-
-

Our map
-

Our sign
-

monkey tags
-

Background for index.html
-

the monkeybombs
-
roast baron icon
-

roast base icon
-

roast jungle icon
-

roast botlane icon
-

roast dragon icon
-

roast midlane icon
-

roast toplane icon
-

Coach baron icon
-

coach botlane icon
-

Coach dragon icon
-

Coach jungle icon
-

coach midlane icon
-

coach toplane icon
-
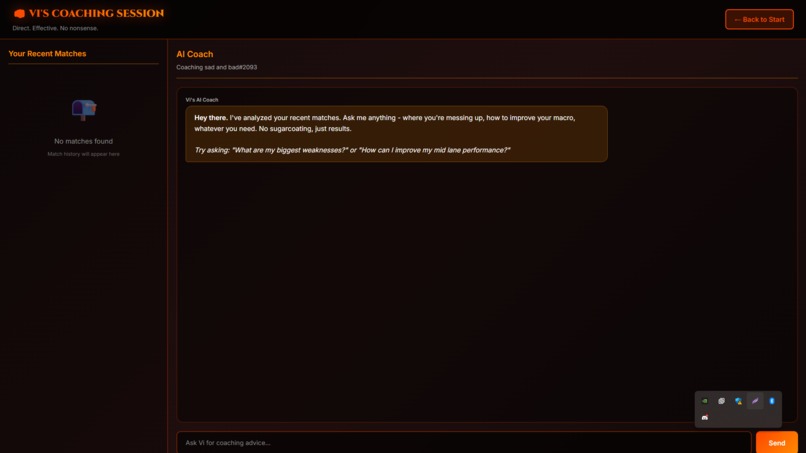
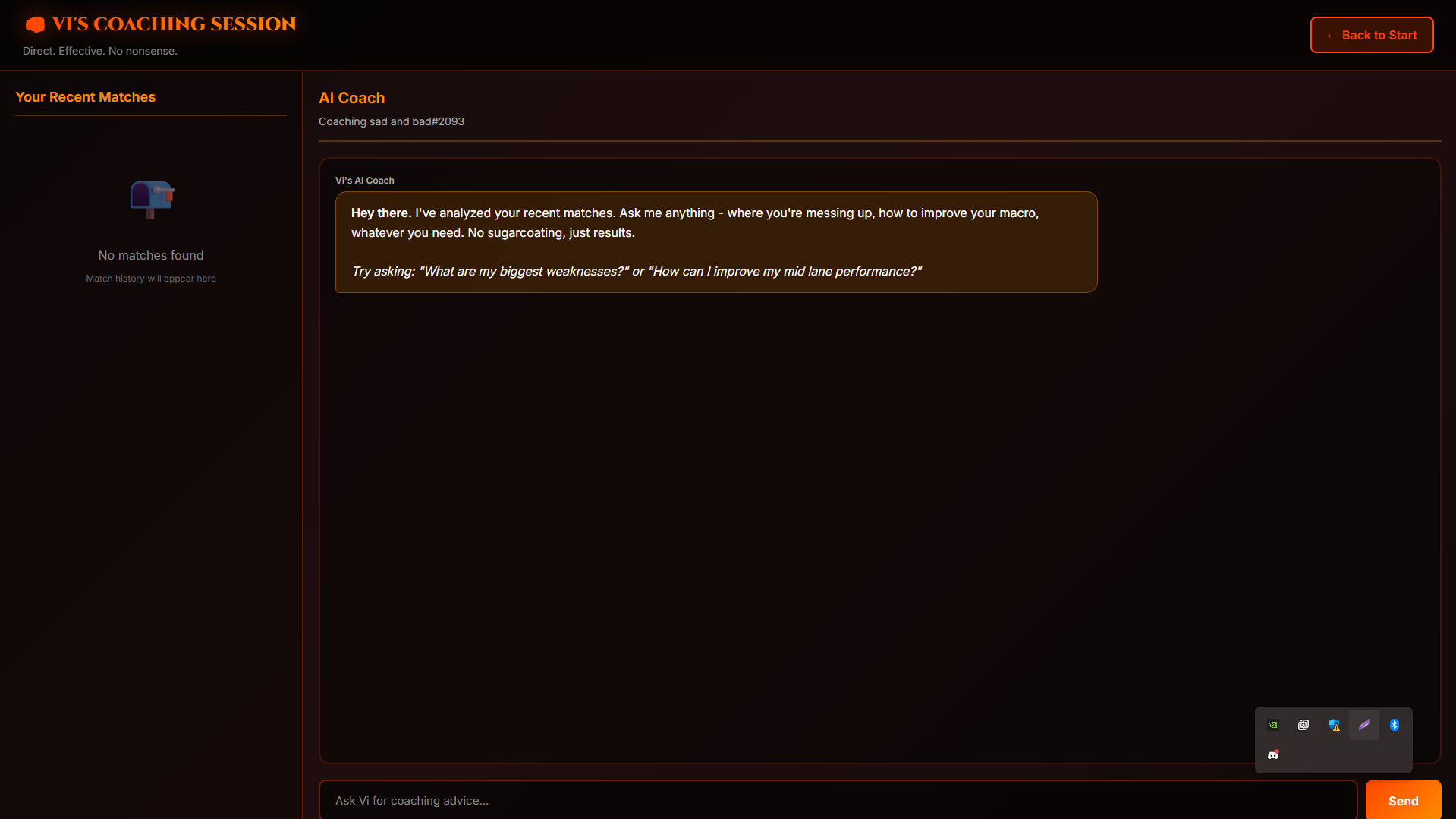
ai coaching page
-
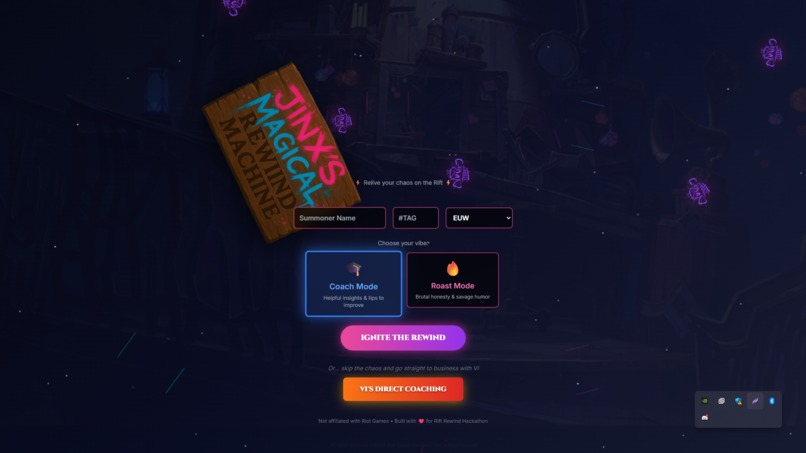
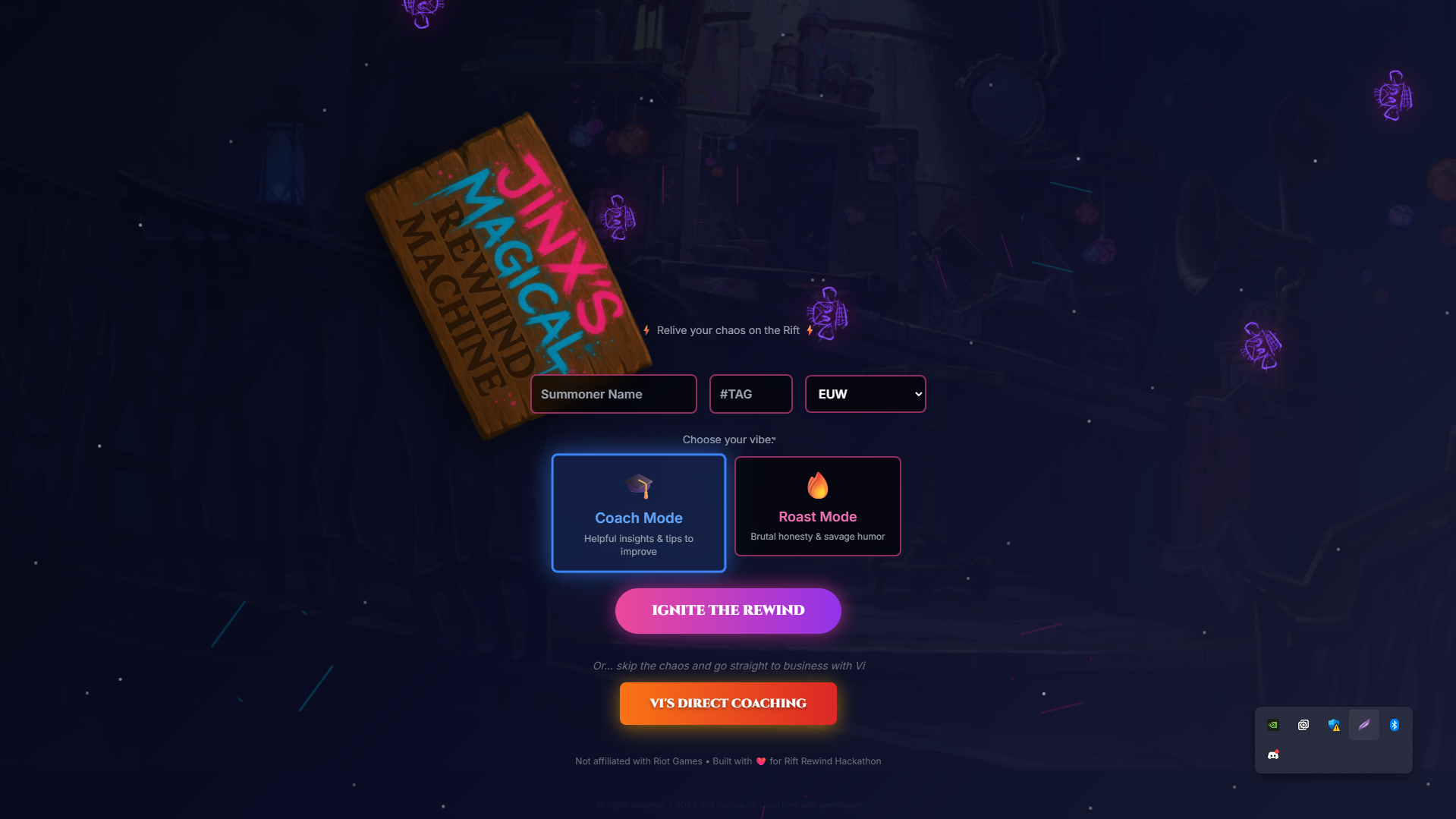
front page
-

