-
-
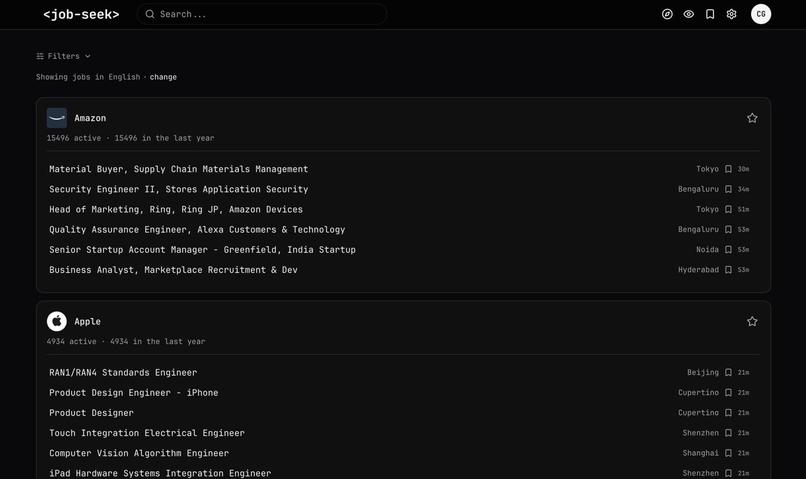
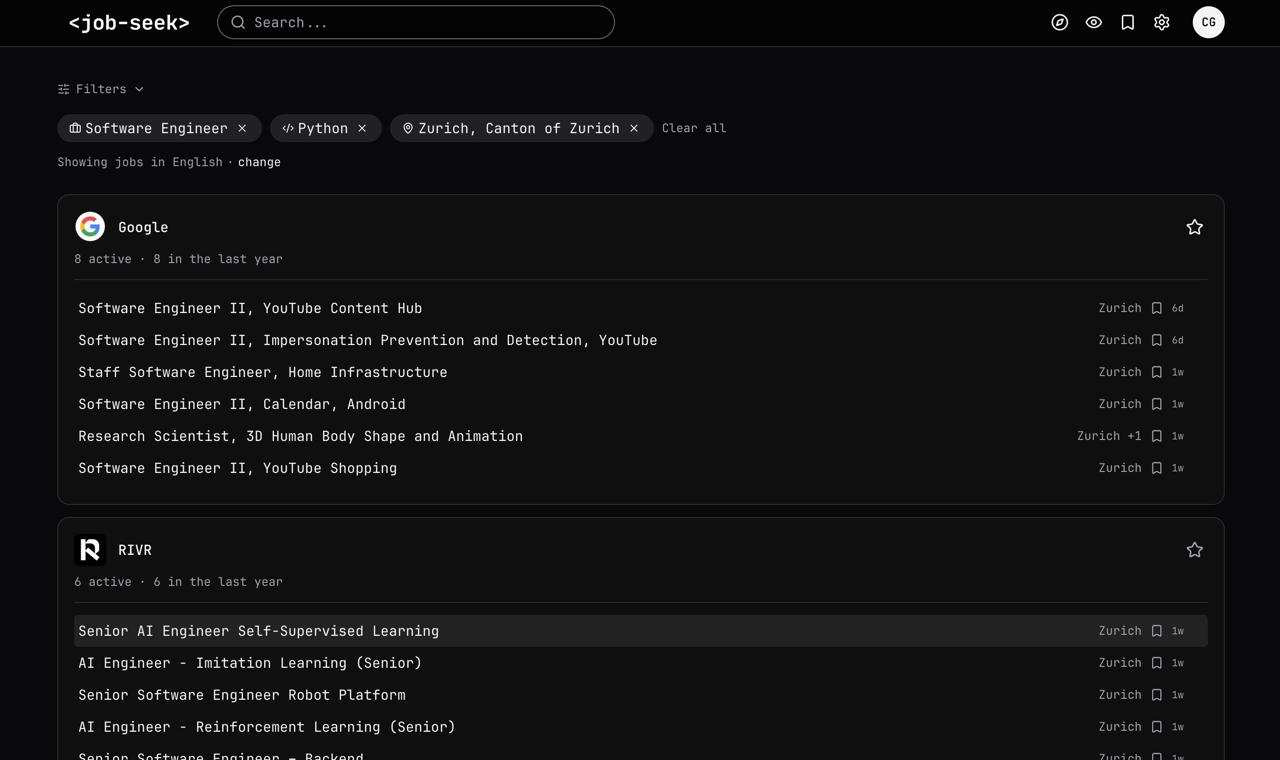
The main "explore" screen provides users with a glance at companies that hire for their role of interest
-
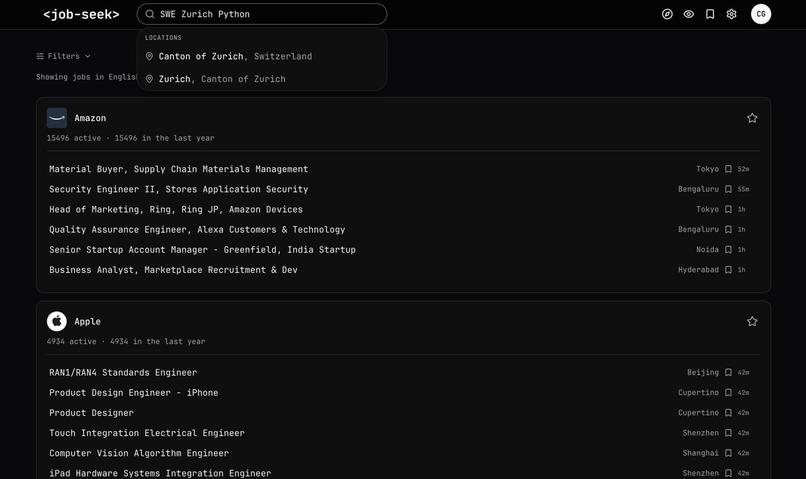
We enrich job postings with structured information using an LLM
-
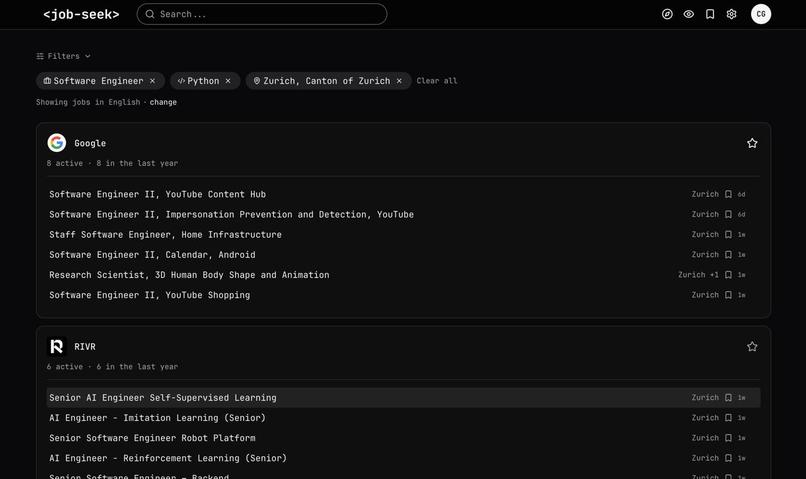
