-
-

Landing Page
-

Page will show user requirements, such as contacts, comp floor
-
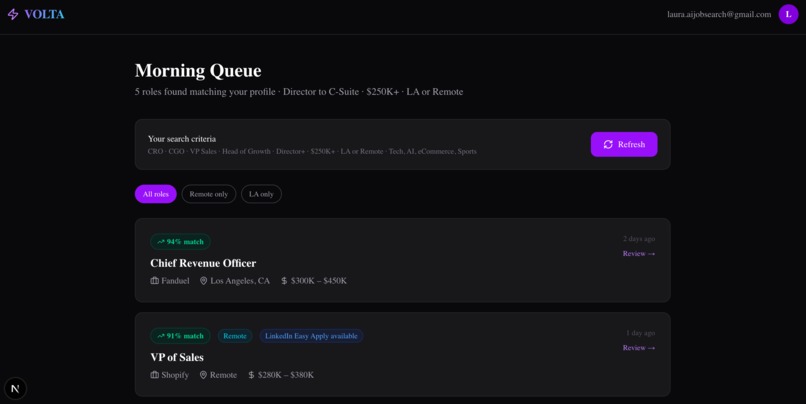
Daily list of new roles to review and "approve" to get customized deliverables
-
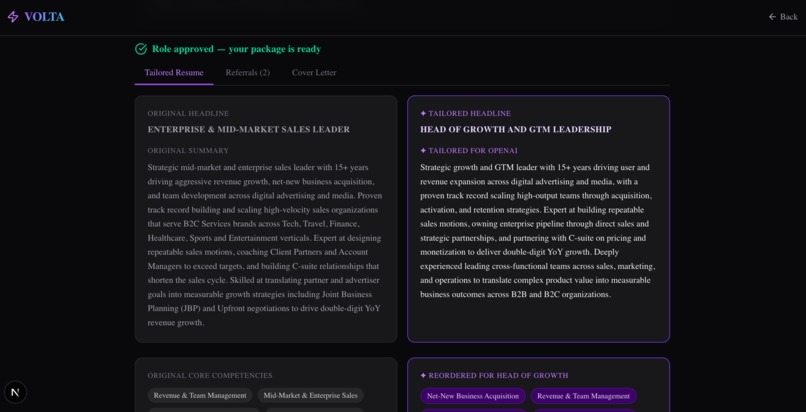
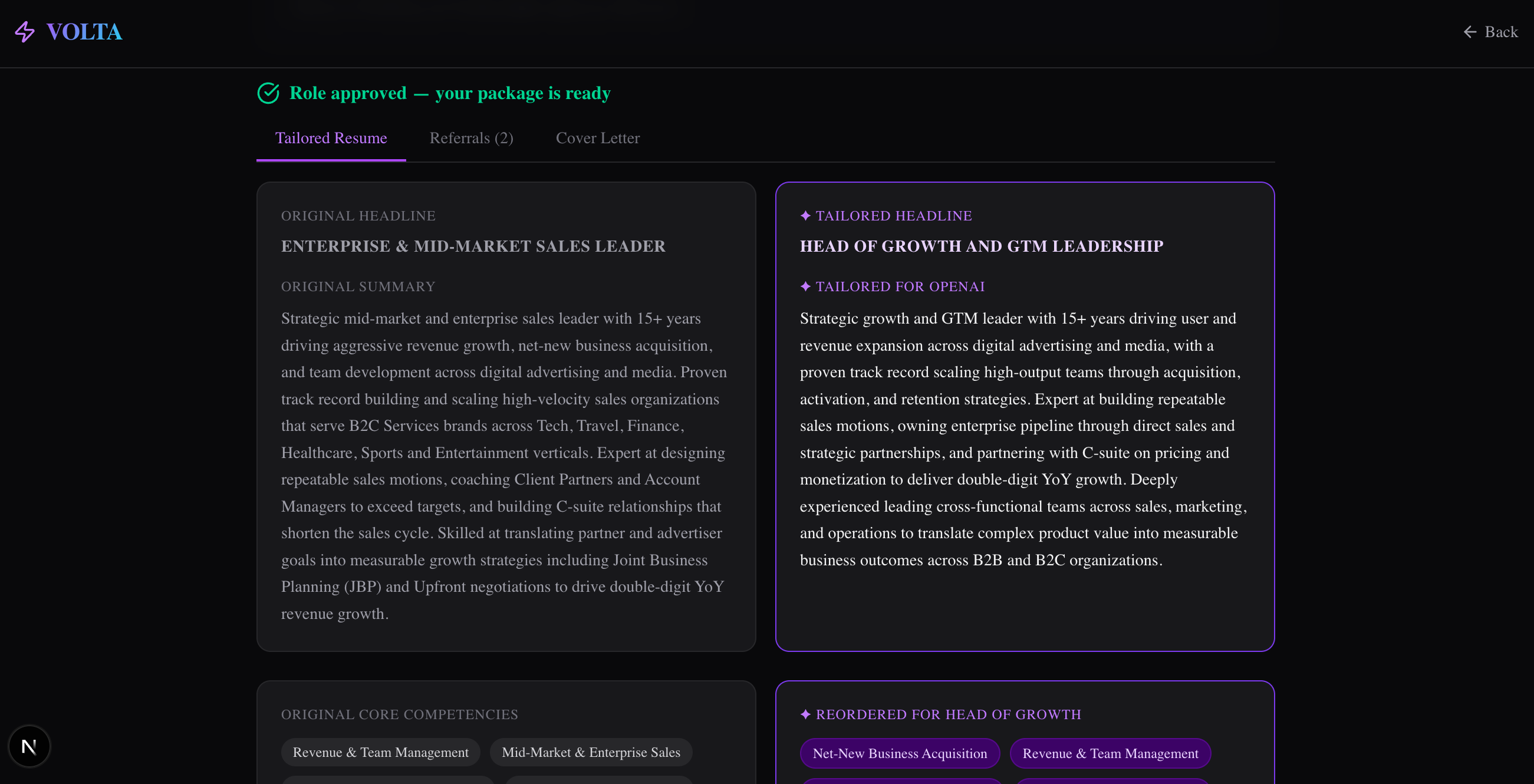
Tailored resume sections
-
