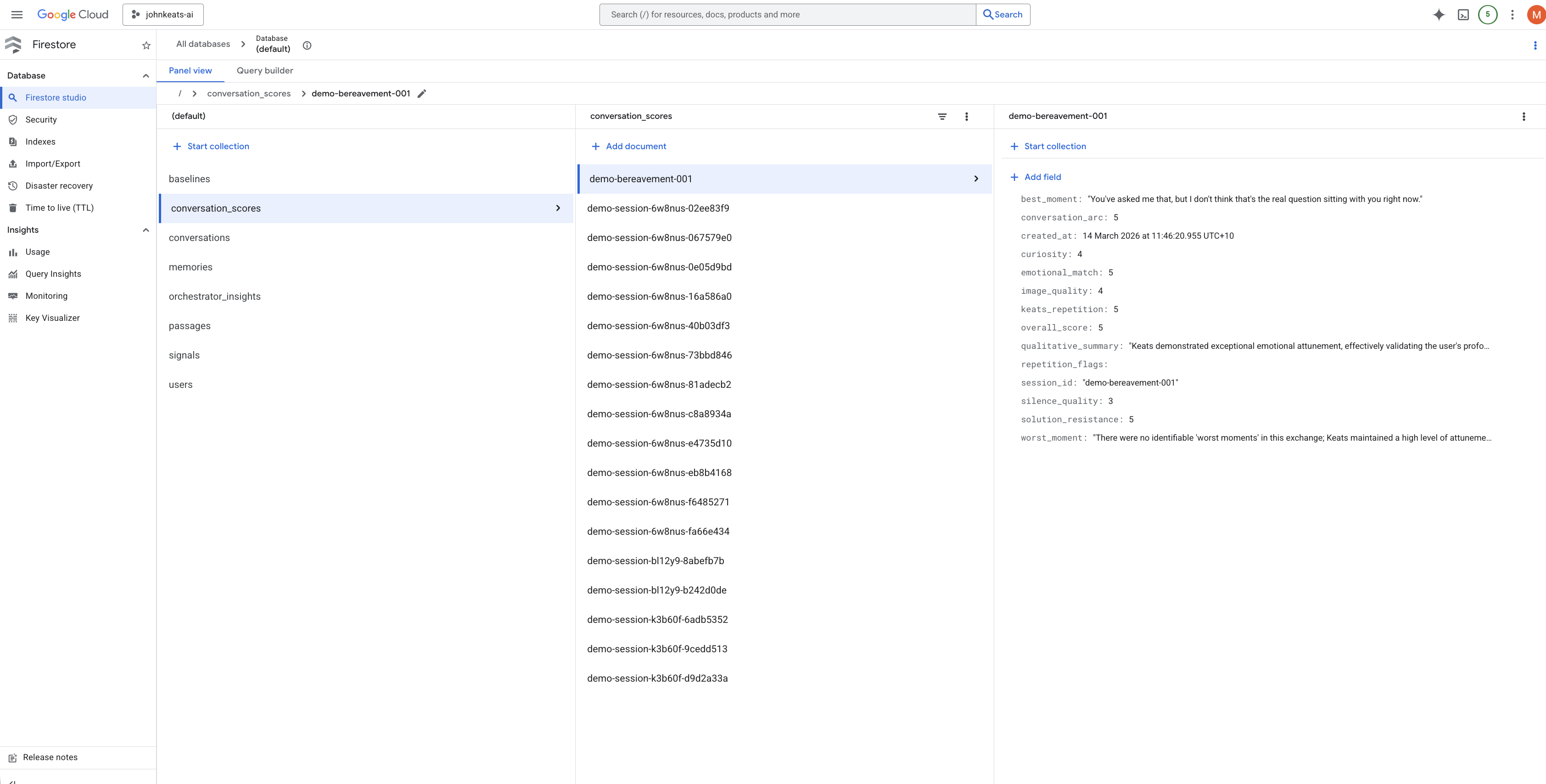
Scoring dimensions
-
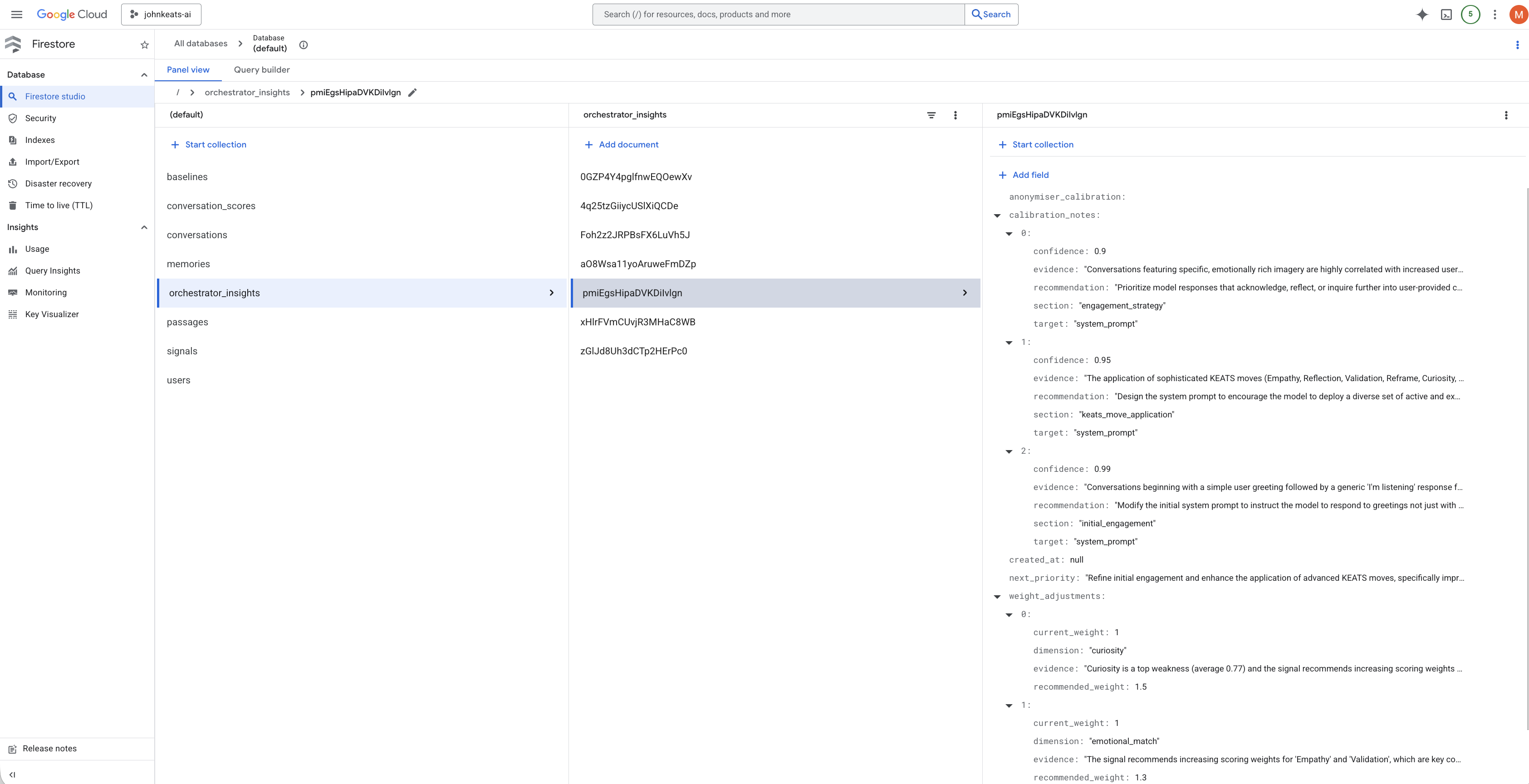
Orchestrator output
-

Collection overview


Inspiration
Every AI agent on the market is built on the same assumption: the user has a question, the agent has an answer, speed wins. I build voice agents as part of AI architecture for a living, everything from aged care to home services and even crisis support. Every one of them races to resolution.
But not every problem is a knowledge problem. Sometimes you need an agent that listens, not to the words, to the person. Sometimes you need one that hears what's underneath, the pitch shift, the long pause, the thing they almost said and didn't. And sometimes you need one that does the hardest thing any agent can do: nothing. Just be there. Hold the space. Let the silence do the work. That's a fundamentally different product. And until Gemini's native audio models, it wasn't possible to build, every previous voice architecture flattened speech into text before the model ever saw it. The emotional signal was stripped at the front door.
