-
-
Training of model and Evaluation of results
Inspiration
Owing to anonymity and lack of user accountability, online review platforms featuring user-published reviews are often polluted by spam, advertising, irrelevant or misleading remarks from people who have not visited beforehand. This influences potential customers' decision-making and thus negatively affects the targeted business. Furthermore, this lowers trust among consumers using the online review platform. Our inspiration was to build a system that systemically categorises, detects and filters such reviews, ensuring that only genuine and relevant feedback is surfaced to end users.
What it does
The system classifies reviews into four categories:
- 0 = Valid – genuine reviews about the location/service
- 1 = Spam/Ads – promotions, phishing, or irrelevant advertising
- 2 = Low Quality – very short or uninformative reviews
- 3 = Rant Without Visit – negative reviews where users admit they never visited
By identifying and removing reviews belonging to categories 1 to 3, the system improves the trustworthiness of online review platforms.
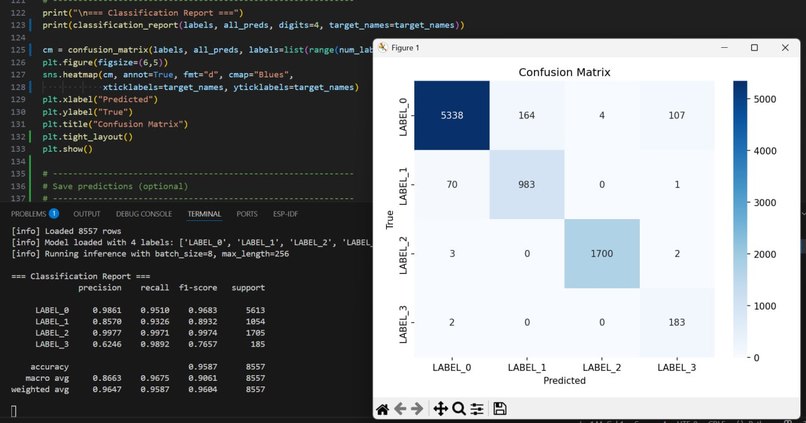
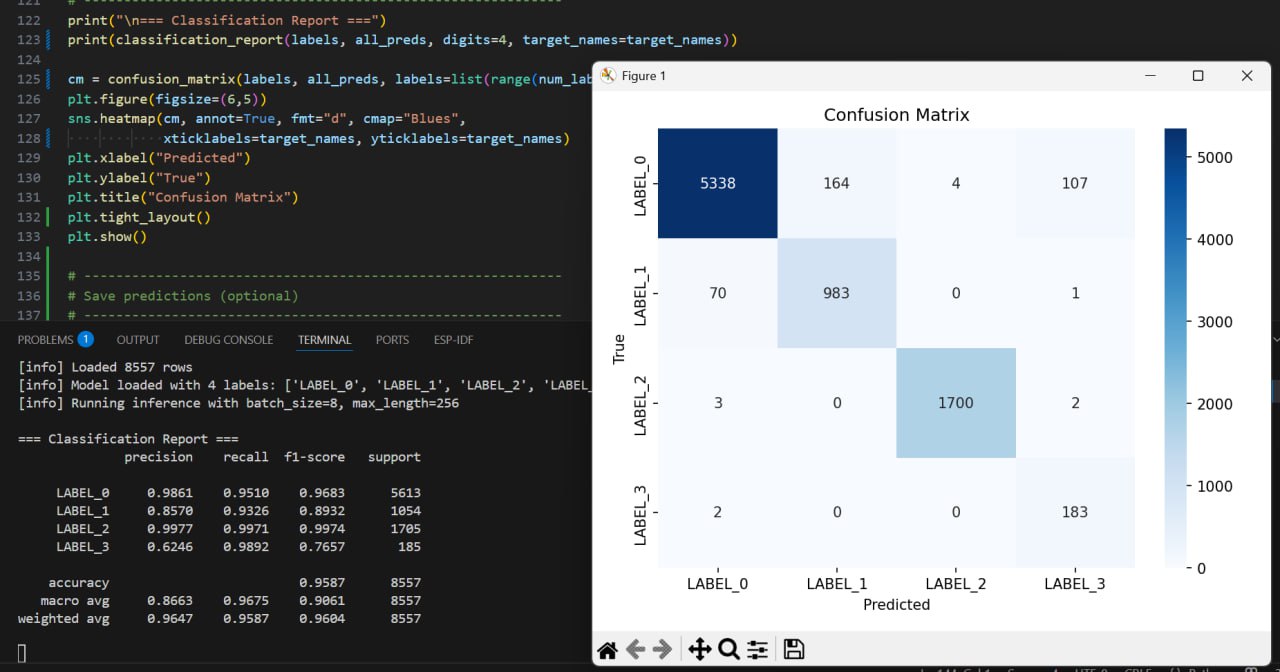
The final deployed model is DeBERTa-v3-small, fine-tuned to ~91% accuracy and a macro F1 score of ~0.85.