The search is done over the structured information to keep it precise and cheap
-
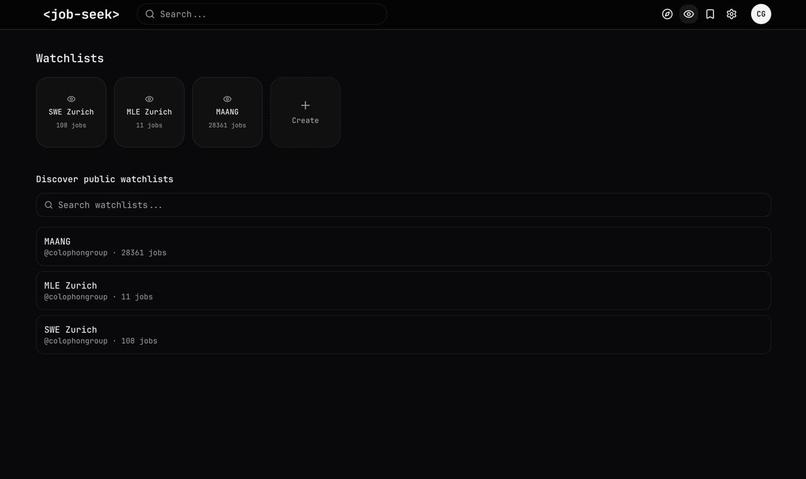
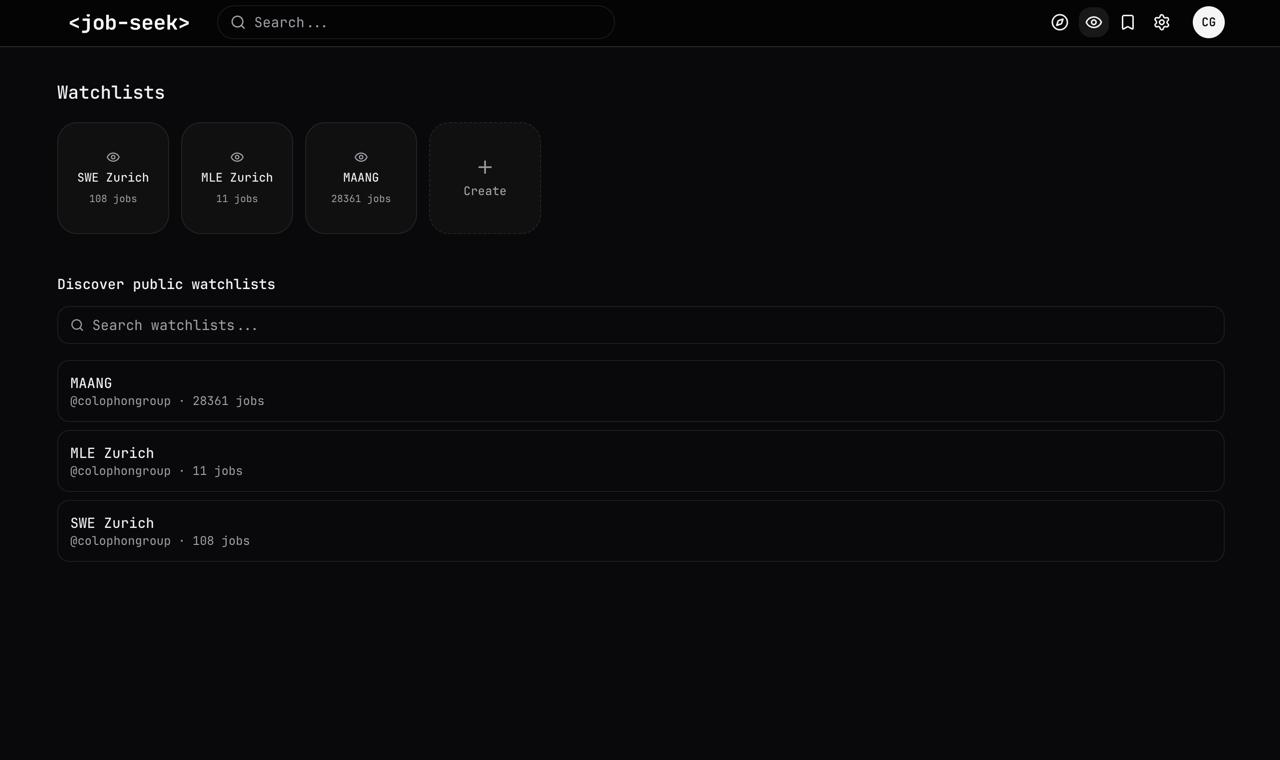
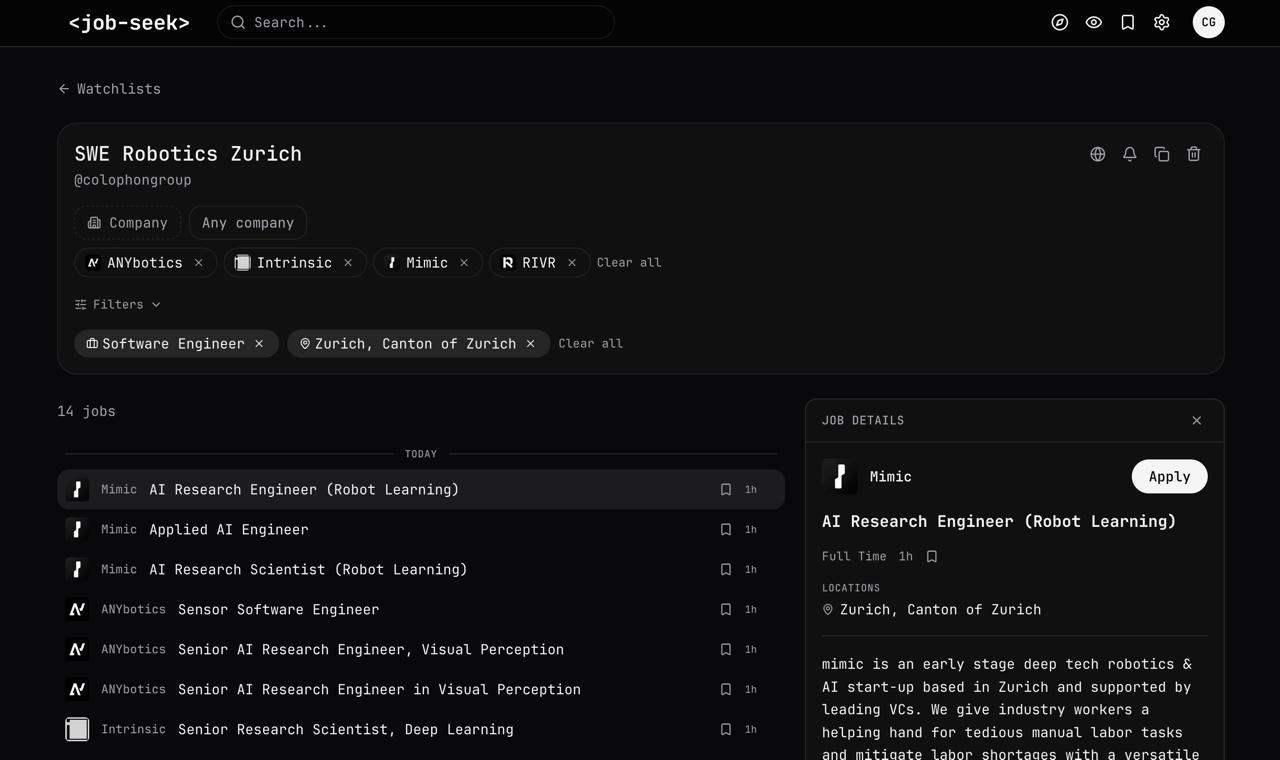
Users can share and discover "watchlists" – pre-set filters over an (optional) set of companies
-
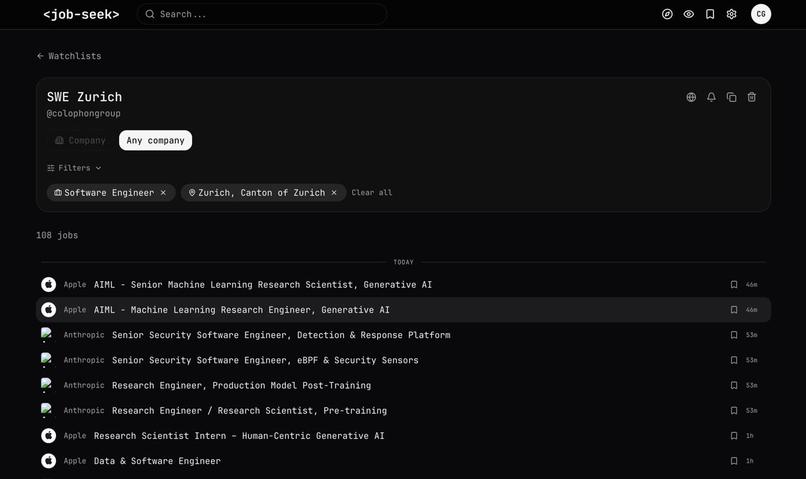
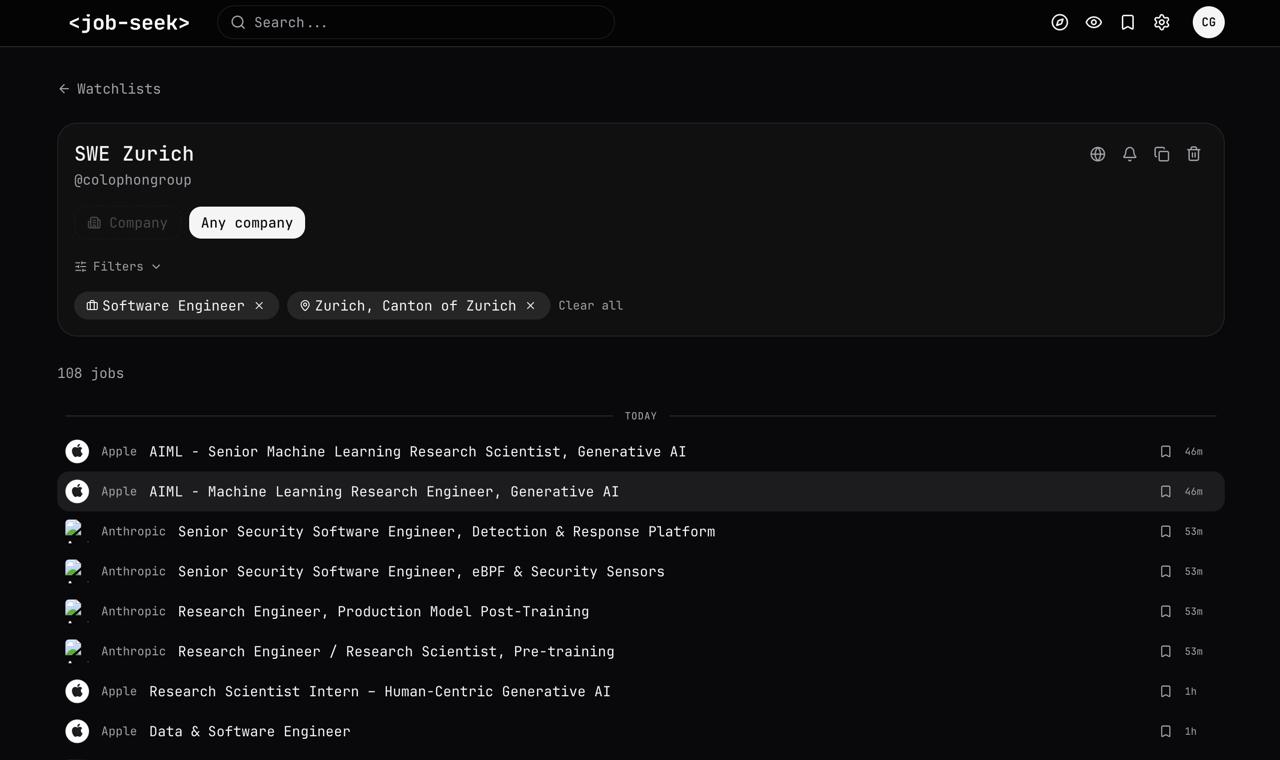
