-
-
Jimmy Login Page
-
Jimmy Account Create Page
-
Jimmy Home Page New Thread
-
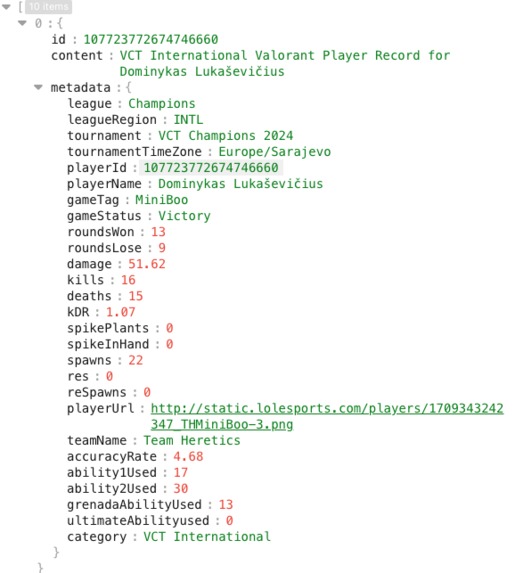
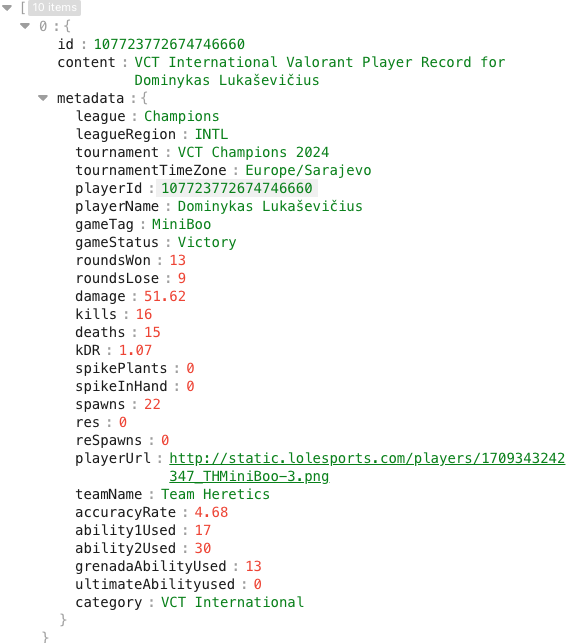
Player JSON Record Sample - Jimmy Builder output file
-
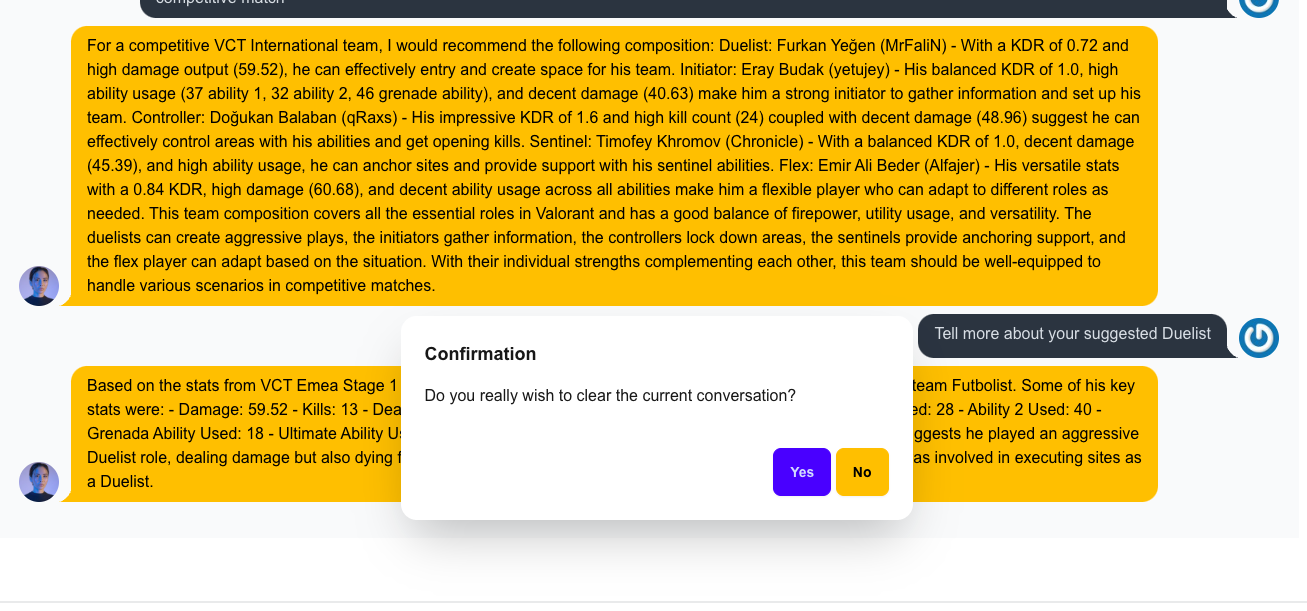