map page
-

player card example
-

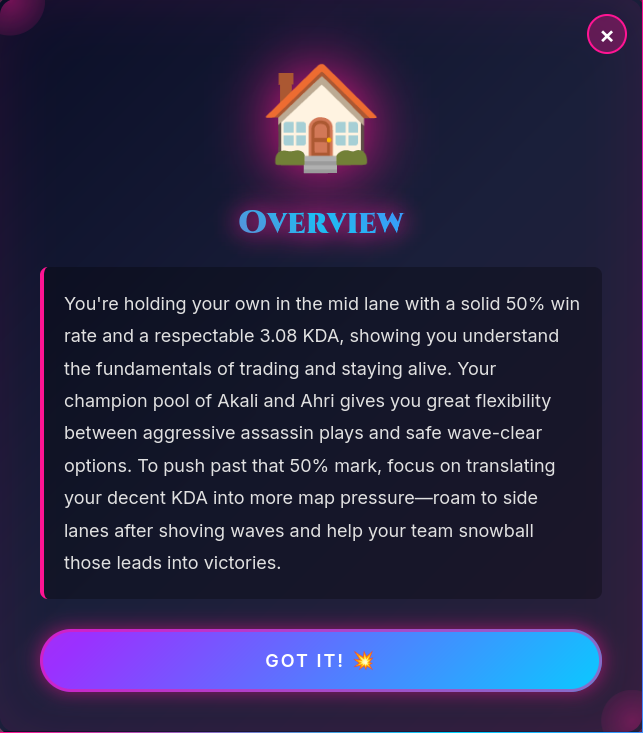
map coaching example2
-
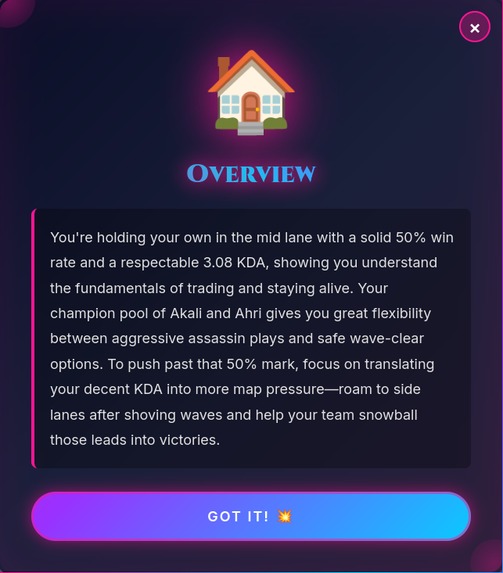
map coaching example1
-