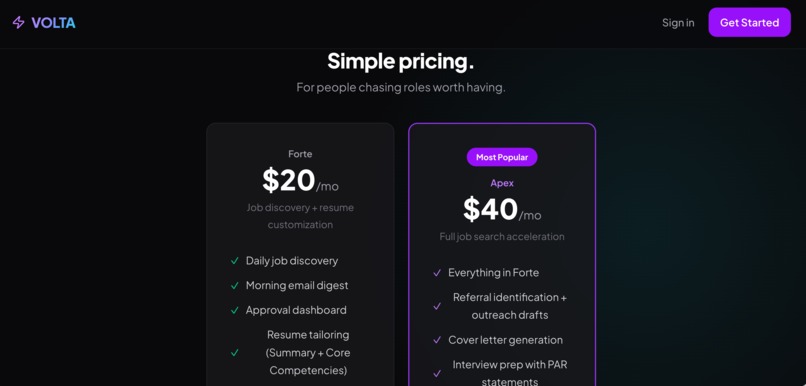
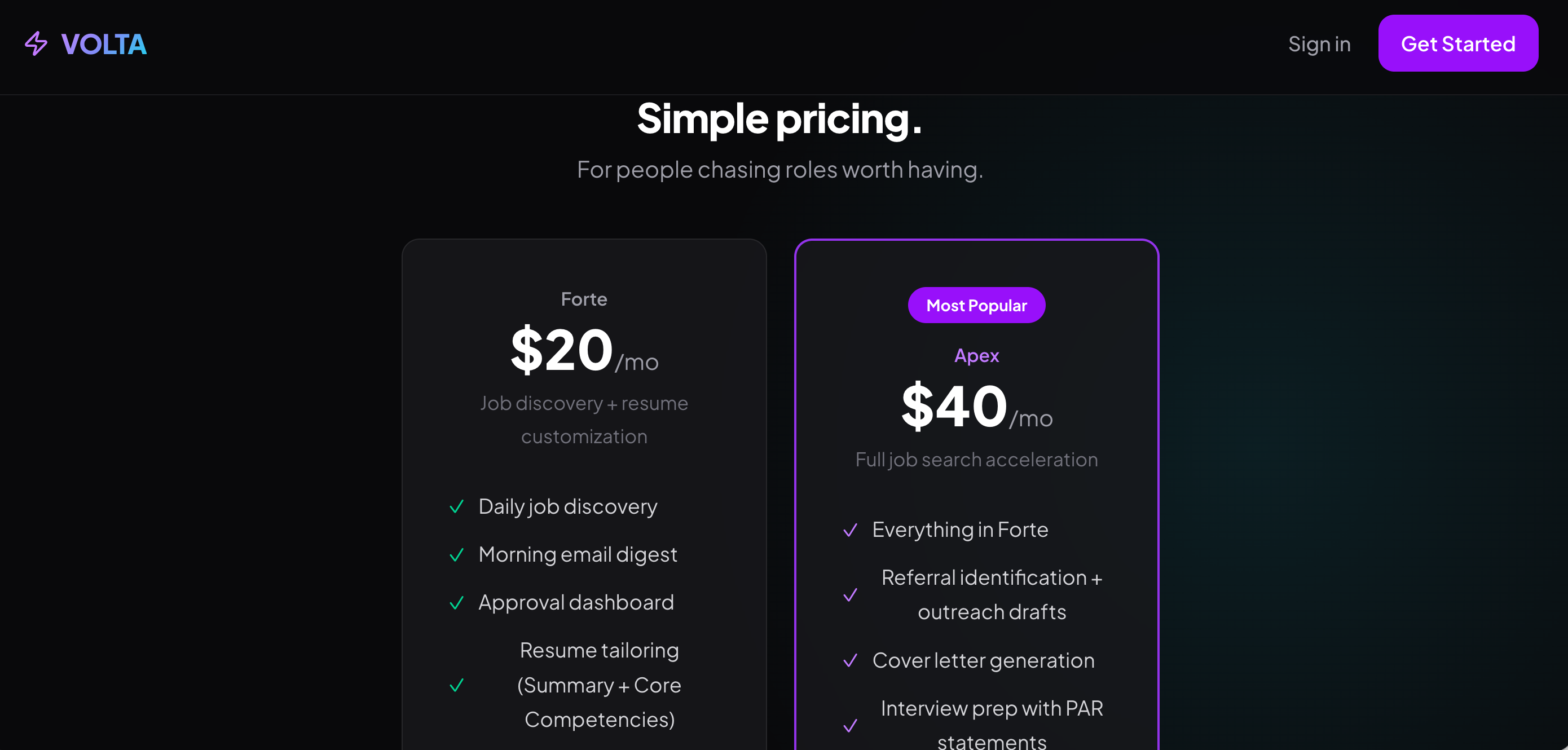
Pricing for Placeholder only


VOLTA — Your Career, Running While You Sleep
What Inspired Me
I'm a senior sales executive actively navigating a job search, and the process is exhausting in a way that has nothing to do with the actual work. Every morning I was manually scanning LinkedIn, copying job descriptions into a document, rewriting my resume summary by hand, and trying to remember which of my 2,489 LinkedIn contacts might know someone at a target company. It was hours of administrative overhead before I could even think about the strategic part — deciding which roles were actually worth pursuing.