Jimmy Home Page Clearing Conversation
-
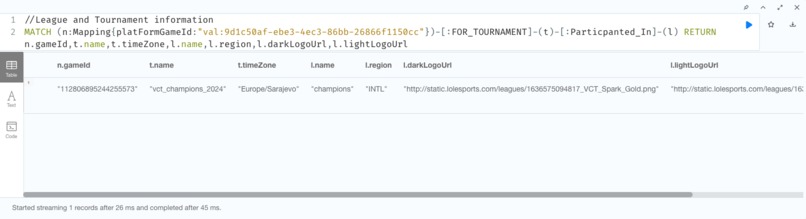
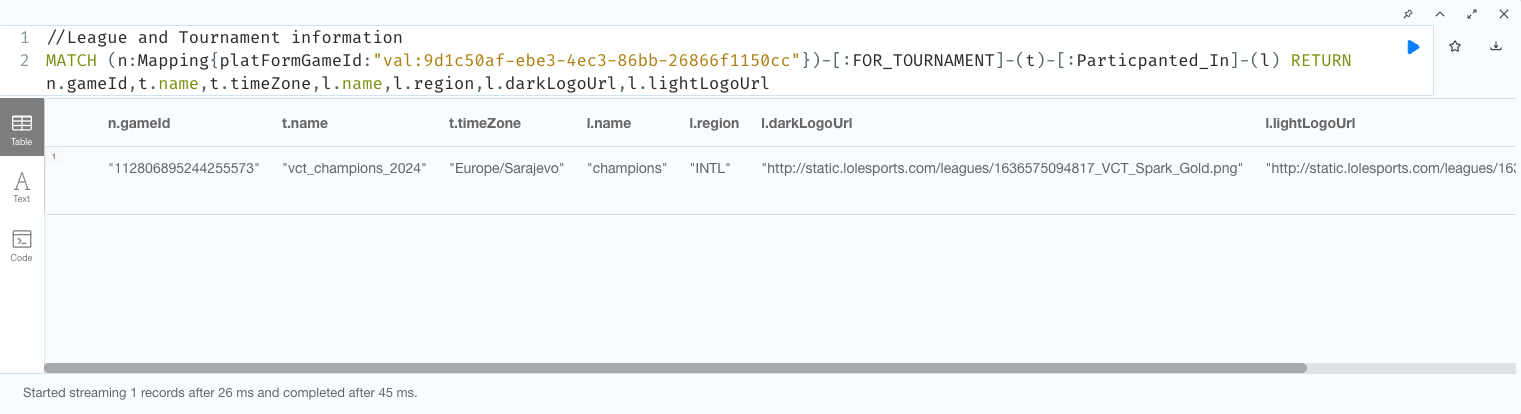
Platform Game Cypher Match Statement
-
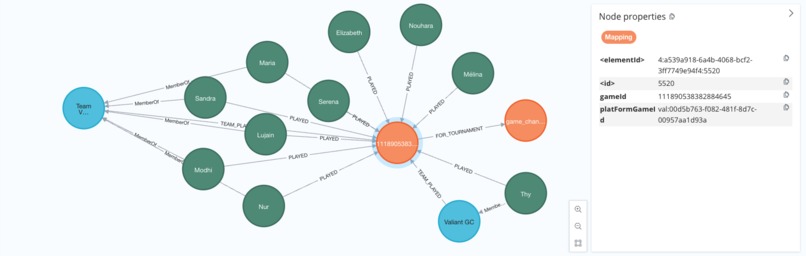
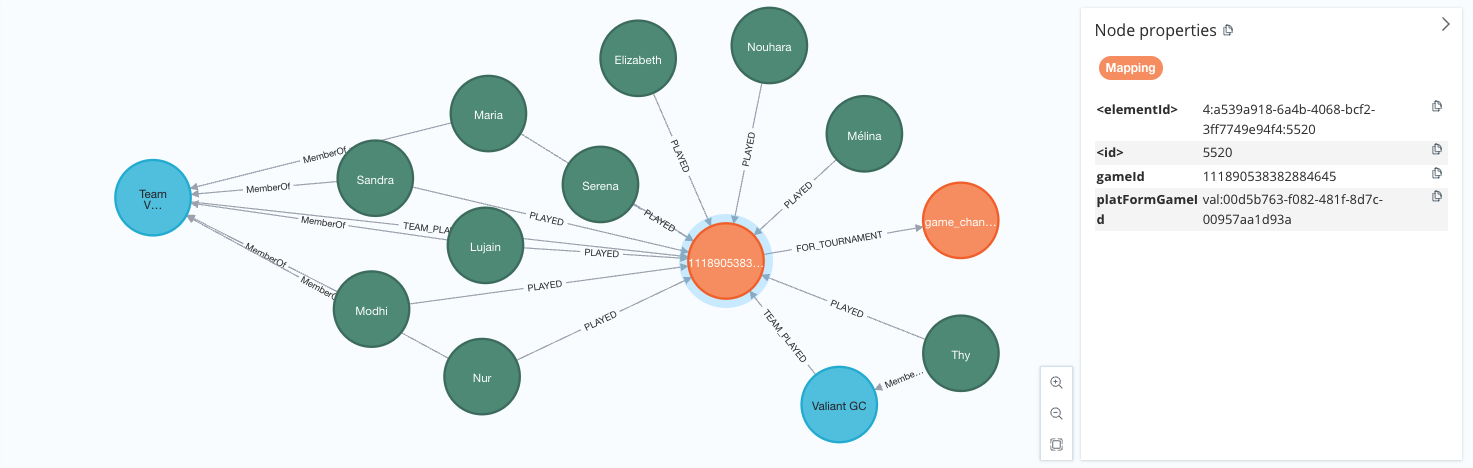
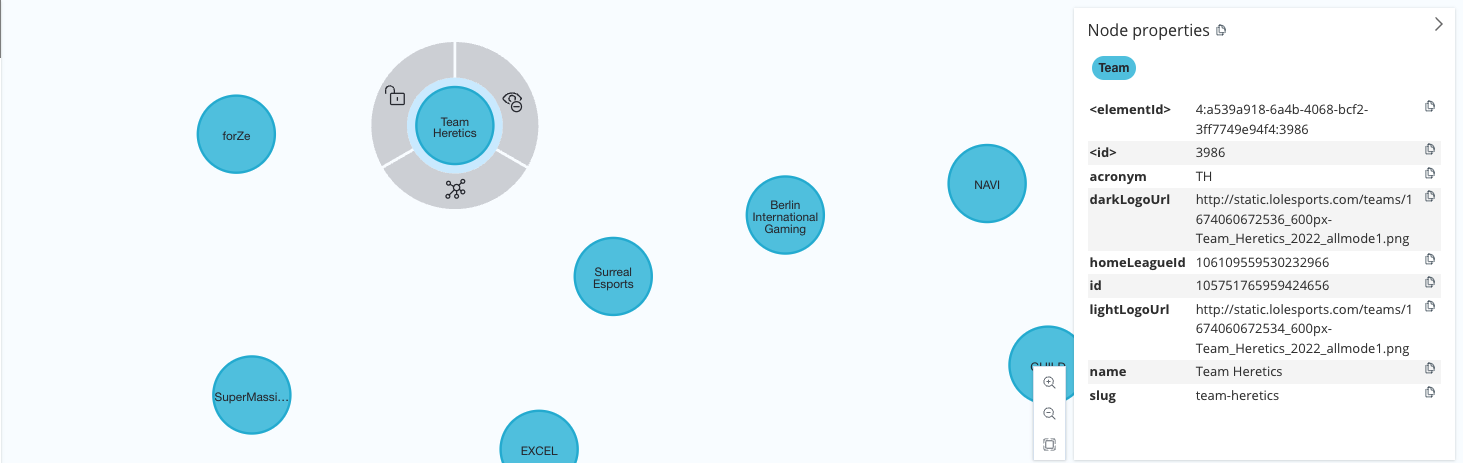
