-

reasons for negative feedback
Inspiration
It is a data-feeding world and we need to sift through data and get what we need and we could use. Sentiment and topic analysis are the tools that used for companies to collect and analyze the customer feedback in order for them to better understand the data trend and make associated plannings for improvement.
What it does
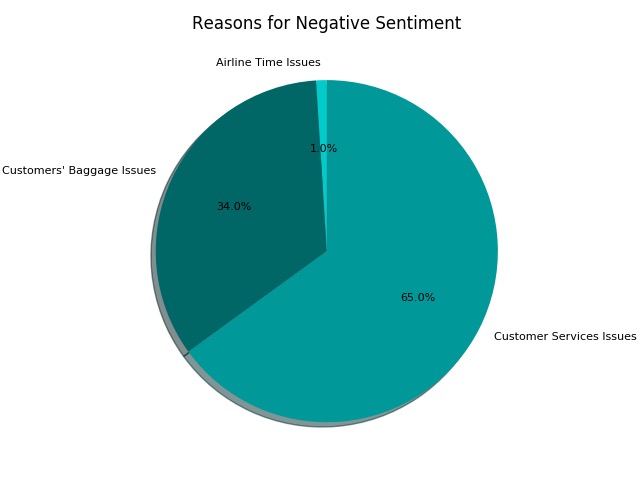
The data we use is scraped online directly to ensure that the data we get are fresh and insightful. By running through about 5000 training examples, we are able to get the topic of each predicted answer very right with the help of machine learning and topic analysis. In doing so, we make full use the twitter API online to achieve the goal like data cleaning. In the end, we are able to visualize it to get a pie chart about the costumers' feedbacks on twitter and provide a clear results to the company. The graph is about the major reasons for the company's negative sentiments and how they are distributed through out the social media online.
How I built it
First of all, we did research on how to do a sentiment analysis on customer feedback which leads us to data mining, pre-processing data, data classifying, and data analyzing. For the data mining, we wanted to go for web-scraping the keywords from the website directly. However, we found out that Twitter has its own API for sentiment analysis and we requested for approval for twitter developers. Once we got the consumer key, we downloaded a dataset with customer feedback with the keyword, twitter ID, and its associated address and wrote the relevant ones into a new corpus file. After we extracted the data with the input keyword, we started to clean the data by tokenizing and removing punctuations of the text. After classifying the data using Naive Bayes classifier and then predict for the new dataset, we were able to get the labels (positive/negative/neutral) and get the accuracy result for the model.
Challenges I ran into
For web-scraping, it was hard to filter the the meaningful data we need and convert from HTML format to CSV file. For the labels, in this case, we only introduce the sentiment label in the training which is classified into positive, negative, and neutral. It was difficult to create more labels/topics through the comments from each twitter ID.
Accomplishments that I'm proud of
We are able to use topic and sentiment analysis to classify different topics. We classified it by airline time issues, costumers' baggage issues, costumers service issues. After having obtained the percentage of each of the component, we are bale to plot it down and have a better visualizaion about the results for the customers of our project.
What I learned
We have learned that except for apply functions for web scraping, we could use APIs directly which solves a lot of hassles for us. By implementing machine learning algorithms and and topic and sentiment analysis, we get a better understanding of how machine learning is applied to the business planning and operations. Sentiment and topic analysis methods are something totally new to us and we had to learn from scratch off the algorithms and the applications.
What's next for JetBlue Sentiment Analysis
We hope to create more labels such as year, season, time, region, country, etc. In doing so, we can have a more detailed and specific picture about how customers feel about this company or under which strategies that Jetblue has made, we can find out about the business trends.


Log in or sign up for Devpost to join the conversation.