map coaching example3






















Project Story
## Inspiration
As League of Legends players ourselves, we've all been there: staring at post-game stats wondering "What could I have done better?" Traditional stat-tracking sites like op.gg give you numbers like KDA, CS, damage, but they don't tell you the story of your gameplay. They don't remember that three games ago you struggled with early jungle invades, or that you've been working on improving your mid-game rotations. When we saw the AWS x Riot Games hackathon, we knew we wanted to build something different: a coaching experience that feels personal, visual, and continuous. Not just another dashboard, but a coach that grows with you.
## What It Does
RiftRewind transforms League match data into three core experiences:
- Interactive Map Analysis - Click on any zone of Summoner's Rift (top lane, dragon pit, enemy jungle) and get AI-powered feedback ( Coach or Roast ) specific to that area
- Conversational AI Coach - Chat with Claude Sonnet 4.5 that remembers your previous sessions, can query your match history in real-time, and provides personalized advice
- Shareable Player Cards - AI-generated cards with custom titles like "The Scaling Menace" or "The 0/10 Powerspike Enthusiast" (roast mode is brutal!)
## How We Built It
### Architecture Philosophy We designed RiftRewind as a serverless-first application to handle unpredictable hackathon traffic:
Backend (Thierry):
- Flask on AWS Elastic Beanstalk for auto-scaling web serving
- DynamoDB for player conversations and dynamic data ($O(1)$ lookups!)
- SQLite for static League reference data (14,000+ items, runes, champions)
- AWS Bedrock for Claude Sonnet 4.5 integration
AI System (Thierry): We built a custom tool-calling system with LangChain that gives Claude access to:
- Champion counters and matchup data
- Build recommendations and item statistics
- Player match history with $\text{KDA} = \frac{K + A}{D}$ calculations
- Zone-specific performance metrics
The AI maintains conversation memory per player, storing context vectors in DynamoDB for continuity.
Riot API Integration (Aymeric):
- Pulsefire library for match data retrieval
- Async data pipeline: $\text{Summoner} \rightarrow \text{Match IDs} \rightarrow \text{Match Details} \rightarrow \text{Statistics}$
- Implemented caching to respect rate limits (20 requests/second, 100 requests/2 minutes)
- Pandas aggregation for zone-based analysis:
$$ \text{Zone Performance} = \frac{\sum \text{kills in zone} - \sum \text{deaths in zone}}{\text{time spent in zone}} $$
Interactive Frontend (Aymeric):
- Vanilla JavaScript Canvas API for the Summoner's Rift map
- Clickable polygonal zones using ray-casting algorithm
- Smooth camera controls with momentum physics
- No frameworks—just clean, performant code
Image Generation (Hugo):
- Pillow for rendering player cards with custom Teko fonts
- Champion splash art compositing with gradient overlays
- Dynamic text positioning based on content length
- Export to PNG for social media sharing
DevOps (Hugo):
- Docker + Docker Compose for consistent dev environments
- Multi-stage builds to minimize image size
- Font file mounting for consistent typography
## What We Learned
### Technical Insights
1. AI Tool Design is Hard Our first iteration gave Claude too many tools—it would call 10+ functions per response, burning tokens and money. We learned to:
- Consolidate related queries into single tools
- Pre-fetch common data into context
- Use tool descriptions to guide Claude's decision-making
2. DynamoDB != SQL Coming from relational databases, we initially fought against DynamoDB's key-value nature. The breakthrough came when we embraced single-table design: PK: PLAYER# SK: CONVERSATION# PK: PLAYER# SK: MATCH# This reduced our table count from 5 to 1 and cut query latency by 60%.
3. Canvas Performance Matters Rendering Summoner's Rift at 30fps required optimization:
- Offscreen canvas for static elements
- Dirty rectangle rendering (only redraw changed zones)
- RequestAnimationFrame instead of setInterval
4. Rate Limiting at Scale Riot's API rate limits forced us to implement:
- Request queuing with exponential backoff: $\text{delay} = \min(2^n \times 100\text{ms}, 5\text{s})$
- Distributed rate limiting using DynamoDB atomic counters
- Graceful degradation when limits are hit
### Team Dynamics
- Parallel development: We used feature branches aggressively—19 PRs in 3 days
- Daily syncs: 15-minute standups to unblock dependencies
- Documentation-driven: Writing docs during development kept everyone aligned
## Challenges We Faced
### Challenge 1: Memory Bloat Problem: Storing full conversation history in DynamoDB was expensive ($0.25 per 1M reads).
Solution: Implemented sliding window memory:
- Keep last 10 messages in DynamoDB
- Summarize older conversations using Claude
- Store summaries as compressed metadata
Result: 80% cost reduction while maintaining context quality.
### Challenge 2: The "Roast Mode Incident" Problem:
- Our AI roasts were too savage. Early testers reported feeling genuinely insulted
- We were giving it too much data, and wanted to generate the stories before giving access to the map Solution:
- Added system prompt guidelines: "Be humorous but constructive"
- Implemented positivity ratio: $\frac{\text{roasts}}{\text{compliments}} \leq 2$
- A/B tested with playtesters until we found the sweet spot
- Generating the story on demand, player clicks the zone and needs to wait a bit
### Challenge 3: Map Coordinate Chaos Problem: Riot's coordinate system (0-15,000) didn't match our canvas (0-800px), causing misaligned zones.
Solution: Linear transformation matrix: $$ \begin{bmatrix} x' \ y' \end{bmatrix} = \begin{bmatrix} \frac{800}{15000} & 0 \ 0 & \frac{800}{15000} \end{bmatrix} \begin{bmatrix} x \ y \end{bmatrix} $$
We pre-computed zone polygons and stored them as JSON.
### Challenge 4: Elastic Beanstalk Debugging Problem: Deploy worked locally but failed in production with cryptic errors.
Culprit: Missing environment variables in EB config.
Lesson Learned: Always use .ebextensions for configuration, not manual console settings.
### Challenge 5: Race Condition in Conversation State Problem: Two users chatting simultaneously could overwrite each other's conversation history.
Solution: DynamoDB conditional writes with version numbers:
response = table.update_item(
Key={'player_id': player_id},
ConditionExpression='version = :old_version',
UpdateExpression='SET messages = :new_messages, version = :new_version'
)
Built With
- aiohttp
- amazon-bedrock
- amazon-dynamodb
- amazon-elastic-beanstalk
- boto3
- docker
- es6+
- flask
- gsap
- html5
- javascript
- langchain
- markdow
- pandas
- pulsefire
- python
- riot-free-api
- sqlite



Log in or sign up for Devpost to join the conversation.