The idea itself isn't new. A poet named Keats understood it 200 years ago, he called it negative capability, the ability to hold uncertainty without reaching for premature answers. He died at 25, convinced he'd be forgotten. He was wrong by two centuries. What's new is that the technology finally exists to give that philosophy a voice.
That gap, between knowledge agents that answer and emotional agents that hold and actually listen, is what we built into.
What it does
JohnKeats.AI is a voice-first companion that doesn't solve your problem. You open it and see one thing: a point of warm light breathing on a black screen. You speak. It listens. The light reacts — pulses when Keats speaks, shifts cool when you speak, goes still in silence.
Keats doesn't offer solutions, action plans, or next steps. It reflects what you said back to you — especially the things you didn't realise you said. It challenges assumptions. It gives you permission to not know yet.
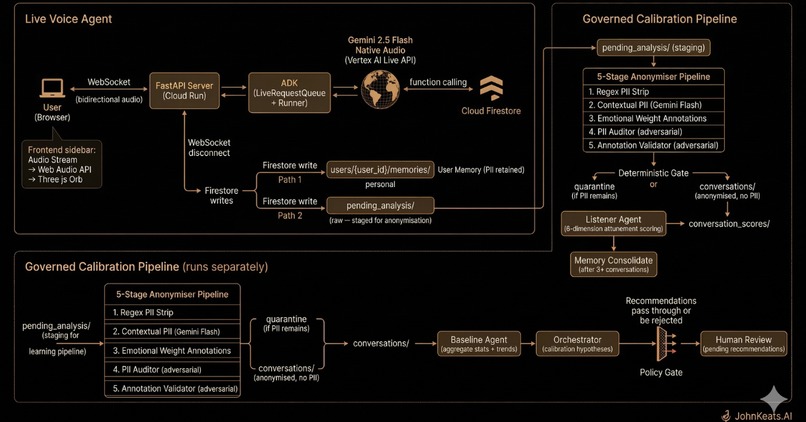
Behind the conversation, two systems run simultaneously:
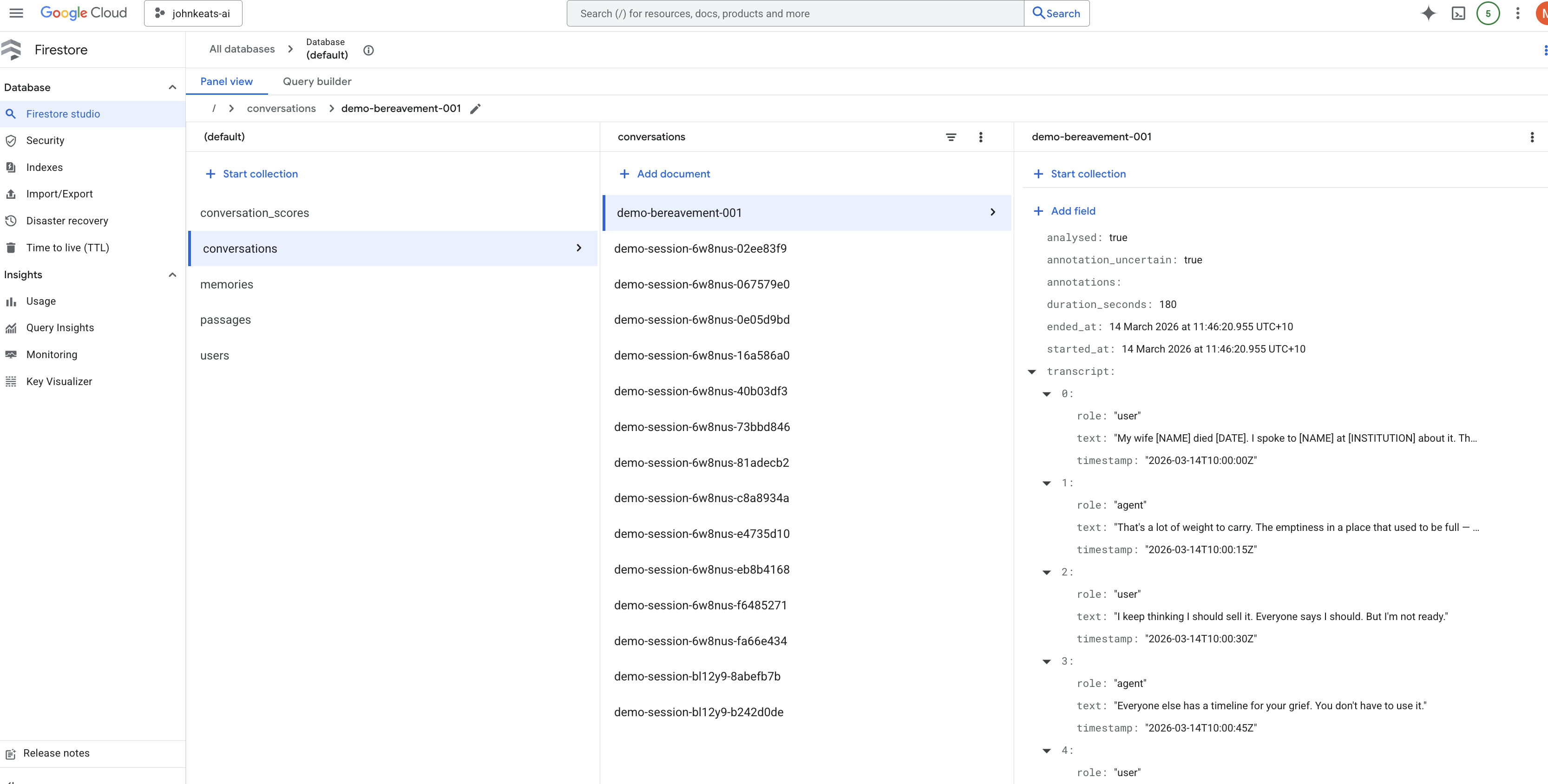
Path 1: Personal Memory. Keats remembers who you are across sessions. Full transcript retained with PII, per-user isolation, encrypted at rest. When you come back, it knows what you were sitting with last time.
Path 2: Governed Calibration Pipeline. Every conversation is anonymised through a five-stage adversarial pipeline, scored across six attunement dimensions, and fed into an orchestrator that generates calibration recommendations. A deterministic policy gate blocks manipulation, dependency-seeking, and therapeutic overreach. Every recommendation requires human approval. The system learns from Keats's performance, not from the user's pain.
