Inspiration
The job market today is flooded with listings and expectations that are often difficult to decode. Crafting a resume that matches real-world job descriptions is time-consuming and often misses crucial in-demand skills. We were inspired to build JobLens AI to bridge this gap — enabling anyone to instantly generate a custom-tailored, professional resume based on actual job trends using AI and MongoDB vector search.
What it does
JobLens AI is an AI-powered resume generator that:
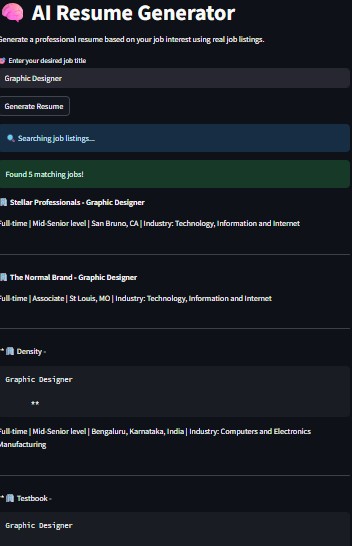
Takes a user’s desired job title as input
Performs semantic search across thousands of real job postings stored in MongoDB Atlas
Extracts the most relevant job descriptions
Uses Groq’s LLaMA-3 (or OpenAI) to generate a full professional resume Allows the user to preview and download their resume in PDF format
How we built it
MongoDB Atlas stores over 63,000 job records with precomputed sentence-transformer embeddings for vector similarity search.
We used sentence-transformers (MiniLM) to embed job descriptions.
Semantic search is powered by MongoDB Atlas's vector search + PyMongo with custom cosine similarity logic.
Resume generation is handled by Groq's LLaMA-3 70B or OpenAI's GPT models.
PDFs are generated dynamically using the fpdf library.
The app is built with Streamlit and deployed via Docker to Google Cloud Run with GitHub integration.
Challenges we ran into
🔐 Securely managing secrets like MONGODB_URI and GROQ_API_KEY in a cloud-deployed container
💥 Memory crashes on Google Cloud Run due to sentence-transformer models exceeding 512MiB limits
🧩 Ensuring Streamlit binds to port 8080 and plays well with Docker and Cloud Run
🔄 Cleaning and embedding the dataset to be usable for vector search took significant pre-processing
Accomplishments that we're proud of
🚀 Live deployed version of an AI agent system in production on Google Cloud
📄 Generated beautiful, tailored resumes with zero user input beyond a job title
🔍 Implemented real-time semantic search with MongoDB’s vector capabilities
🔐 Built a secure, end-to-end pipeline that works from ingestion → embedding → LLM generation → PDF download
What we learned
🧠 How to use MongoDB Atlas Vector Search with sentence-transformers and cosine similarity
📦 How to deploy full ML pipelines using Google Cloud Run + Docker + GitHub
💬 How to interface Groq's LLaMA-3 with external datasets to generate rich natural language outputs
📊 The importance of efficient embedding and cleaning pipelines when working with real-world job data
What's next for Joblens AI
💼 LinkedIn job scraping agent to pull live listings automatically
🧠 Add RAG-based experience generation tailored to job trends
🧑🎓 Let users upload their existing resume and get AI-enhanced versions
📈 Dashboard for job market trends, skill gaps, and recommendations
☁️ Deploy on Streamlit Cloud or Gradio Spaces for broader accessibility


Log in or sign up for Devpost to join the conversation.