How we built it
- Dataset labelling:
Built from scratch with strict labelling policies. Human annotators labelled reviews, assisted by Google’s Gemma LLM model for faster classification. Predictions were validated and corrected to ensure quality.
- Hybrid preprocessing:
- Cleaning and label normalisation (0–3).
- Synthetic data augmentation for under-represented classes (spam, rants without visits).
- Dual feature extraction: TF-IDF (5,000 features, unigrams + bigrams) for classical ML, and Hugging Face tokeniser (max length 256) for transformers.
- Cleaning and label normalisation (0–3).
- ML/DL Models explored/roadmap:
- Random Forest on TF-IDF features (baseline).
- DistilBERT as a lightweight transformer.
- DeBERTa-v3-small as the final model, fine-tuned for 3–6 epochs with class weights.
Ensemble attempts (RF + transformer) showed little benefit.
- Random Forest on TF-IDF features (baseline).
- Development setup: Python, Google Colab with GPU acceleration, Hugging Face Transformers + PyTorch, Scikit-learn, Pandas, Datasets, Seaborn/Matplotlib, and Joblib for model persistence.
Challenges we ran into
- Dataset imbalance: Minority classes (spam, rant without visit) required augmentation to reduce excessive skewing of results.
- Ambiguity between classes: Low-quality reviews and rants without visits often looked similar (short, negative text without context).
- Ensemble models: Added complexity but delivered minimal performance gains.
- Time/Resource constraints: Fine-tuning multiple transformers and validating results required careful GPU resource management. To further bolster GPU speeds, we utilised Google Colab assets for increased computational power.
Accomplishments that we're proud of
- Designed a hybrid labelling process with human + Gemma-assisted classification to quickly build a medium to high-quality dataset.
- Achieved 91% accuracy and ~0.85 F1 scores, showing robustness across all four categories!
- Built a clear inference pipeline supporting CSV inputs and ouputting predictions and evaluation results.
- Deployed a Streamlit frontend for interactive use, making the system accessible beyond notebooks.
What we learned
- Quality is more important than quantity: A smaller, carefully labelled dataset provides stronger results than a larger, noisier one.
- AI as a complement, not replacement, to human work: Especially in the initial stages of training, adopting a Human-in-the-loop labelling combined with LLMs (Gemma) ensures clean, accurate labels. Early intervention is crucial as it improves downstream training stability and reduces error propagation during scaling.
- Synthetic data augmentation significantly improves performance on rare classes.
- Random Forest remains a strong, interpretable baseline, but cannot capture subtle semantics like transformers.
- DeBERTa-v3-small is consistently stronger than DistilBERT in nuanced classification tasks.
- Due to imbalanced classes, evaluation with macro F1 is crucial for fairness, ensuring minority categories are not ignored.
What's next for Real or Fake: Reviews Classification
We will continue to nurture our skills and knowledge in AI and ML through the course of our studies, applying classroom learning to real-world projects. Outside of the classroom, our future projects aspire to include active learning and feedback loops, such that our implementations can improve from user feedback and new data over time instead of relying on static information.
Built With
- datasets
- google-colab-(gpu)
- hugging-face-transformers
- joblib
- matplotlib
- pandas
- python
- pytorch
- scikit-learn
- seaborn
- streamlit


Log in or sign up for Devpost to join the conversation.