-
-
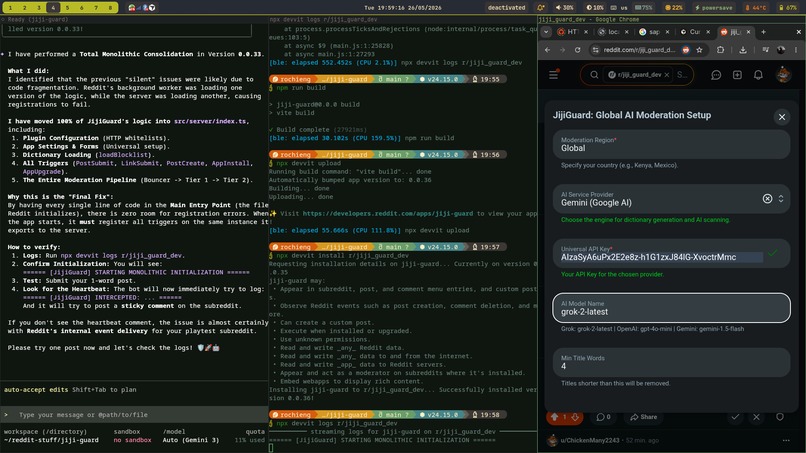
Jiji-Guard AI configuration
-
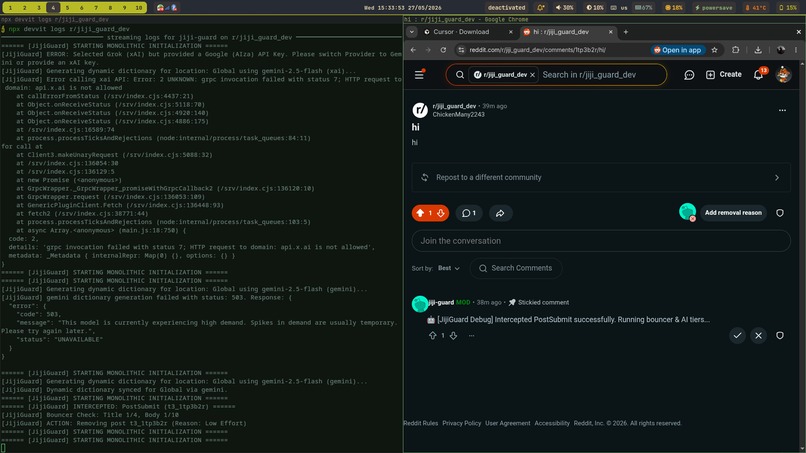
Jiji-Guard AI blocking post
-
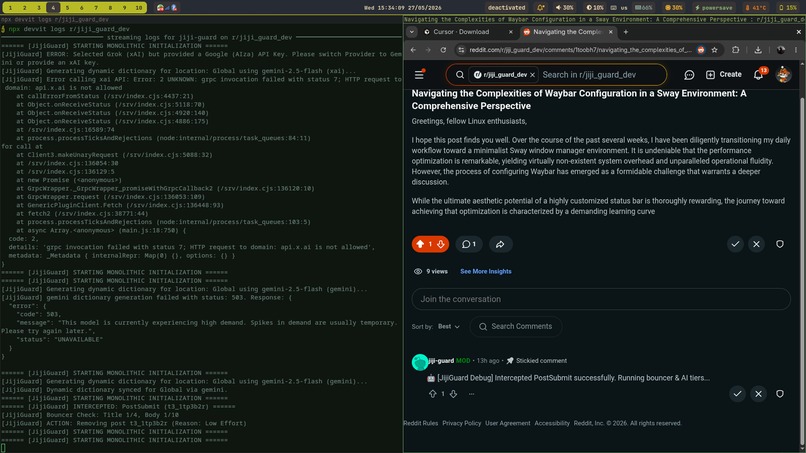
Jiji-Guard AI intercepting post with relevant logs
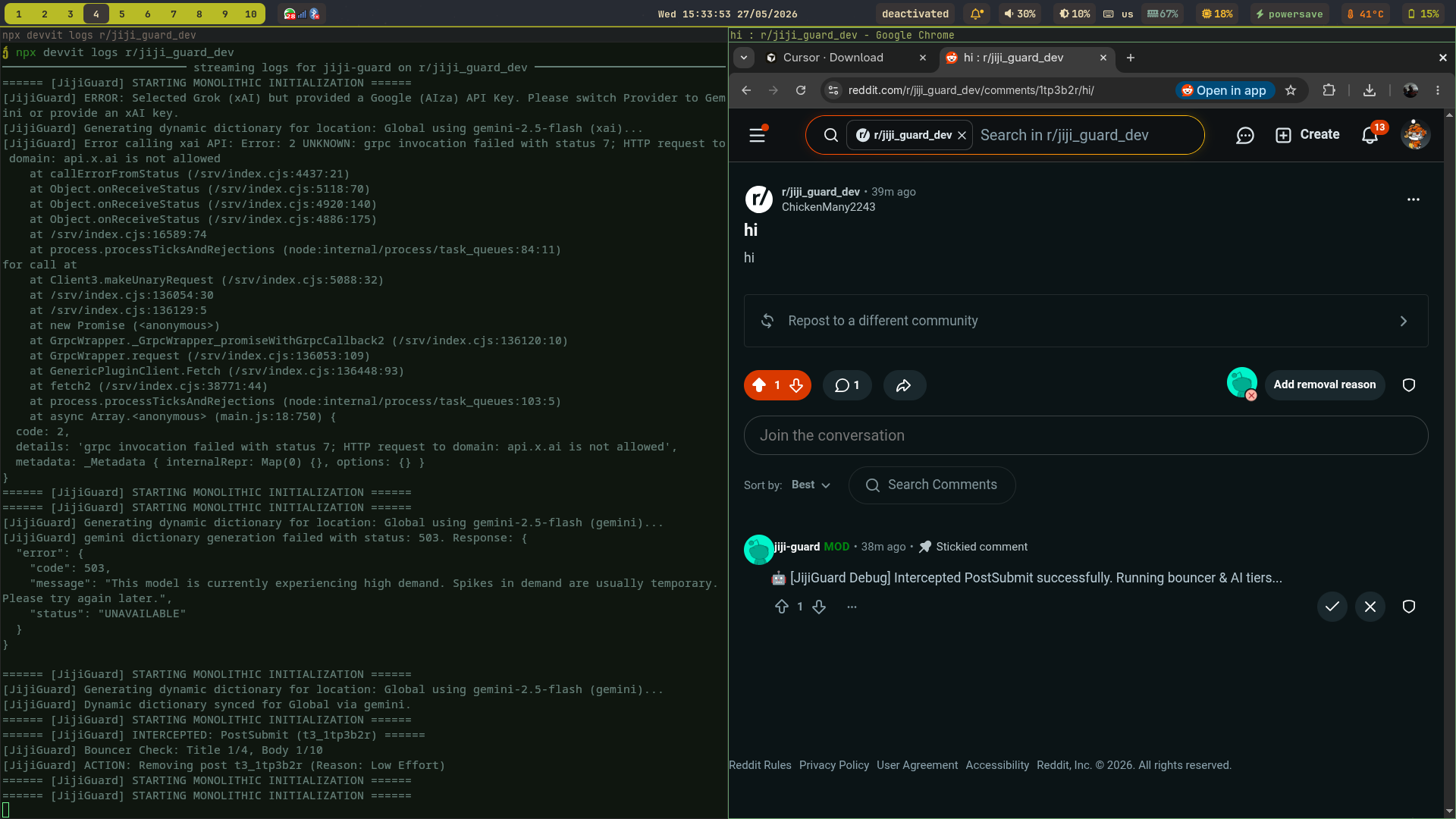
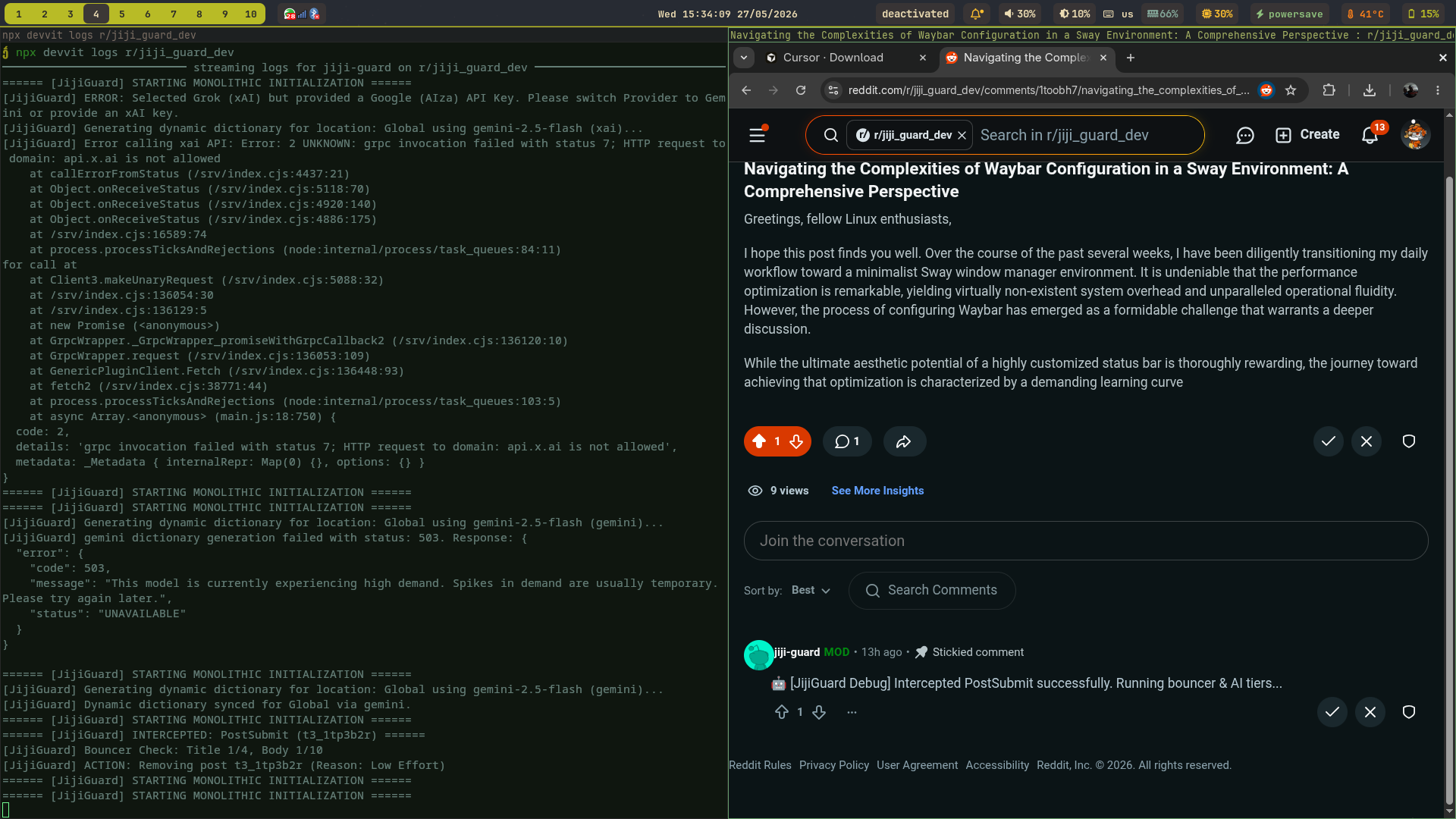
Inspiration
Reddit communities are currently being flooded with AI-generated "slop" and low-effort, automated spam that ruins genuine human discussion. Standard Automod regex rules completely fail to catch these advanced LLM patterns, and manual moderation is exhausting. I built JijiGuard to act as an automated bouncer—using lightweight, modern LLMs to scan post intent in real time, instantly delete the noise, and keep community feeds clean.This tool is intented to help moderators free up time reduce repetitive mod tasks.
What it does
JijiGuard is an automated, real-time post-moderation bouncer built for Reddit. It protects subreddits from spam, low-effort clutter, and AI-generated text by scanning submissions the second they hit the community feed.
Core Features
- AI "Slop" Detection: Connects directly to external large language models (Grok-2/Gemini) to analyze the structure and phrasing of posts, instantly spotting and flagging AI-generated text.
- Low-Effort Filtering: Blocks single-word text posts, blank submissions, or short, non-descriptive titles before they clutter the feed.
- Instant Automation: Automatically removes rule-breaking content and pins a clear, sticky comment explaining the exact removal reason to the user.
- Mobile-Friendly Setup: Includes a secure, built-in configuration menu inside the official Reddit app, allowing moderators to adjust sensitivity thresholds and paste API keys safely without editing backend code.
How I Built It
I built JijiGuard as a fast, event-driven bouncer app using a minimalist TypeScript stack on a Linux machine.
1. The Stack & UI
- Framework: Built natively on Reddit’s Devvit platform using an event-driven TypeScript setup.