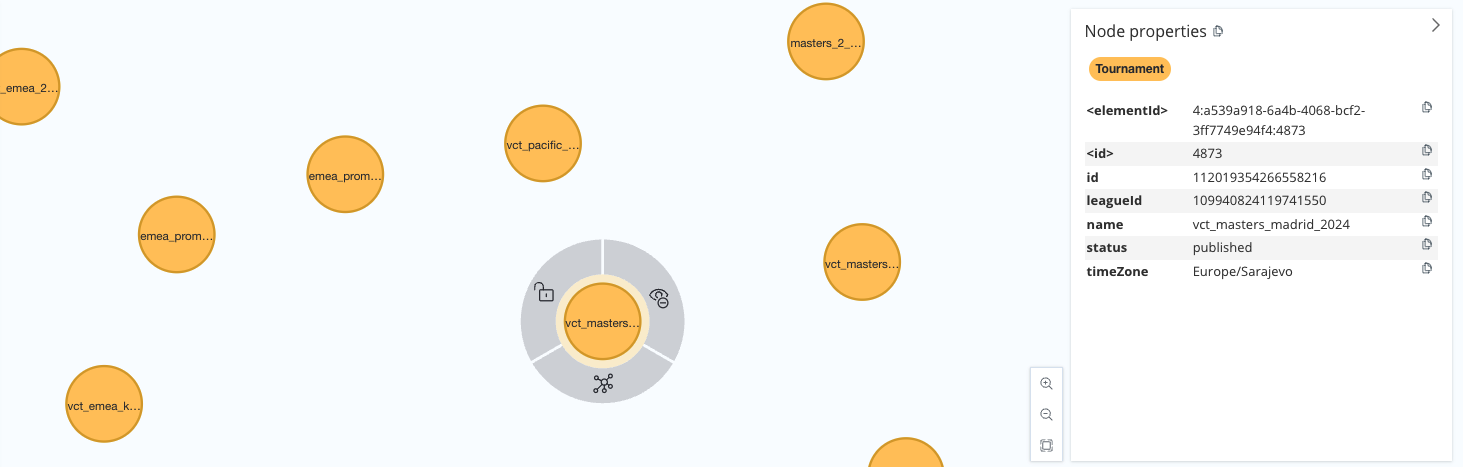
Game Mapping Data details, nodes and relationships
-
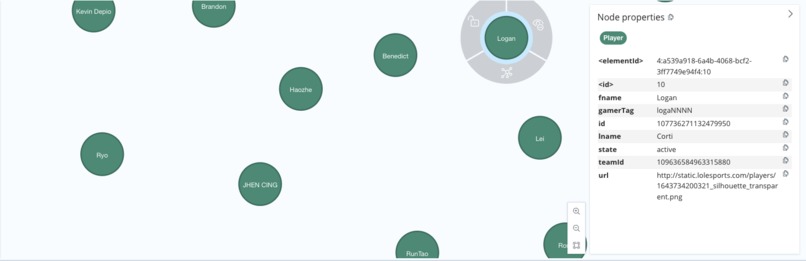
Player Node Details
-
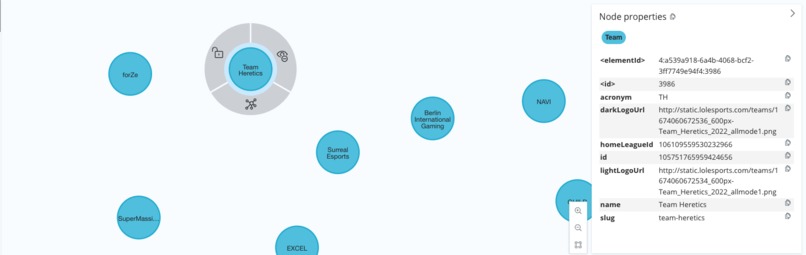
Team Node Details
-
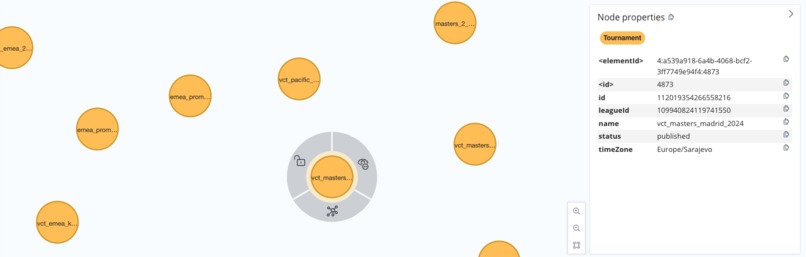