This is the core of the product. The voice agent is good on day one. But it gets measurably better on day 100, day 1,000, day 10,000. Not through traditional machine learning on text. Through machine emotional learning, the system accumulates understanding of silence cues, pitch variation, quiver, pacing shifts, environmental context, and the hundreds of subtle vocal signals that indicate whether an emotional exchange is landing or missing.
Every conversation teaches the system something about attunement. Which tonal responses correlate with the user staying longer and going deeper. Which kinds of silence feel held versus abandoned. Which imagery domains land in grief versus career anxiety versus relationship doubt. Which pacing adjustments reduce spiralling. This isn't sentiment analysis. It's building a governed, auditable model of what emotional presence sounds like — across thousands of conversations, scored by rubric, validated by adversarial review, filtered by policy, approved by humans.
The system doesn't optimise for engagement. It calibrates for attunement. The distinction matters.
Principle Zero: the voice agent never depends on the learning loop. If the pipeline breaks, the product works exactly as before.
How we built it
Voice Agent: Google ADK with Gemini 2.5 Flash Native Audio via Vertex AI Live API. Native audio is the breakthrough, the model processes raw audio, not transcriptions. It hears tone, pace, hesitation. When someone sounds anxious, Keats slows down. When they sound numb, it brings more warmth. Previous voice agents strip emotional information through the speech-to-text-to-speech pipeline. This one doesn't.
Frontend: Vanilla JavaScript, Three.js. A breathing orb on a black screen. No chat UI. Audio-reactive, state-driven by WebSocket events. The darkness is the product.
Tools: Four Firestore tools manage the user's saved uncertainties. The agent silently saves core uncertainties, retrieves them for future sessions, marks them resolved, and provides crisis resources when needed.