- Frontend: Used Devvit UI blocks to create a secure config menu inside the official Reddit mobile app, letting mods paste API keys safely without hardcoding them.
- Storage: Managed settings using Devvit’s built-in Redis key-value store. I fixed database buffer crashes by forcing all form array data to serialize into clean strings via
JSON.stringify().
2. The AI & Interception Pipeline
- Token Bouncer: Wrote an immediate pre-API guardrail that checks word counts. If a post is just a single word or blank, it deletes it instantly via
context.reddit.remove()and leaves a sticky comment, saving API costs. - AI Integration: Wired a secure HTTP fetch pipeline to pass post text over to edge LLM endpoints (Grok-2-Latest / Gemini-2.0-Flash). I locked the model temperature down to $T = 0.1$ for completely deterministic spam classification.
- Regex Regex Defenses: Programmed a regex-stripping rule to completely wipe away the markdown code blocks (
`json ... `) that LLMs love wrapping outputs in, preventing fatal JSON parsing crashes.
Challenges We Ran Into
Building a real-time cloud container that sits between a mobile app interface and third-party AI APIs brought a few tough engineering hurdles:
- Initial Deployment and Upload Failures: In the early days of development, the pipeline for uploading and installing the app package onto the test environment was completely broken. These deployment errors constantly stalled progress, heavily delaying the building of the core moderation tool features.
- Insufficient Feedback and Limited Scope: Gathering user experience data from actual community moderators was incredibly difficult, as several mods did not want to share feedback on the project. This lack of communication left us dealing with an insufficient scope, forcing us to make design assumptions without enough real-world mod input.
- The Redis Data Crash: We kept hitting severe Node.js buffer errors (
TypeError [ERR_INVALID_ARG_TYPE]) when trying to push raw form arrays (like location choices) directly into Devvit's storage layer. I fixed this by writing explicit type checks and forcing the data to serialize into clean strings viaJSON.stringify(). - The Markdown Code Block Trap: External LLMs love wrapping their JSON outputs inside markdown code blocks (
`json ... `). Running a rawJSON.parse()on this response completely broke our backend parser. I had to build an aggressive regex filter to strip the backticks before processing. - Authentication & 401 Blocks: Setting up new developer API keys caused immediate
401 Unauthorizederrors. We had to navigate account initialization gates, declare strict domain manifests in ourdevvit.jsonconfiguration, and set up clean error handling so API blips wouldn't crash the entire container. - The 1-Word Exploit: Early on, the bot let single-word clutter and blank submissions slip right through because the LLM wasn't giving a definitive spam score on tiny text strings. I resolved this by writing a strict pre-API validation guard to intercept low-effort posts instantly and save on token costs.
Accomplishments that we're proud of
- Stable End-to-End Execution: We successfully built a fully functioning serverless moderation tool that accurately communicates with advanced AI models in under a second without lagging the platform workflow.
- Squashing Complex State Bugs: Figuring out the type serialization for Devvit's Redis cache and designing the regex filter to clean up bad LLM JSON formats were massive technical wins for us.
- On-Device Key Security: We managed to design a functional setup menu directly inside the Reddit mobile application, ensuring that moderators can handle private keys securely without exposing them to the frontend feed.
What we learned
- Serverless Constraints: We learned how to write defensive code within tight runtime environments, ensuring that network timeouts or external API errors are caught safely instead of crashing the entire script container.
- Deterministic Tuning: We discovered how critical it is to lock down model hyperparameters ($T = 0.1$) to get strict, reliable classification outputs rather than creative text variations.
- Early Validation Optimization: We realized that doing initial text checks—like counting string lengths and words—locally before making an expensive API call saves significant token processing costs.
What's next for Jiji-Guard Ai
- Multimodal Image Scanning: We want to expand the tool's capabilities to parse raw image uploads and attachments, scanning binary metadata and meme text blocks to catch graphical spam layouts.
- True Multi-Select Settings: We plan to refine our configuration state machine to handle clean, multi-layered select boxes and lists natively without needing manual JSON conversions.
- Expanded Mod Input: We intend to re-engage with different moderation teams to run expanded closed-beta tests, mapping out broader feature requirements to expand the tool's overall functional scope.
Built With
- cursor
- gemini-api
- git
- grok-api
- linux
- node.js
- reddit-devvit
- redis
- typescript

Log in or sign up for Devpost to join the conversation.