Tournament Node Details
-

Agent JSON Records for RAG
-
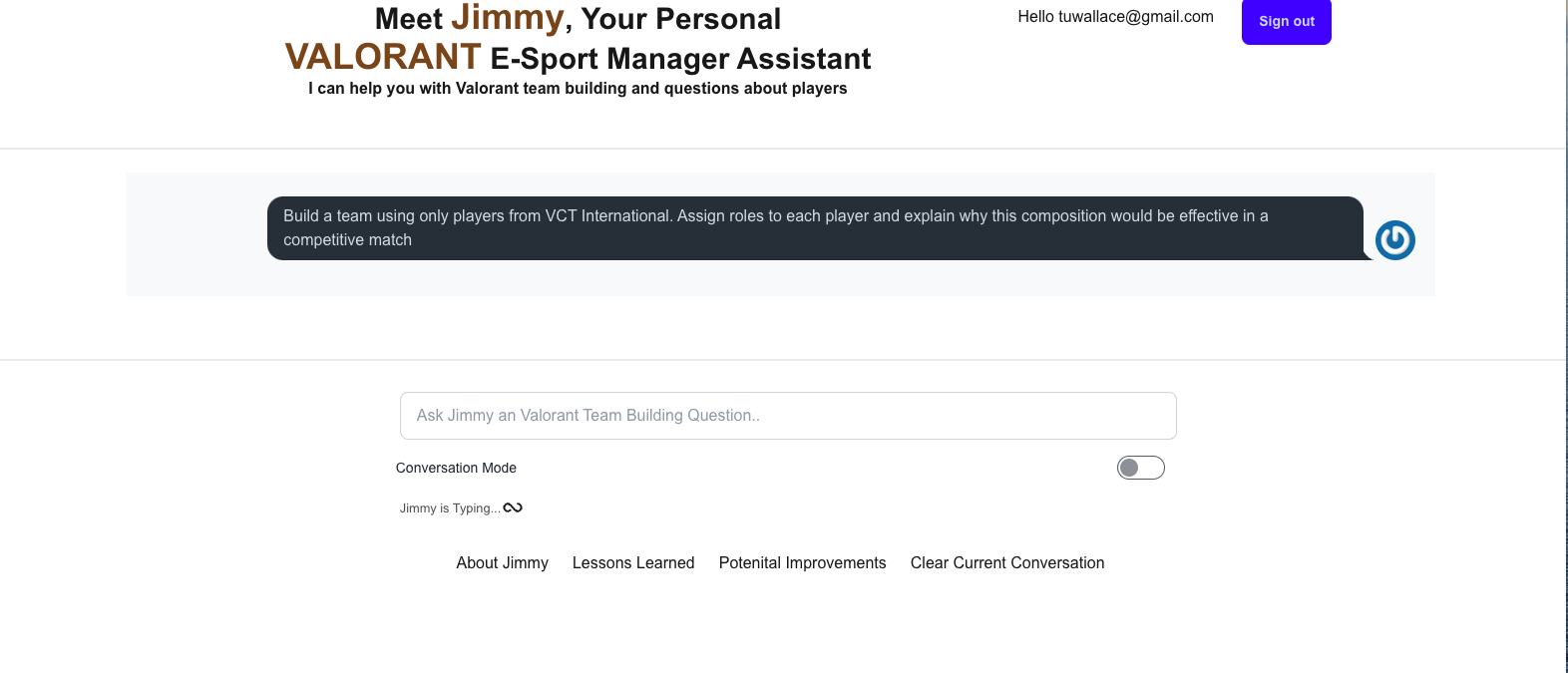
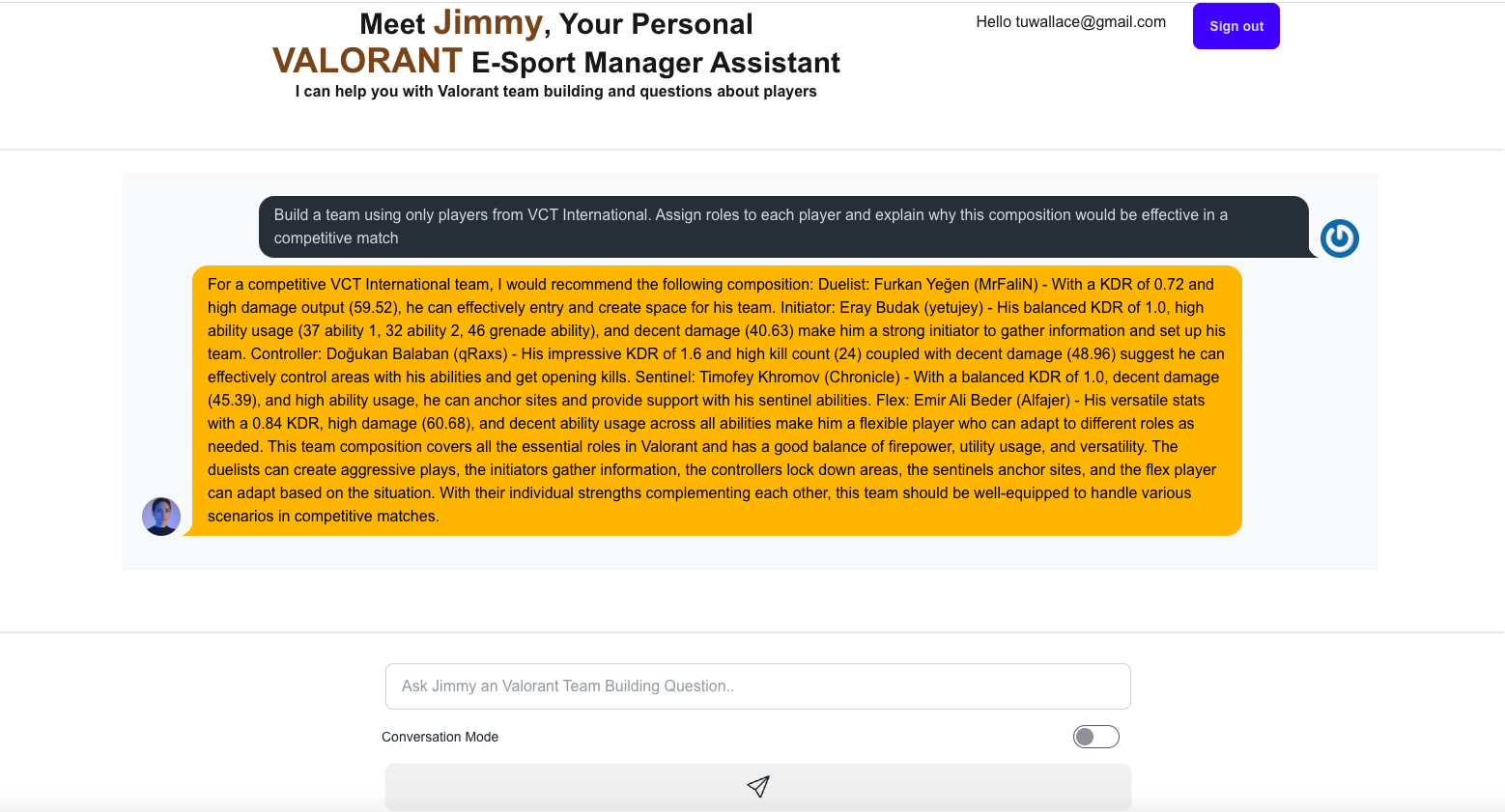
Jimmy Home Page 1st Question
-
Jimmy Initial Home Page
-
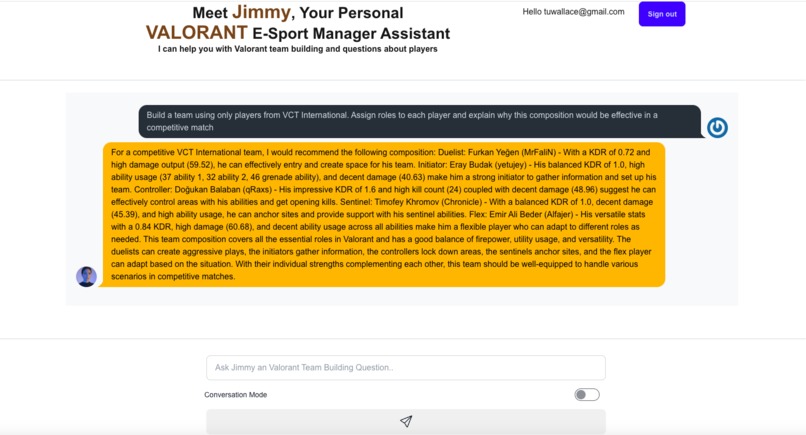
Jimmy Home Page Response to 1st Question
-
