-
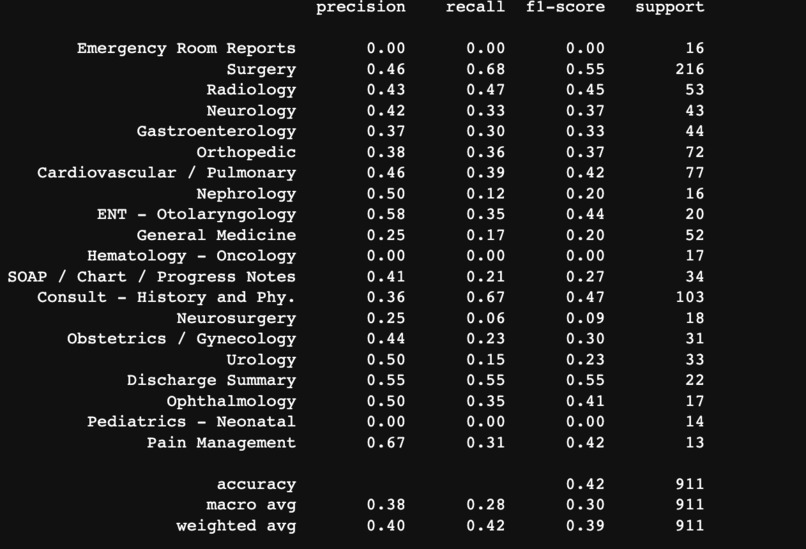
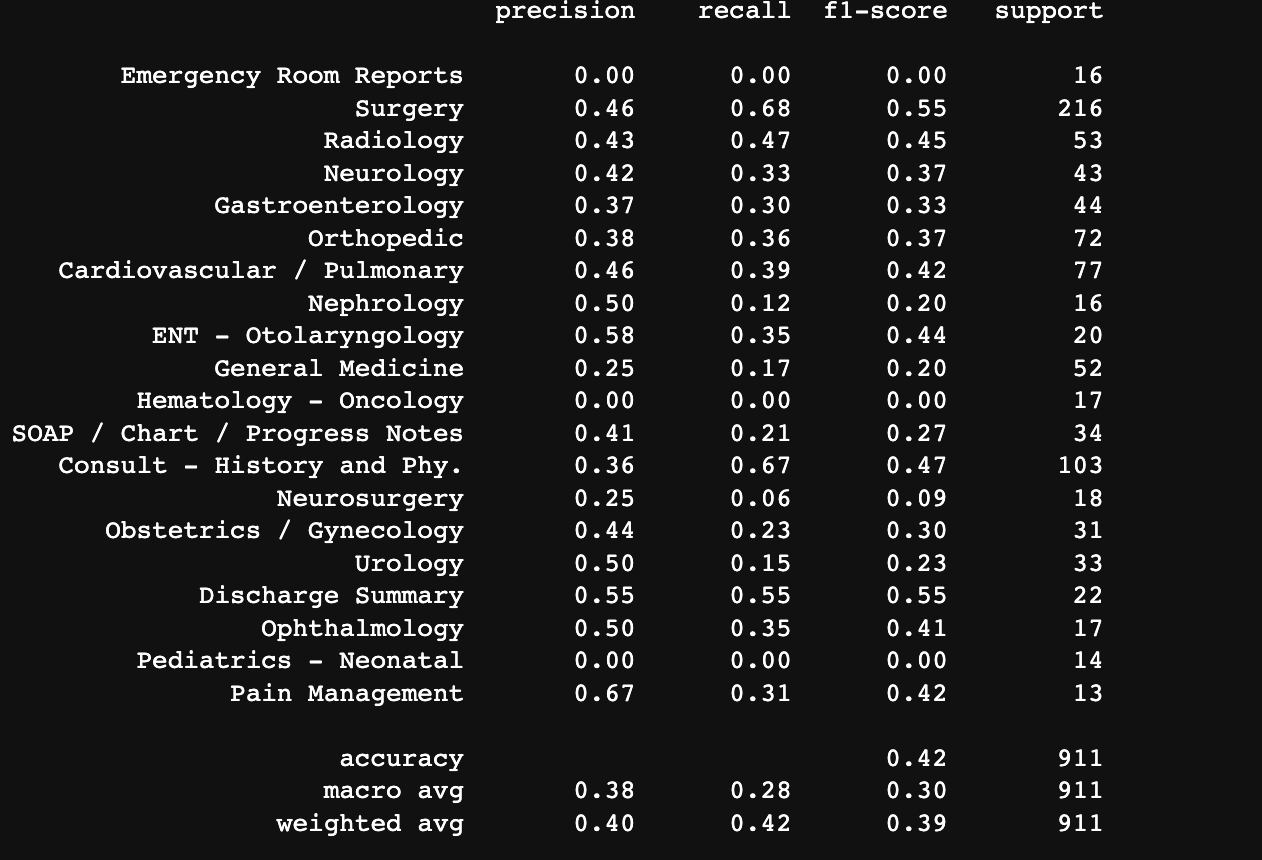
Prediction Accuracy
-
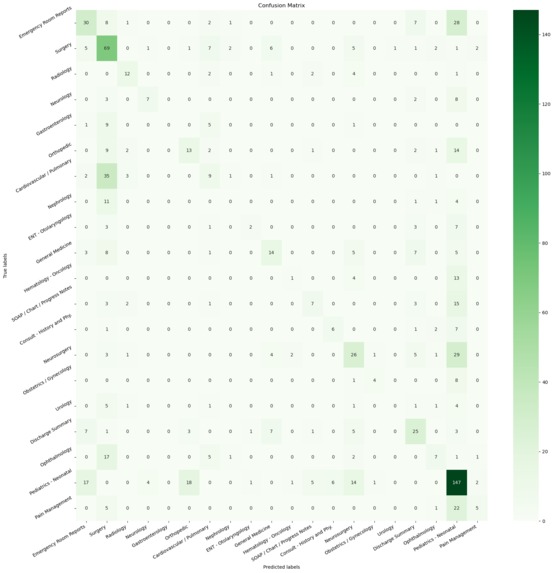
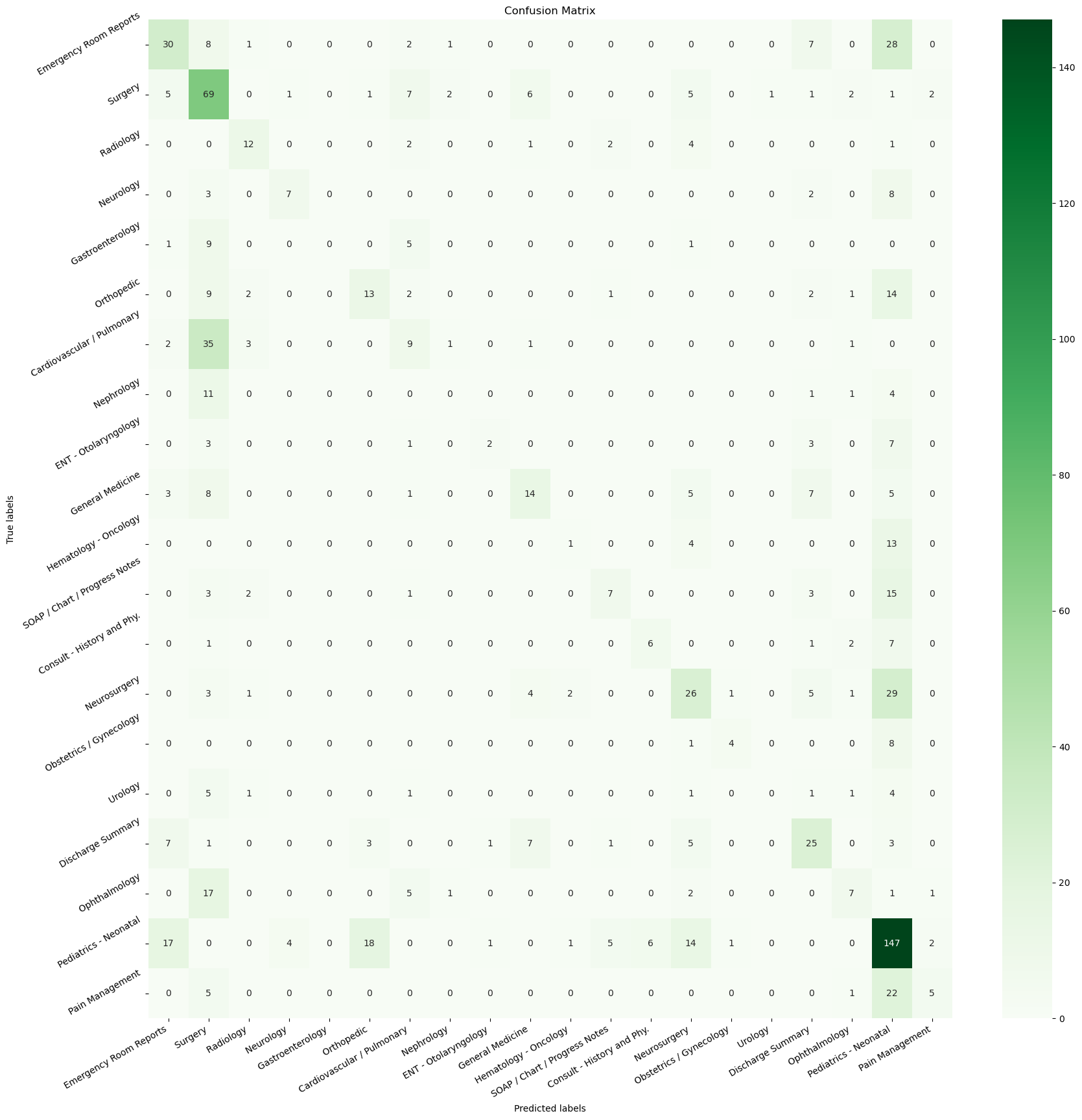
Confusion Matrix
-
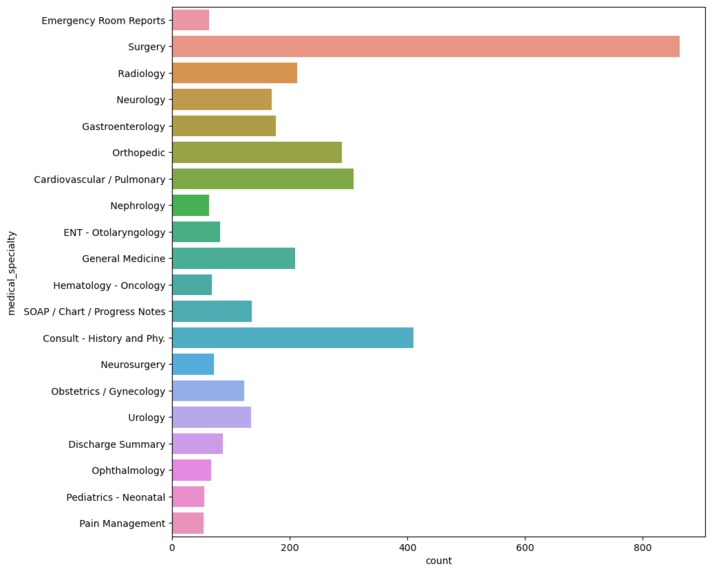
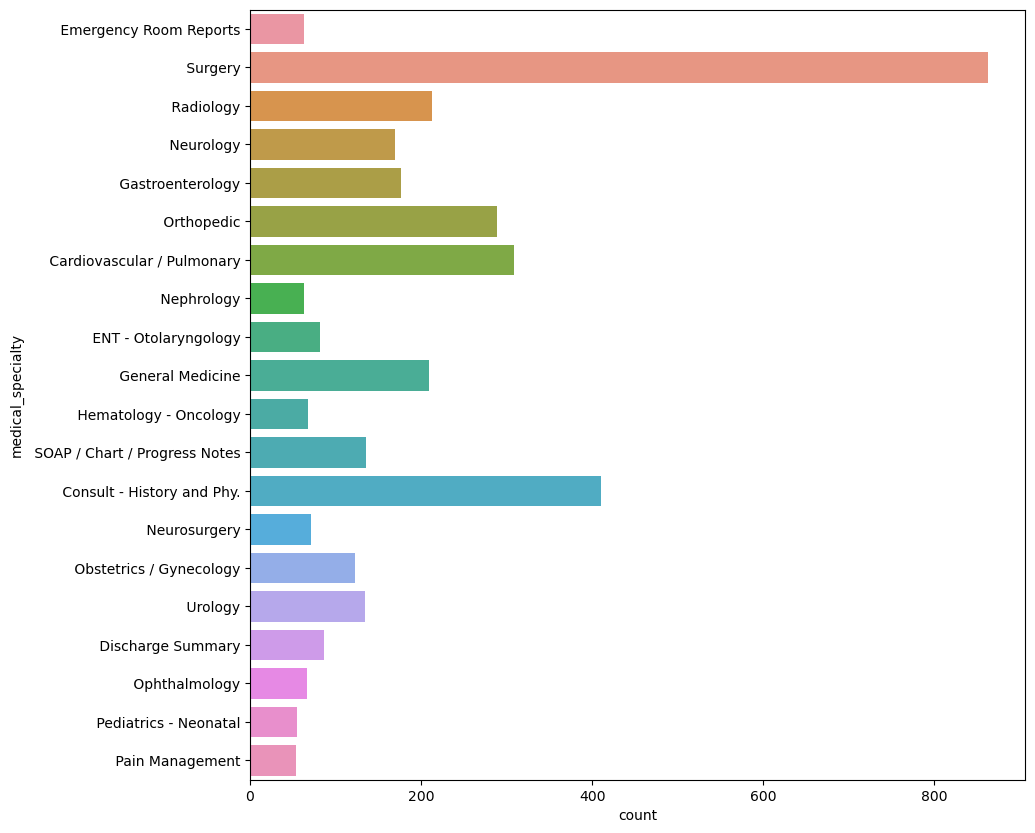
Unique Specialties Count (most common)
Inspiration
We are complete beginners and wanted to dip our feet into the data industry. This hackathon seemed like the perfect way to do so. We decided to go with the Intact challenge as it appealed to us as a real world issue and we thought it was interesting.
What it does
We created a solution to provide automated clinical text classification given the Intact dataset. Our logistic regression model predicts the medical_specialty/type for each given medical transcript.
How we built it
Jupyter Notebook written in Python.
The notebook utilizes several Python libraries for data manipulation, analysis, and visualization, including: Pandas: for data manipulation and analysis NumPy: for numerical computations Matplotlib: for data visualization Seaborn: for statistical data visualization Scikit-learn: for machine learning algorithms and tools