I kept thinking: this is exactly the kind of repetitive, pattern-matching work that AI is built for. A senior executive's time should go toward relationships and decisions, not copy-paste and reformatting. VOLTA is the tool I wished existed. An autonomous agent that runs while I sleep, finds the right roles, tailors my materials, surfaces my warm contacts, and hands me a ready-to-review package every morning.
How I Built It
VOLTA is a full-stack Next.js application built on the App Router with API routes handling all AI and data processing server-side. The core of the product is a multi-step AI pipeline powered by Claude (claude-sonnet-4-6) via the Anthropic API.
The job discovery engine queries the JSearch API across LinkedIn, Indeed, Glassdoor, and other boards, then scores each role against a custom fit algorithm: title match (40 pts), industry alignment (30 pts), location (20 pts), and compensation floor (10 pts). Only roles above threshold make it to the queue.
The resume tailoring engine takes the job description and calls Claude to rewrite exactly three sections — the Headline, Summary, and Core Competencies — while leaving all experience bullets, education, and industry leadership completely locked. The constraint was intentional: AI should amplify what's true, not fabricate new credentials. Claude reorders and reframes; it never invents.
The referral engine parses my real LinkedIn connections export (2,489 contacts spanning 1,772 companies), fuzzy-matches against each target company, ranks contacts by a seniority score combined with GTM relevance, and drafts a personalized outreach message for each warm contact found.
The document generator uses the docx npm package to produce a fully formatted .docx resume on
demand — tailored headline, tailored summary, reordered competencies, and all original experience bullets
preserved exactly — ready to submit.
The UI is built with Tailwind CSS and shadcn/ui components, using Plus Jakarta Sans for typography and a dark purple/cyan gradient design system that reflects the "premium autonomous agent" positioning.
What I Learned
The biggest technical lesson was learning to think in constraints when prompting Claude. My first instinct was to ask the AI to "improve the resume." That produced hallucinations — invented metrics, fabricated titles, entirely new bullet points. The breakthrough was making the prompt surgical: here are the exact three fields you may touch, here are the exact fields you may not, here is why. Once I gave Claude a precise mandate instead of a vague one, the output quality went from unreliable to consistently excellent.
I also learned how much product design lives in the data model. The decision to separate "editable
sections" (Headline, Summary, Competencies) from "locked sections" (Experience, Education, Leadership)
wasn't a UI decision — it was a trust decision. Users need to be able to hand a recruiter this resume and
stand behind every word. That constraint shaped everything: the prompt engineering, the .docx generation
logic, the in-app comparison view.
On the infrastructure side, I learned that building real tools with real personal data (an actual LinkedIn CSV, an actual resume, real job board APIs) forces a level of robustness that mocked data never demands. Edge cases only appear when the data is messy and human, which is always.
Challenges I Faced
The hardest challenge was building something real, not a demo. I made the deliberate choice to use my actual resume, my actual LinkedIn network, and live job board APIs rather than seed data. That meant every part of the system had to actually work — fuzzy company matching on 2,489 real names, bullet points that reflect real accomplishments, fit scores against real job descriptions. It was slower, but it produced something I could genuinely use the morning after the hackathon.
Prompt reliability was a continuous challenge. Claude's output needs to be valid JSON that maps exactly to the data schema the frontend expects. I had to handle markdown code fences, inconsistent whitespace, and occasional structural variations in the response — all while keeping the prompt tight enough that Claude didn't wander outside its mandate.
Time. I built the entire product — PRD, design system, API integrations, AI pipeline, document generation, and deployment — in a single day with a competition deadline of 11 PM PT. Every architectural decision had to be made fast and made right, because there was no time to refactor. That forced a kind of clarity that's actually useful: if you can't explain why a feature needs to exist right now, it doesn't ship.
VOLTA is live at volta-navy.vercel.app · Source at github.com/sandovalcornell/volta · Built with Claude AI by Anthropic
Built With
- claude
- claude-code
- claudeapi
- github
- next.js+vercel
- shadcn/ui
- tailwind

Log in or sign up for Devpost to join the conversation.