-
-
Landing_Page
-
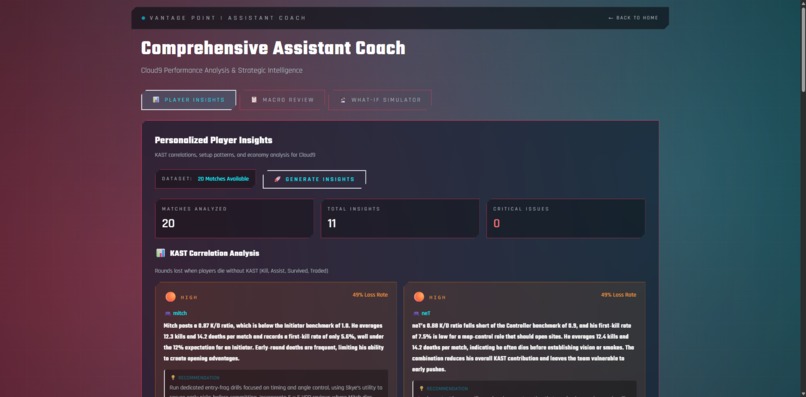
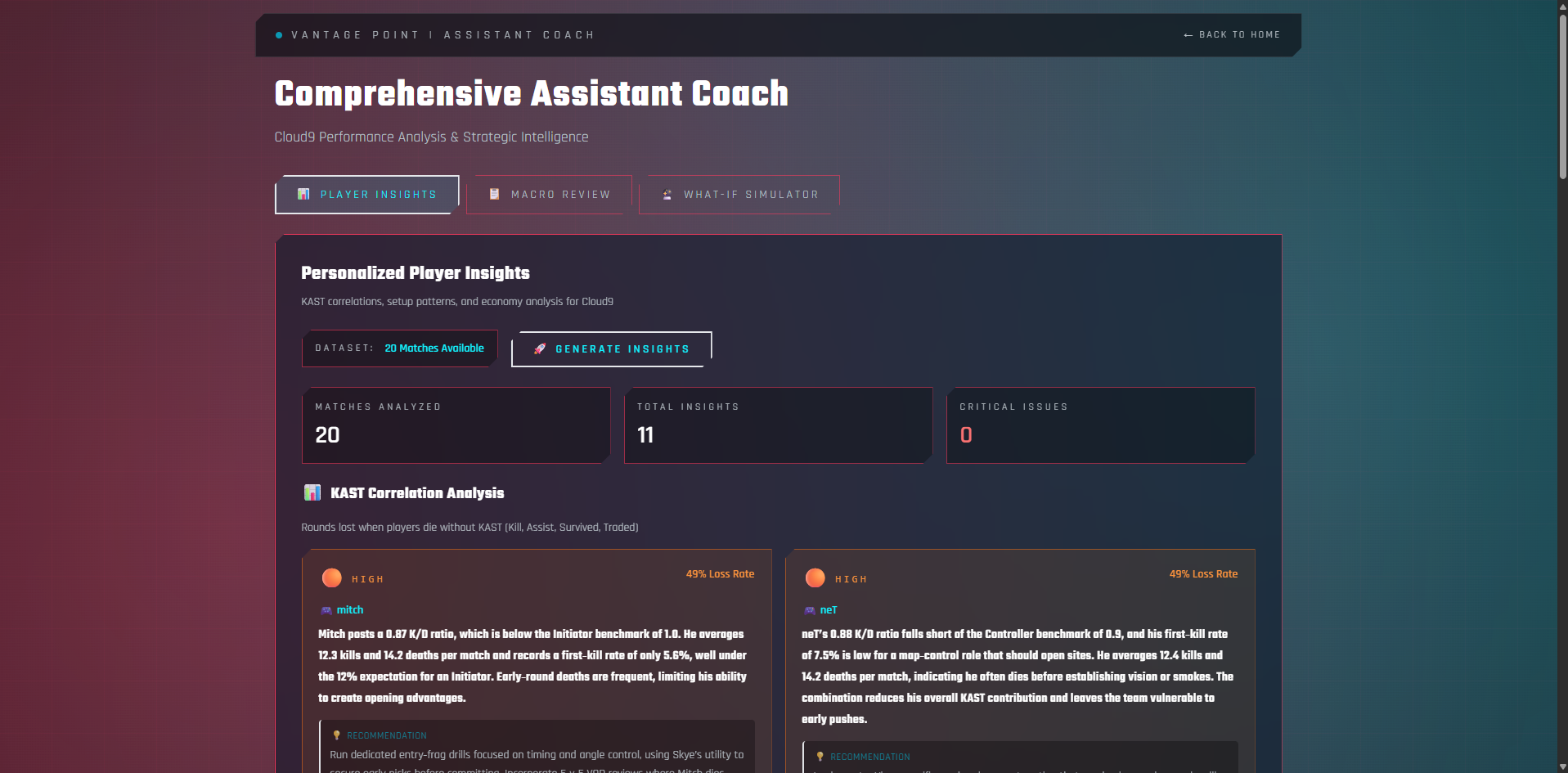
Coach_Review
-
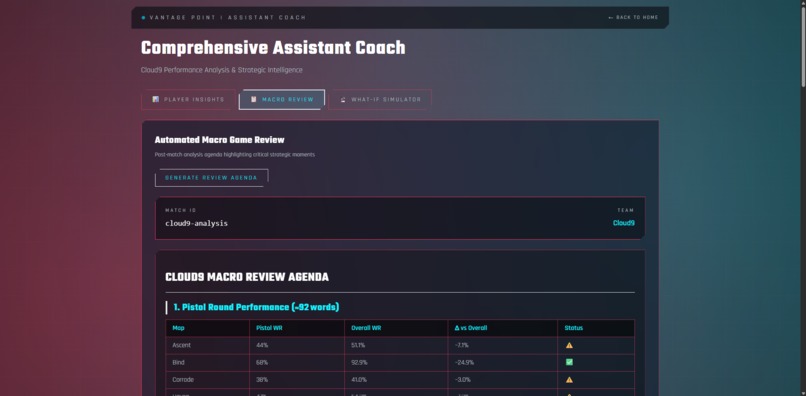
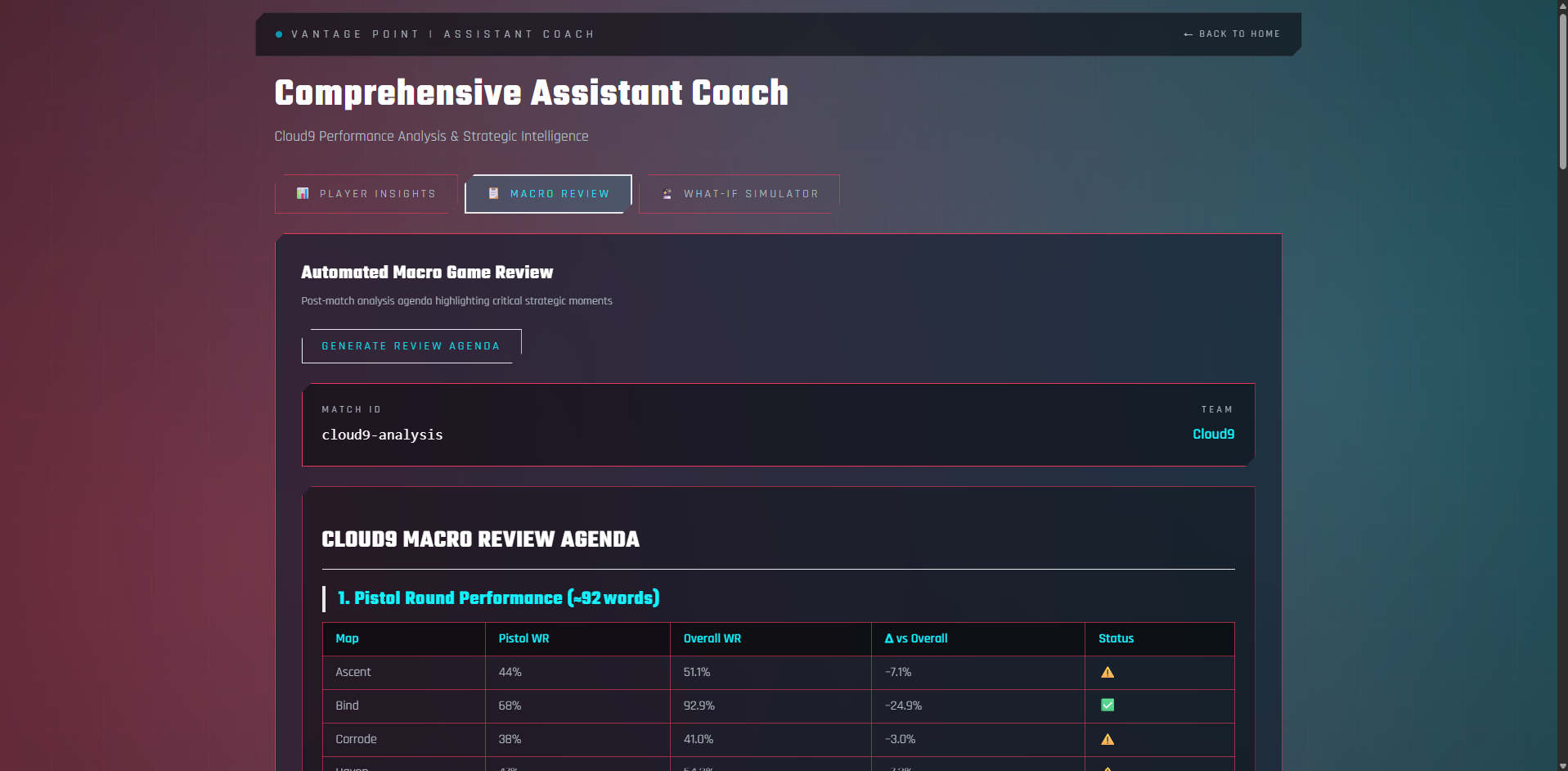
Coach_Macro_Review
-
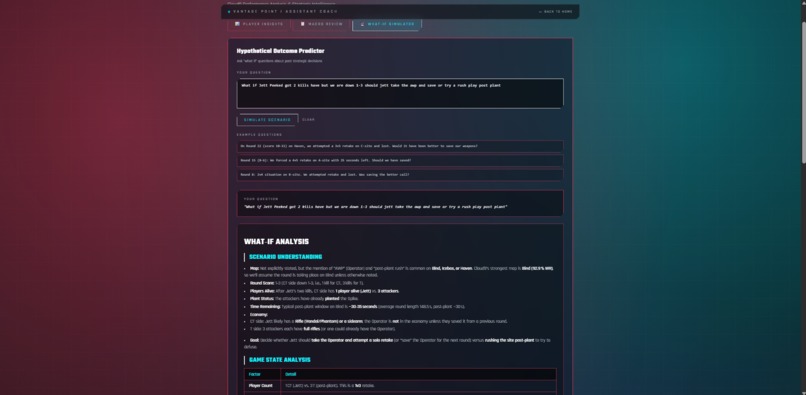
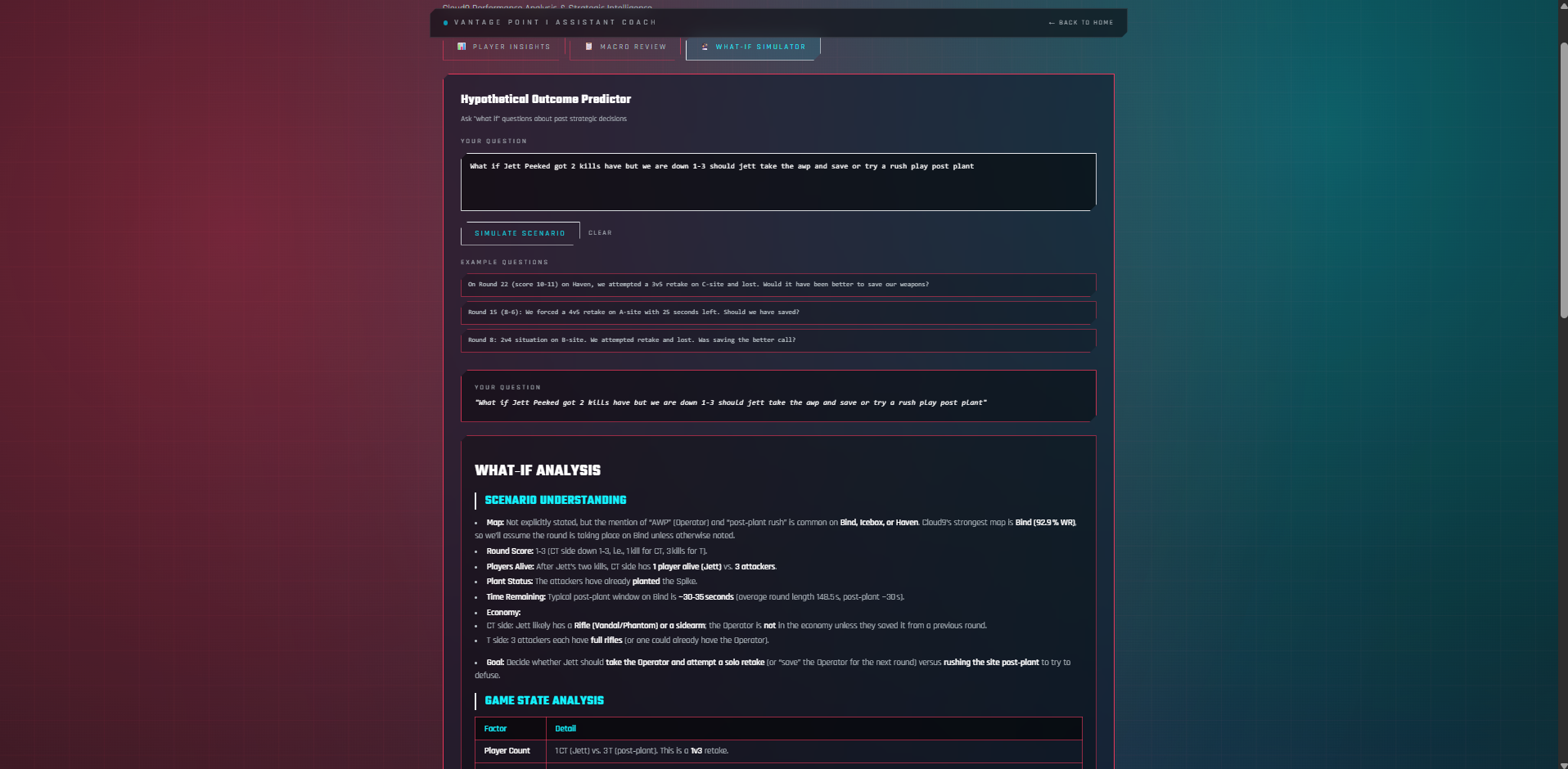
Coach_Predictor_Page
💡 Inspiration
The modern gaming landscape is flooded with fragmented information. Players often find themselves switching between tabs—watching slow-paced YouTube videos, scrolling through outdated Reddit threads, or searching disjointed Wiki pages just to find a single specific strategy for VALORANT. We asked ourselves: What if there was a "Google" for VALORANT that actually understood game mechanics and context? Inspired by the need for instant, high-level coaching, we built JettRag to democratize access to pro-level knowledge.
🤖 What it does