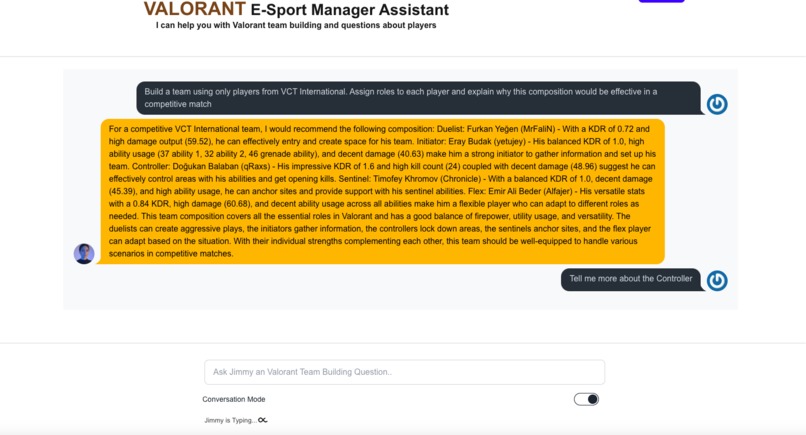
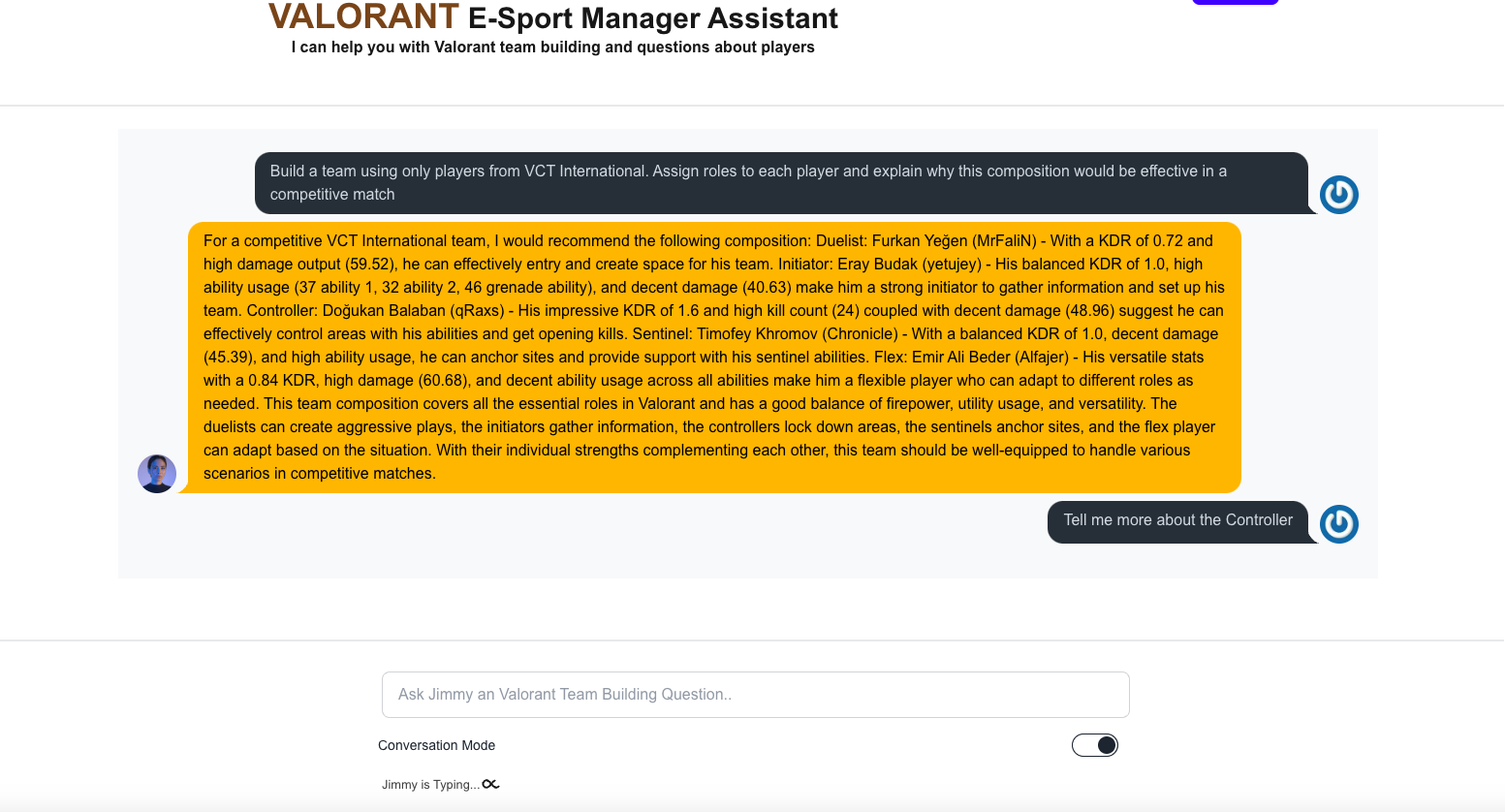
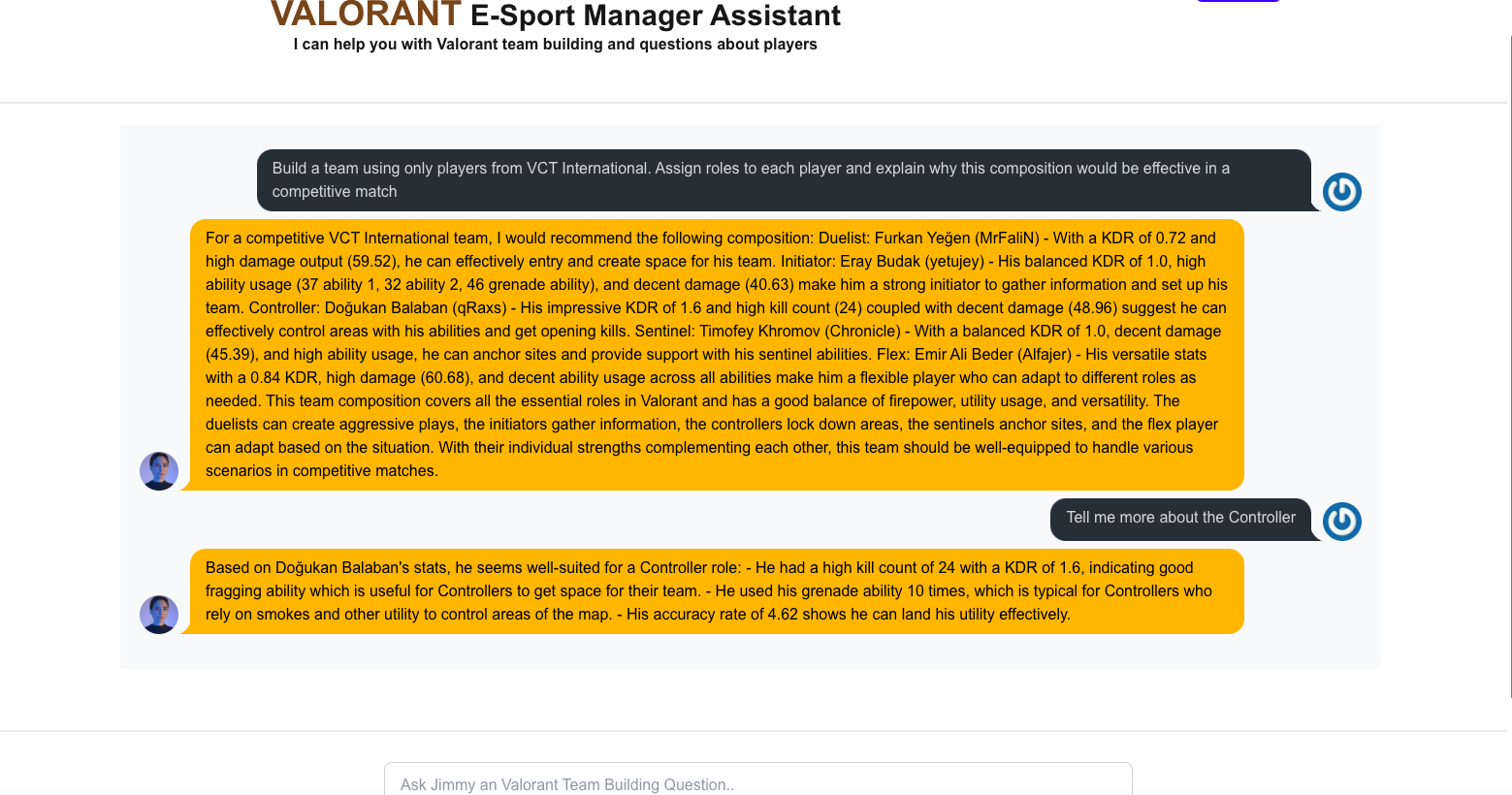
Jimmy Home Page 2nd Question with Conversation Mode
-
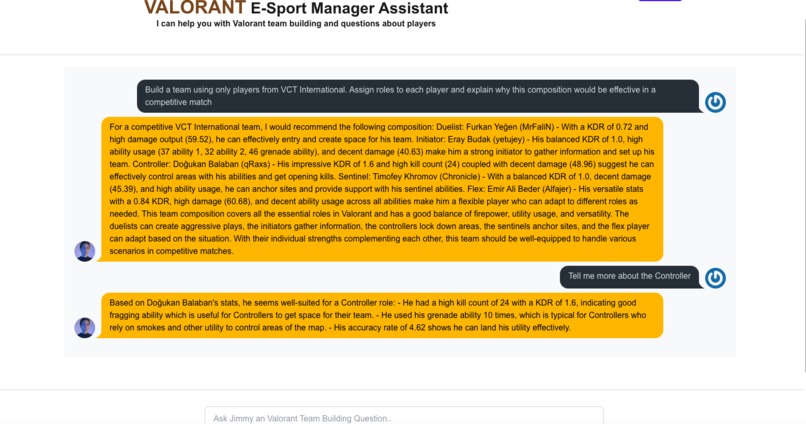
Jimmy Home Page Response 2nd Question


Inspiration
Learning something new by developing practical solutions with various tools and embracing the intellectual challenge
What it does
Jimmy is an AI chatbot app, similar to ChatGPT, powered by AWS Bedrock. This Amplify Gen 2 Next.js app uses Amplify Authentication and Data to provide answers and team-building recommendations for Valorant e-sports managers. Authenticated users can post Valorant-related questions to the Retrieval Augmented Generation (RAG) Knowledge Base and Claude 3 Sonnet LLM, which query the Pinecone vector store for responses.