This is a familiar "job feed" UI users visit to catch up on new job postings
-
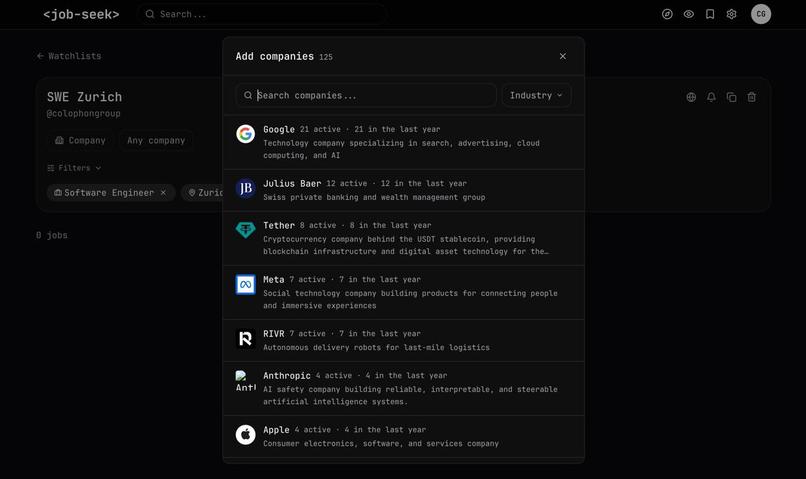
Users can change watchlists to fit their own goals
-
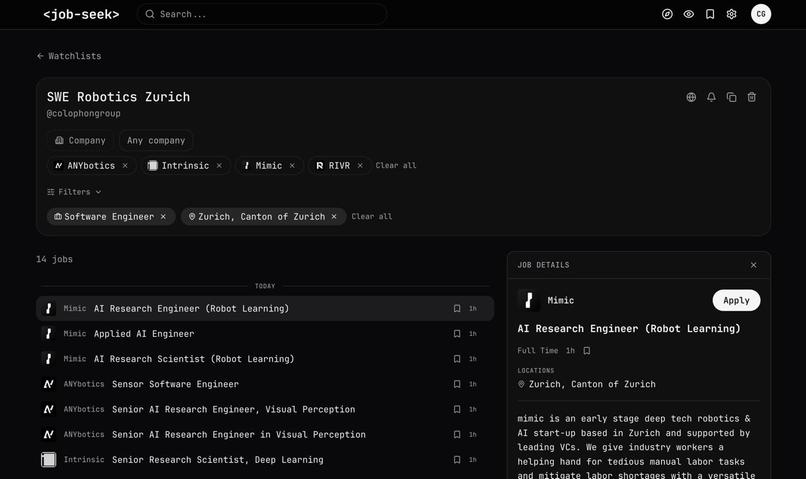
Fixing the set of companies allows for very targeted job search
-
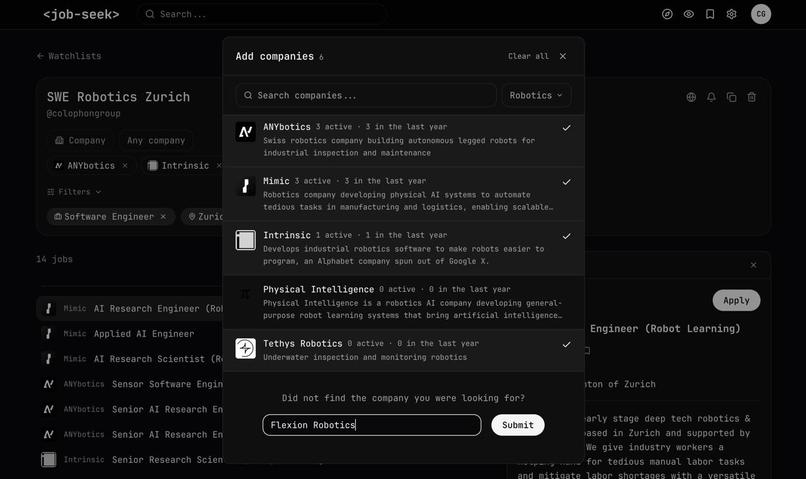
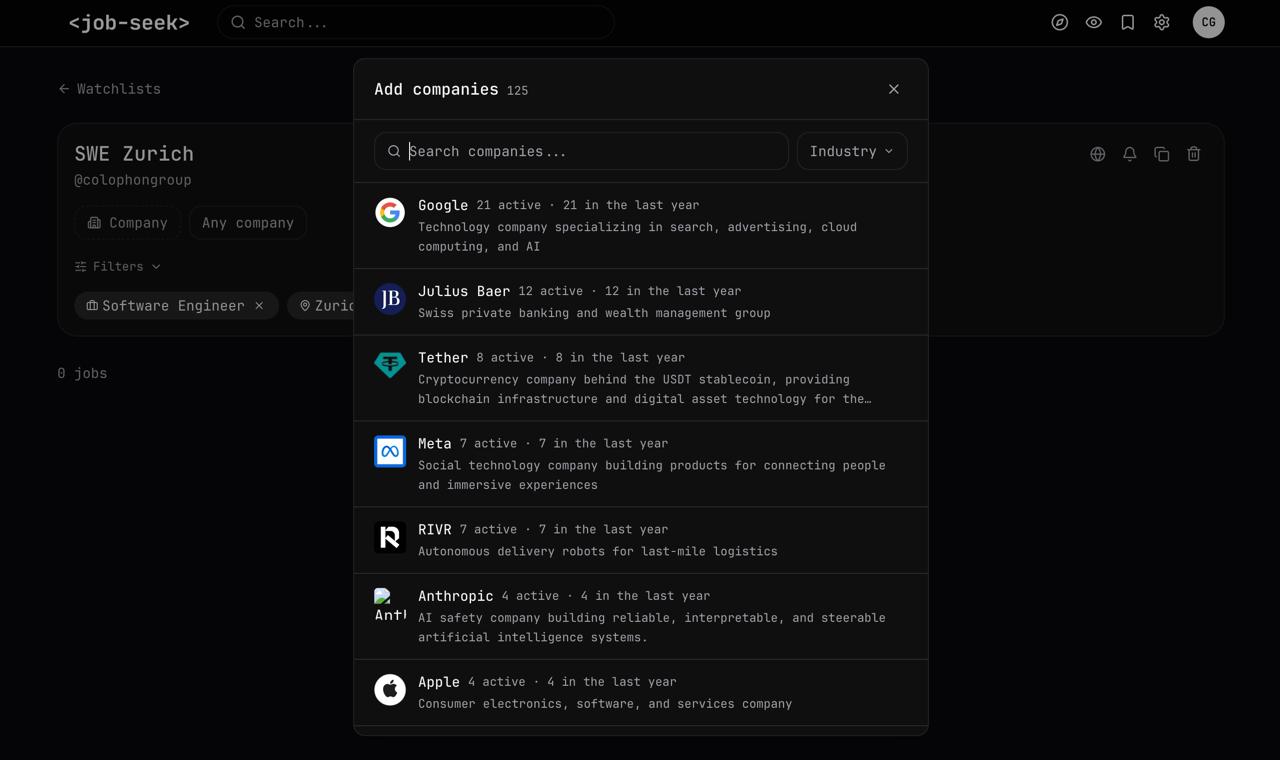
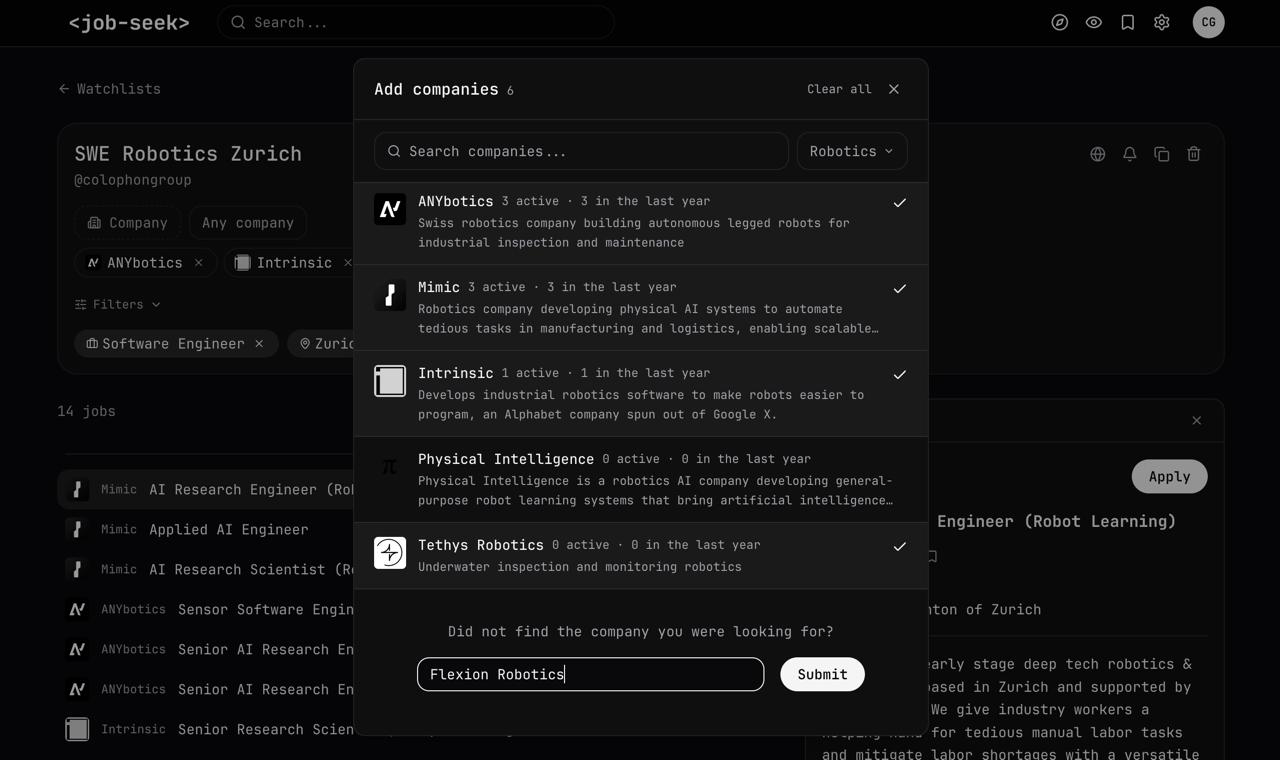