JettRag is an AI-powered, context-aware coaching assistant built specifically for VALORANT players. It utilizes Retrieval-Augmented Generation (RAG) to ingest a vast library of professional guides, map layouts, and patch notes.
Instead of giving generic links, JettRag allows players to ask complex questions like "How do I hold A-site on Ascent against a double-Duelist comp?" or "What is the optimal eco round reset strategy?" The system retrieves the exact relevant text segments from its knowledge base and generates a concise, accurate answer in seconds, acting as a personal data-driven analyst.
⚙️ How we built it
We architected a robust RAG pipeline focused on speed and accuracy.
- Knowledge Base Creation: We developed web scrapers using
BeautifulSoupandScrapyto ingest data from high-quality strategy sources (VALORANT Fandom, RunGG, Pro Guides). We cleaned the data to remove ads and navigation clutter. - Vectorization & Storage: We used
SentenceTransformers(HuggingFace) to convert the text into high-dimensional embeddings. These were stored in a FAISS vector database for lightning-fast similarity search. - The Brain (LLM): We integrated LangChain to orchestrate the retrieval and generation process. By utilizing Groq's high-speed inference with the Llama-3-70b model, we ensured responses were not only accurate but incredibly fast, mimicking a real-time conversation.
- Interface: We built a responsive, chat-style frontend (using Next.js) that feels like a modern messaging app, making the interaction seamless.
🚧 Challenges we faced
- Data Chunking Strategy: One of the hardest parts was determining how to split long strategy guides. If the chunks were too big, the answers were generic; if too small, they lacked context. We experimented with
RecursiveCharacterTextSplitterto find the optimal window size for map-specific strategies. - Hallucination Control: Early versions of the AI would confidently invent mechanics that didn't exist. We mitigated this by strictly enforcing the "Retrieval" aspect in RAG—ensuring the LLM always grounded its answers in the retrieved text chunks rather than relying solely on its training data.
- Latency: Real-time advice needs to be instant. Optimizing the vector search and reducing the token count passed to the LLM were crucial to keep the response time under 2 seconds.
🧠 What we learned
We learned that the future of domain-specific AI isn't about training massive models from scratch, but about curating high-quality data and coupling it with efficient retrieval mechanisms. We gained a deep understanding of semantic search and how embedding models capture the meaning behind queries like "anti-strat" versus "defense." JettRag taught us that in gaming, context is everything—knowing when to use an ability is just as important as knowing what the ability does.
Built With
- framer-motion
- groq
- next.js
- react
- typescript

Log in or sign up for Devpost to join the conversation.