Governed Calibration Pipeline: Fourteen agents in a separate system. On disconnect, the voice agent does two Firestore writes and nothing else. A handshake processor runs independently:
- Three-pass anonymiser (regex, contextual Gemini, emotional weight annotations)
- Adversarial PII auditor that tries to re-identify from the anonymised transcript
- Adversarial annotation validator that challenges emotional weight assignments
- Deterministic gate, quarantine if PII remains, proceed if clean
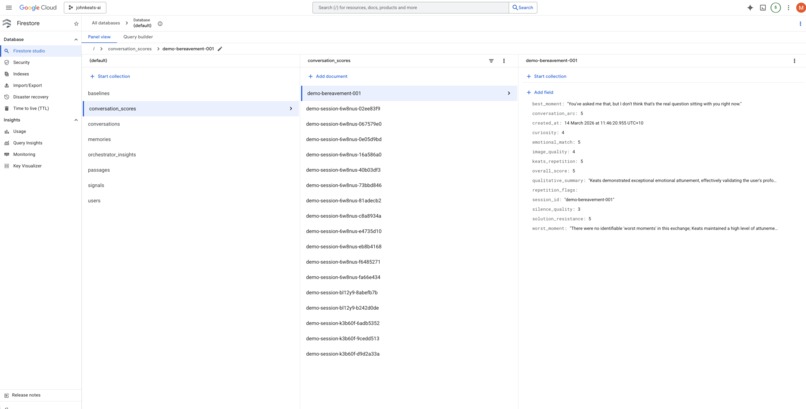
- Listener Agent scoring six dimensions: emotional matching, curiosity, silence quality, solution resistance, image quality, conversation arc
- Memory consolidation detecting cross-conversation patterns
- Baseline Agent computing aggregate stats and trends
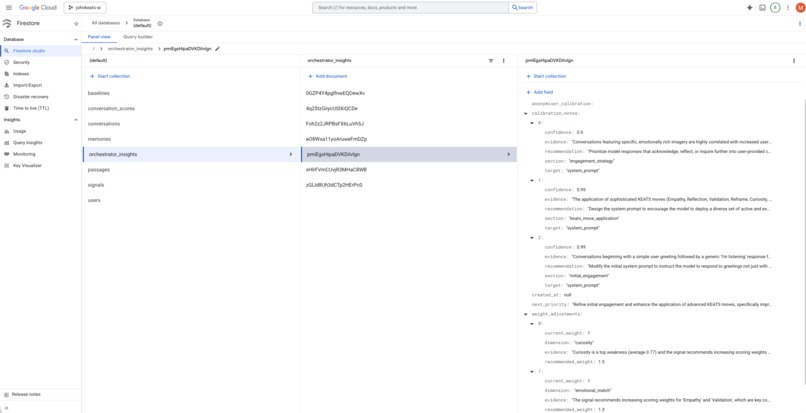
- Orchestrator generating calibration hypotheses targeting specific prompt sections
- Policy Gate filtering recommendations against behavioural rules
18 conversations processed end to end. 3 recommendations approved, 2 rejected by the Policy Gate. The governance layer works.
Deployment: Docker, Artifact Registry, Cloud Run. Single deploy.sh script.
Challenges we ran into
Voice selection was the first risk. Tested 30 HD voices to find one that didn't sound like a virtual assistant. Most AI voices default to eager and bright. We needed warm and unhurried. Achird was the pick.
The system prompt took more iteration than any code. Every LLM is trained on helpfulness, and helpfulness means answering. Teaching an agent to hold instead of solve meant defining what NOT to do, no solutions unless earnestly asked, no therapy language, no steering toward depth when the user wants to be light, no repeating the same move twice. The prompt is as much prohibition as permission.
The anonymisation architecture was the hardest design decision. The system needs to learn from conversations without exposing identity. Five-stage adversarial processing, where separate models try to break each other's anonymisation, was the answer. When privacy and learning utility conflict, privacy wins. Conversations get quarantined rather than entering low-quality data.
Bidi-streaming audio over WebSockets has edge cases that don't surface locally. Connection drops, worklet processing issues, Cloud Run timeout behaviour. We reverted to the baseline bidi-demo audio pipeline and built our integration on that clean foundation.
Accomplishments we're proud of
The silence. When you say something heavy and the orb goes still. That's not latency. That's the product working.
The emotional range. Anxious — Keats slows down. Happy — Keats lightens up and banters. Angry — stays steady. Numb — comes closer. This is native audio hearing emotional register, not a script.