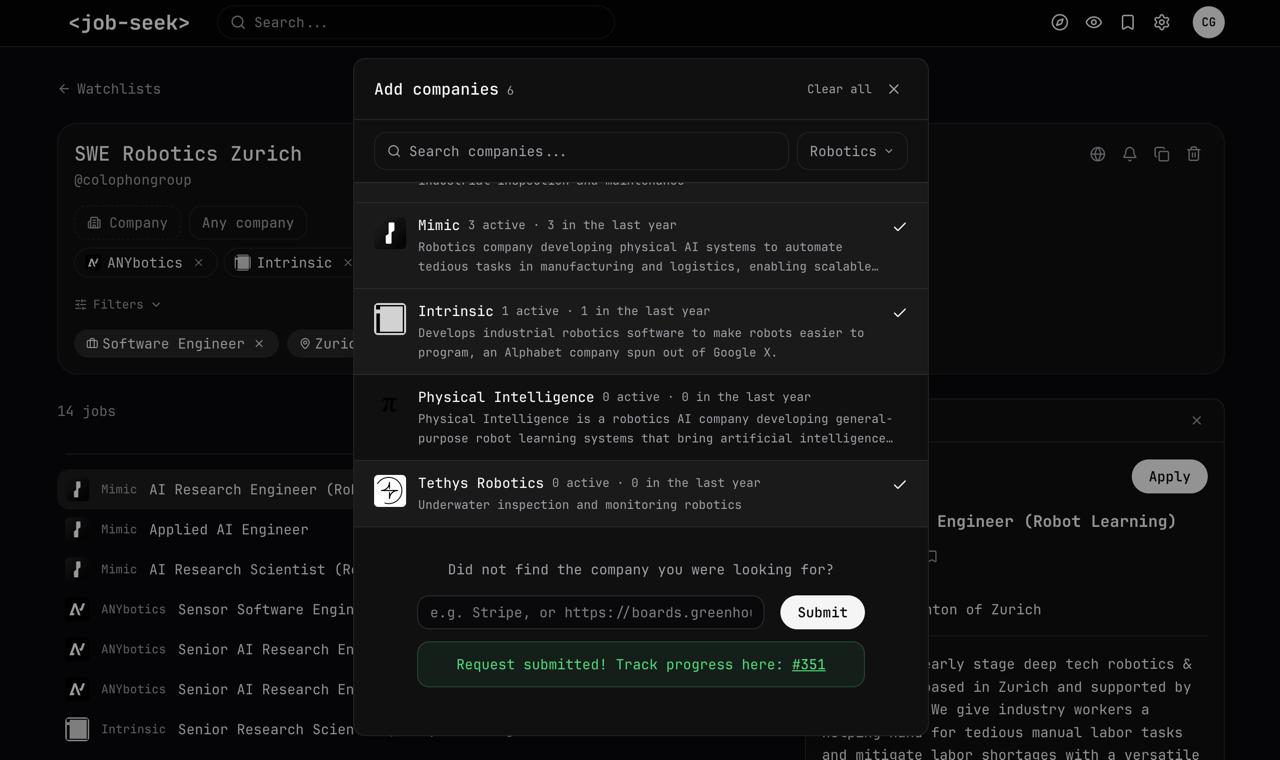
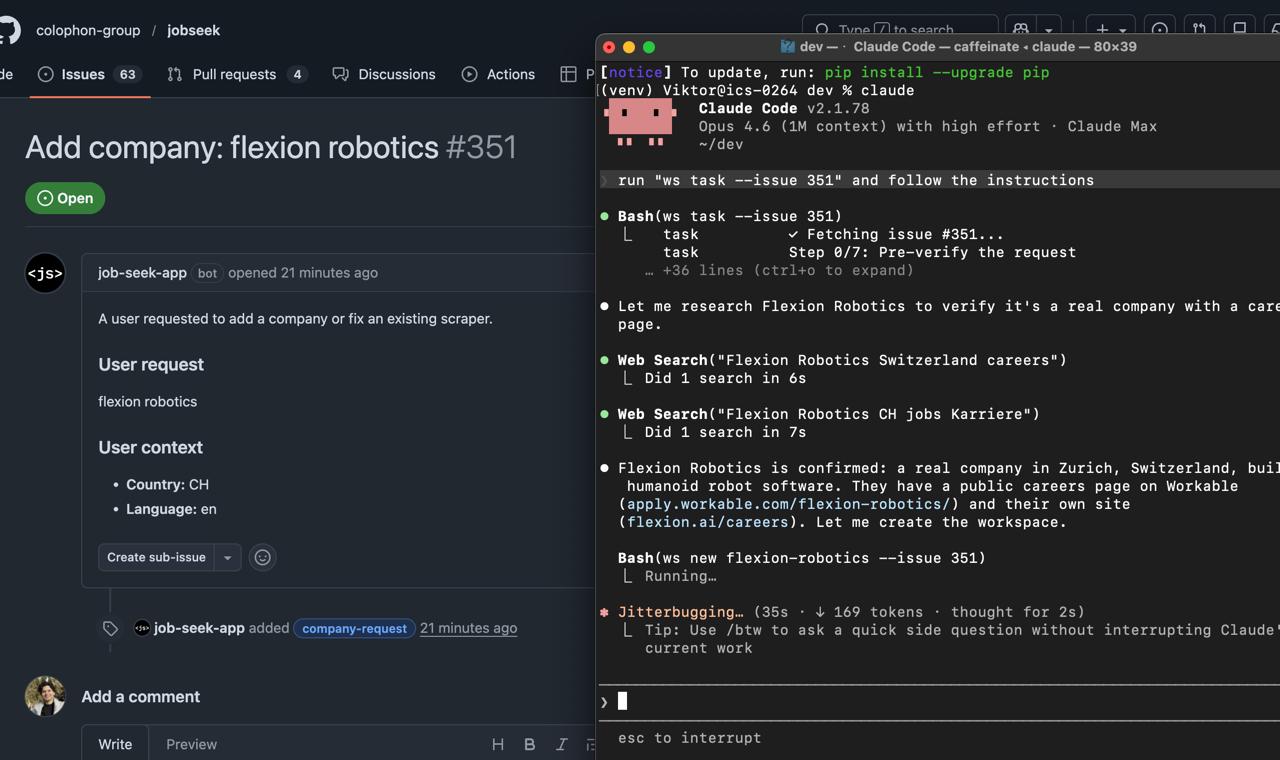
If some company is not on the website, users can request it, and our coding agents will autonomously configure the crawlers
-
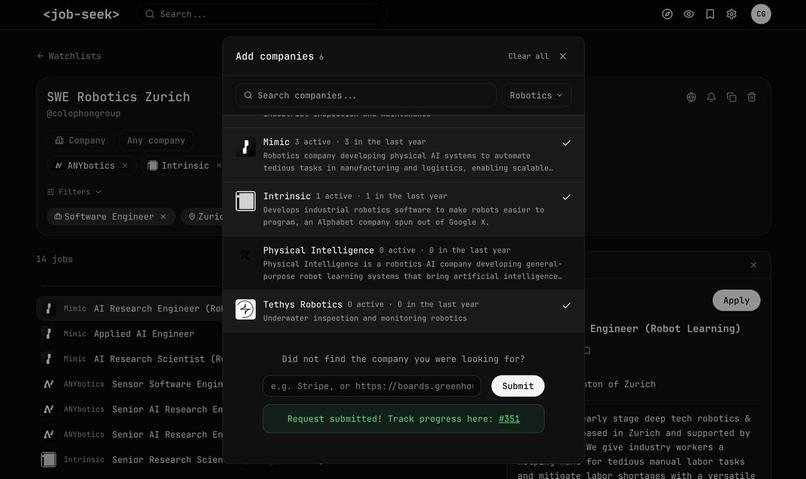
The tracking is done via GitHub issues
-
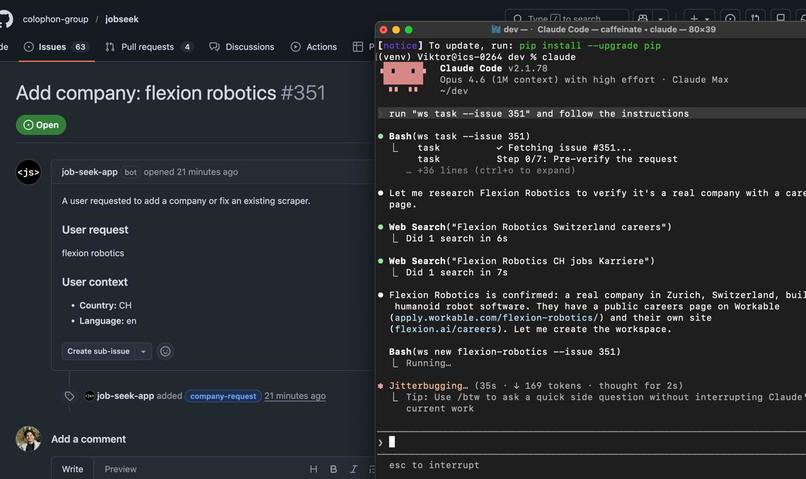
In case our agents are busy, users can contribute their own coding agents to configure crawlers. This is how we crowdsource agentic fleet
-

The team

Demo video (4min): https://youtu.be/Gawdd4aqqdE
Landing page: https://jseek.co
Pitch slide: https://drive.google.com/file/d/1-npZw0Ik-crhxDwfHNNdpRE2Vi15Hi3V/view?usp=sharing
Inspiration
We are in the middle of an AI-driven transformation of the labor market. Roles are being redefined, teams restructured, and millions of professionals will cycle through requalification and lengthy job searches in the years ahead. The tools available to them haven't kept up. Job seekers either doomscroll through ad-ridden algorithmic feeds on LinkedIn, juggle dozens of open tabs for companies that only post on their own career pages, or subscribe to alert spam just to be first to apply. The current aggregators fail at the one job they were supposed to do — aggregate jobs in one place. A long job search means the candidate has already done the research. They know the market, they know which companies hire for their role. They don't need an algorithm deciding what to show them. They need infrastructure that works as hard as they do.