Jimmy utilizes Amplify Data (GraphQL) to send questions to a RetrieveAndGenerate API (AWS Bedrock Agent Runtime) and serialize responses. Answers include a session ID to support conversation flow management.
The RetrieveAndGenerate API handles follow-up questions by requiring the session ID from the previous response. Jimmy's Conversation Mode leverages this to manage ongoing queries using the last session identifier
How we built it
The primary design and implementation goal was to minimize costs, as I was using my company's AWS account.
The VCT Esports data from Riot Games was loaded into a graph database (Neo4J) and a NoSQL repository (MongoDB). Fixture data (2024 only) was used to create graph nodes, metadata, and relationships representing leagues, tournaments, players, teams, and maps. Game data (10 instances) was imported as document records into a NoSQL collection.
A custom CLI tool called JimmyBuilder generates JSON data files using the Platform Game ID as a key. It accepts the Platform Game ID as a command-line parameter to execute Cypher MATCH and MongoDB FIND queries, assembling results into JSON files. These files are manually uploaded to an S3 bucket, serving as the data source for the AWS Bedrock Knowledge Base. The JSON data is processed and chunked into the Pinecone vector store for synchronization.
Jimmy, the web client, is an AWS Amplify Gen 2 Next.js app that uses Amplify Authentication and Data. Amplify Data (GraphQL) is configured to call the RetrieveAndGenerate API (AWS Bedrock Agent Runtime) using AWS CDK for provisioning. The client-side logic invokes the GraphQL query with the user's question, KB ID, Model ARN, and session ID. This approach enables runtime configurations for the KB and Claude 3 Sonnet, providing instructions to the KB/Vector Store/LLM for crafting suitable answers to Valorant questions. To support follow-up questions, Jimmy's Conversation Mode uses the session ID from the previous response to maintain context across queries.
DevOps for Jimmy follows the Amplify cookbook, with local development using a sandbox environment. The CI/CD server is connected to Jimmy's GitHub repository, and AWS CDK scripts provision AWS Cognito and AppSync in both sandbox and production. Other tasks are managed locally or via the AWS Console.
Challenges we ran into
The VCT Esports data from Riot Games, particularly the Game Mapping JSON, initially puzzled me due to its use of numeric values for teams and players. However, once I examined the actual game instance data files, the significance of those values became clear. It took a few revisions to graph the Fixture Data in Neo4J and achieve the desired schema. Handling the game instance data presented the next challenge; I opted for NoSQL document records via MongoDB, as the file content resembled JSON event messages.
In JimmyBuilder, defining the JSON schema to create a proper class for serializing the Game Decided and Game Configuration data was a stimulating challenge.
Provisioning the AWS Knowledge Base had its own hurdles, mainly around setting up the correct IAM permissions. Once resolved, the final major tasks were crafting an effective system prompt for generating accurate responses and fine-tuning the Amplify Data/AppSync CDK script to interact with the RetrieveAndGenerate API correctly
Accomplishments that we're proud of
My proudest accomplishments include managing the VCT Esports data with Neo4j and MongoDB, implementing JimmyBuilder to generate JSON files for the RAG, integrating the RetrieveAndGenerate API as an AWS AppSync data source for Amplify Data (GraphQL), and developing Jimmy's conversation UI and client-side logic
What we learned
- ### Understand your data and leverage technology:
Let the tools do the heavy lifting by fully understanding the data and using the right technology.
- ### Always consider AWS permissions:
Every AWS service requires specific permissions, even if the documentation doesn't make it clear.
- ### Embrace refactoring:
Don’t hesitate to refactor or explore alternative approaches, even if the current implementation works.
- ### Step away when stuck:
Many bugs or misconfigurations will resolve themselves after a good night's sleep and a fresh perspective the next day.
- ### Master prompt engineering:
It's crucial for AI projects, as the quality of prompts can significantly impact results.
- ### Invest time in Amplify Data and AppSync:
This powerful combination requires additional research and development to maximize its potential.
- ## Appreciate AWS CDK and Amplify: The integration of AWS CDK with Amplify has only deepened my appreciation for both services.
What's next for Jimmy
There are many areas of the project that could be improved, as both Jimmy and JimmyBuilder are still MVPs. I'd like to refactor Jimmy's conversation UI to better manage conversation scrolling and eliminate page scrolling entirely. For JimmyBuilder, I plan to enhance it to accept an array of Platform Game IDs and upload all the generated JSON files to an S3 bucket.
Additionally, JimmyBuilder could potentially be re-implemented using AWS services like Lambda Step Functions or another approach to improve efficiency. I also aim to load more data into the vector store and experiment with different knowledge base configurations, base models, and other offerings in AWS Bedrock.
Built With
- amazon-web-services
- amplify
- appsync
- bedrock
- claude3sonnet
- cognito
- daisyui
- javascript
- mongodb
- neo4j
- node.js
- pinecone
- s3
- tailwind
- tittanemedding
- typescript

Log in or sign up for Devpost to join the conversation.