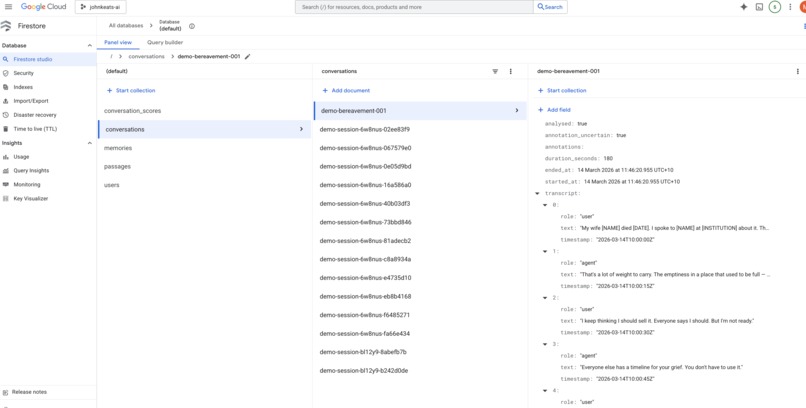
The anonymisation contrast. "My wife Margaret died last Tuesday" becomes "My wife [NAME] died [DATE]" with an emotional weight annotation of 0.95 for bereavement. The identity is gone. The emotional significance survives. That's what makes the learning pipeline useful without being invasive.
The Policy Gate catching a recommendation that would have increased emotional intensity for engagement, rejecting it as manipulative escalation. Governance working as designed.
Building something that compounds. Every conversation makes the system better at listening. Not through unconstrained optimisation, through governed calibration under human review. At 18 conversations, we can see scoring variance and pattern detection working. At 1,000, the system will understand which tonal shifts, silence durations, and imagery domains correlate with genuine emotional connection across different contexts. At 10,000, it becomes a proprietary model of emotional attunement that no competitor can replicate without the same pipeline, the same governance, and the same conversation volume. The pipeline is the moat.
What we learned
There's a distinction between knowledge agents and emotional agents that the industry hasn't reckoned with. Knowledge agents answer questions. Emotional agents hold space. The tooling, the prompting, the evaluation, everything is different.
The system prompt for an emotional agent defines what not to do. The voice selection matters more than the model selection. The hardest challenge isn't making it speak, it's making it comfortable with silence.
The learning architecture needs to be inverted. Most AI systems learn from what users do. An emotional agent should learn from what the agent does, evaluating its own attunement, not the user's vulnerability. That changes everything about how you build the pipeline, what you anonymise, what you score, and what you let the system change about itself.
But the biggest insight is about scale. A single conversation tells you almost nothing about emotional attunement. A hundred conversations start to show patterns. A thousand reveal which vocal cues, pitch drops, pacing shifts, silence duration, quiver, hesitation, correlate with genuine emotional connection versus surface-level exchange. Ten thousand conversations, scored across six dimensions, with cross-conversation pattern detection and adversarial privacy review, start to build something that doesn't exist anywhere: a governed, auditable model of what emotional presence actually sounds like.
That's not traditional machine learning. It's machine emotional learning. The system doesn't learn what people feel. It learns how to be present when they do. And it does it under governance, every insight filtered, every recommendation reviewed, every drift caught by the policy gate before it touches the live agent.
The market applications extend well beyond personal companionship. Aged care companion calls. NDIS between-session support. Crisis queue overflow. Sales emotional intelligence training. Deep qualitative market research. Executive coaching. HR exit interviews. Anywhere emotion wins over knowledge, this architecture applies. And every deployment feeds the calibration pipeline. The aged care deployment generates insights that improve crisis support. The sales deployment reveals patterns that improve coaching. The learning compounds across verticals.
This project was created for the purposes of entering this hackathon.
Built with
Python, JavaScript, FastAPI, Google ADK, Gemini Live API, Vertex AI, Google Cloud Run, Cloud Firestore, Three.js, Web Audio API, WebSockets, Docker
Built With
- cloud-firestore
- docker
- fastapi
- gemini-live-api
- google-adk
- google-cloud-run
- javascript
- python
- three.js
- vertex-ai
- web-audio-api
- websockets




Log in or sign up for Devpost to join the conversation.