What It Does
Jobseek is the first job aggregator where users source the companies. Paste a career page URL, and within hours that company is monitored permanently — for everyone. The catalog grows from user demand, not from a sales team or employer partnerships. No promoted listings, no engagement-optimized ranking — just what companies actually post, the moment they post it.
Beyond search, Jobseek provides tools for the long haul. Watchlists are persistent saved searches scoped to specific companies and filters, shareable via public URL — turning job search from a solo activity into something curated for communities, cohorts, or teams. A built-in application pipeline tracks postings from saved through applied, interviewing, and outcome, with per-round interview logging. The stats page renders a Sankey funnel and activity heatmap so candidates see their actual conversion rates, not just a list.
Today: 4,000+ monitored companies, half a million active postings refreshed hourly, under 10 CHF/month in infrastructure costs.
How We Built It
It started as an MVP for my own job search. Every crawler had to be manually coded for every website — tedious, and impossible to share. Agents alone weren't reliable enough. But agents equipped with generalizable tools that only needed to be configured — not rewritten — turned out to be a different story. The key insight was separating the what (tool logic) from the how (agent-driven configuration).
The company onboarding pipeline is fully agentic. When a user requests a company, a Claude Code agent picks up the task, identifies the ATS platform, probes monitor and scraper combinations, configures extraction, validates output against quality gates, and ships a PR — no human in the loop. On the discovery side, we built a fully agentic Apify actor connected to Gemini for reasoning and Apify's key-value store for persistent memory, which crawls competitor aggregators to find new job boards before users even request them.
The entire setup tool is open-source and pip-installable. Anyone — including AI coding agents — can run it. As agentic coding tools go mainstream, every user becomes a potential contributor, bringing their own AI compute to scale the catalog. The platform's supply side grows with the broader adoption of AI agents, not with our budget.
Challenges We Ran Into
Job postings are among the easiest things to scrape on the Internet. Companies want them to spread — they rarely add protections and often publish sitemaps for indexing. That said, some boards still end up behind heavy anti-bot measures, likely by accident rather than design. Apify proved powerful enough to handle almost any such case.
Accomplishments We're Proud Of
We designed an agentic pipeline that is flexible, efficient, and reliable — a combination that took many iterations to get right. The architecture we landed on — feeding the agent just enough context to progress to the next step, never more — is what makes it consistently performant.
The project is fully open-source. Every contributor — whether they requested a company, resolved a setup task with their own agent, or improved the extraction logic — strengthens the platform for everyone. The flywheel is structural: each contribution permanently expands the index, which attracts more users, who make more contributions.
What We Learned
- Context is a budget, not a dump. Giving the agent the full picture upfront led to hallucinated steps and wasted tokens. Narrowing the context window to only what's needed for the current decision dramatically improved both accuracy and cost.
- Tools beat prompts. Instead of prompt-engineering the agent into producing scraping code, we gave it well-defined, parameterized tools. The agent's job shrank from "write a crawler" to "configure this tool" — a far more constrained and reliable task.
- Fail fast, retry cheap. Agentic pipelines will fail. The trick is making each step small enough that retrying is inexpensive and diagnosing errors is straightforward.
- Know when to switch strategies. Some pages are too complex to handle efficiently with rule-based extraction. When the pipeline hits severe parsing difficulties, we fall back to Apify's AI parser — trading cost for coverage. The lesson: design for graceful degradation, not perfect pipelines.
What's Next for Jobseek
We are launching in Switzerland — one of the toughest and most multilingual job markets there is. After validating the product and the contributor model, we plan to expand across Europe and the US. The goal: build the infrastructure layer where every open role on the Internet is one search away, and where the catalog is maintained not by a company, but by a community of humans and AI agents working together. As AI reshapes who works where and how, we want the job search itself to be faster, fairer, and fully in the candidate's control.
Built With
- apify
- claude
- cloudflare
- fly.io
- gemini
- next.js
- pydantic
- python
- react
- supabase
- typescript
- vercel



Log in or sign up for Devpost to join the conversation.