We also used the logistic regression model for binary classification for the medical specialties which was also displayed through the Confusion Matrix .
Vectorizers were also used to convert text data into numerical features mainly for the transcription list.
Challenges we ran into
Being absolute beginners (no experience) for building a working model, there were many trial and error phases and trying to understand how each process works to build a fully functioning data classification system. Some of main challenges faced were:
Our method was to break down the transcript into smaller key words aimed to make it easier to comprehend the underlying information. However, due to the complexity of the tokenization process, we encountered several difficulties in achieving this goal. As a result, we decide to simplify the process by utilizing basic tokenizer methods. This approach helped us to effectively identify and isolate the key concepts and themes in the transcript, allowing us to gain a better understanding of the overall content.
Deducing a low f1-score after multiple attempts for transforming the data. We were able to increase this by adjusting the train/test split while training the model. In the end, we were able to bring a rise to the score by transforming instead of fit transforming.
The fitted model contained several errors that required a thorough troubleshooting process to resolve. Multiple attempts were made to rectify these errors through a trial-and-error approach until a functional solution was achieved. To further refine the model, additional measures could be taken to identify the root cause of the errors and prevent their recurrence in the future.
Overall Outcome
In the end, we created a very basic prediction model that moderately functions throughout the data set given. With all honesty after attempting numerous times, we do not believe the accuracy of our model is the best as it predicts 900 surgeries which seems to be inaccurate. Regardless of the dataset, we are proud to have a functional prediction model given that this is our very first hands-on data science project.
Next Steps
For next steps, in order to enhance the performance of this model, several steps could be taken. Firstly, applying more advanced tokenization techniques could lead to better extraction of keywords from each transcript, resulting in more accurate and informative data. Secondly, experimenting with different models could provide insight into which approach is best suited for the specific data being analyzed. Additionally, conducting further research into the medical background of each specialty and customizing the keyword extraction process accordingly could also improve the accuracy of the model. By incorporating these steps, we can take the necessary measures to refine and optimize the model's functionality, ultimately resulting in a more accurate prediction model.
What we learned
How to create a machine learning model from scratch, import data and prepare it for appropriate modelling, researching to choose the most appropriate model, and using that model to predict values for new data.
Built With
- jupyter
- machine-learning
- matplotlib
- numpy
- pandas
- python
- seaborn
- sklearn

Log in or sign up for Devpost to join the conversation.