Jevan Rekha — Lifeline
Ask in your own language — type or speak "पटना के पास डायलिसिस" — and get an evidence-attached, distance-ranked shortlist of verified health facilities, answered back in the same language. Then click any facility to see whether it can actually do what it claims, what patients really say, and the safest way to get there.
💡 Inspiration
In India, the hardest part of getting care often isn't the treatment — it's finding the right place to get it. A family in rural Bihar whose relative needs dialysis, cancer surgery, or a NICU bed has no reliable way to know which nearby facility actually offers that service, whether it's public or private, whether it's covered under PMJAY, or how far it really is. The information is scattered across thousands of facility listings — much of it stale, mislabeled, or plotted at the wrong coordinates.
The result is wrong referrals: patients travel hours to a hospital that can't help them, lose precious time in an emergency, or get steered to an expensive private clinic when a free public one is closer. For a kidney patient who needs dialysis twice a week, a wrong turn isn't an inconvenience — it can be fatal.
Two more walls pushed us further. Language — most digital health tools assume English; a grandmother who speaks only Bhojpuri or Tamil can't use them. And trust — the dataset is 10,000 scraped, self-reported facility records, "unverified claims, not ground truth." A glossy listing claiming an ICU means nothing if the data is wrong, the place is closed, or patients describe being turned away.
So we built Jevan Rekha — Lifeline (jeevan rekha = "lifeline"): a multilingual, conversational referral agent that turns "I need X care near me" into a trustworthy, explainable, defensible shortlist — and, because a referral is a decision, we made it answer the questions the other hackathon tracks ask: Can this facility do what it claims? Where are the real care gaps? What in the data can't we trust yet?
🩺 What it does
Jevan Rekha is the Referral Copilot (Track 3) — and it subsumes the other three tracks as evidence behind every recommendation.
The conversational agent (left pane):
- 🗣️ Multi-turn chat — follow-ups ("what about Jaipur?", "only public ones?"); each turn keeps context.
- 📞 Voice-to-voice agent (OpenAI Realtime) — tap Talk and have a real spoken conversation: the
gpt-realtimeagent listens, calls our search as a tool, and reads back the top matches — in the user's own language. Facilities it finds drop into the thread as normal cards. - 🌐 Any Indian language, in and out — type or speak in Hindi, Bengali, Tamil, Marathi, Telugu, romanized, or code-mixed; results come back in the same language. Names, phones, links stay literal.
- 🎯 Semantic match, not keyword match — "renal replacement therapy" finds "dialysis unit"; "open heart bypass" surfaces "CABG".
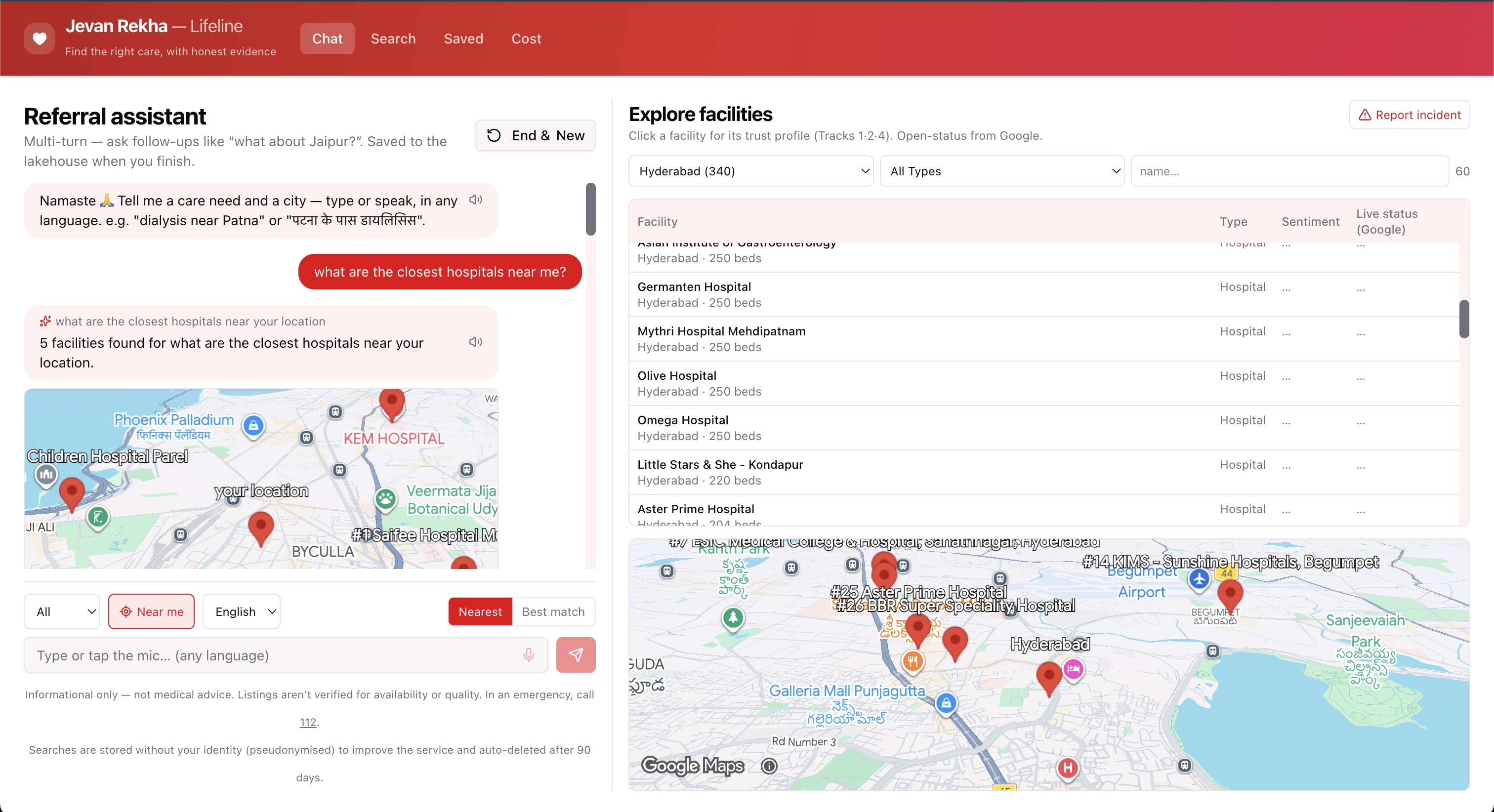
- 📍 Precise "near me" — device GPS → 6-digit PIN → city, with distances from your spot, not a city centroid.
- ✅ Evidence + registry verification — every card cites why it matched and shows a Verified badge for facilities resolved to PMJAY / HFR / NABH registries.
- 🛡️ Healthcare guardrails — emergency escalation (112 / 108), a relevance floor, a medical disclaimer, graceful degradation.
The explore + trust workbench (right pane) — what we added:
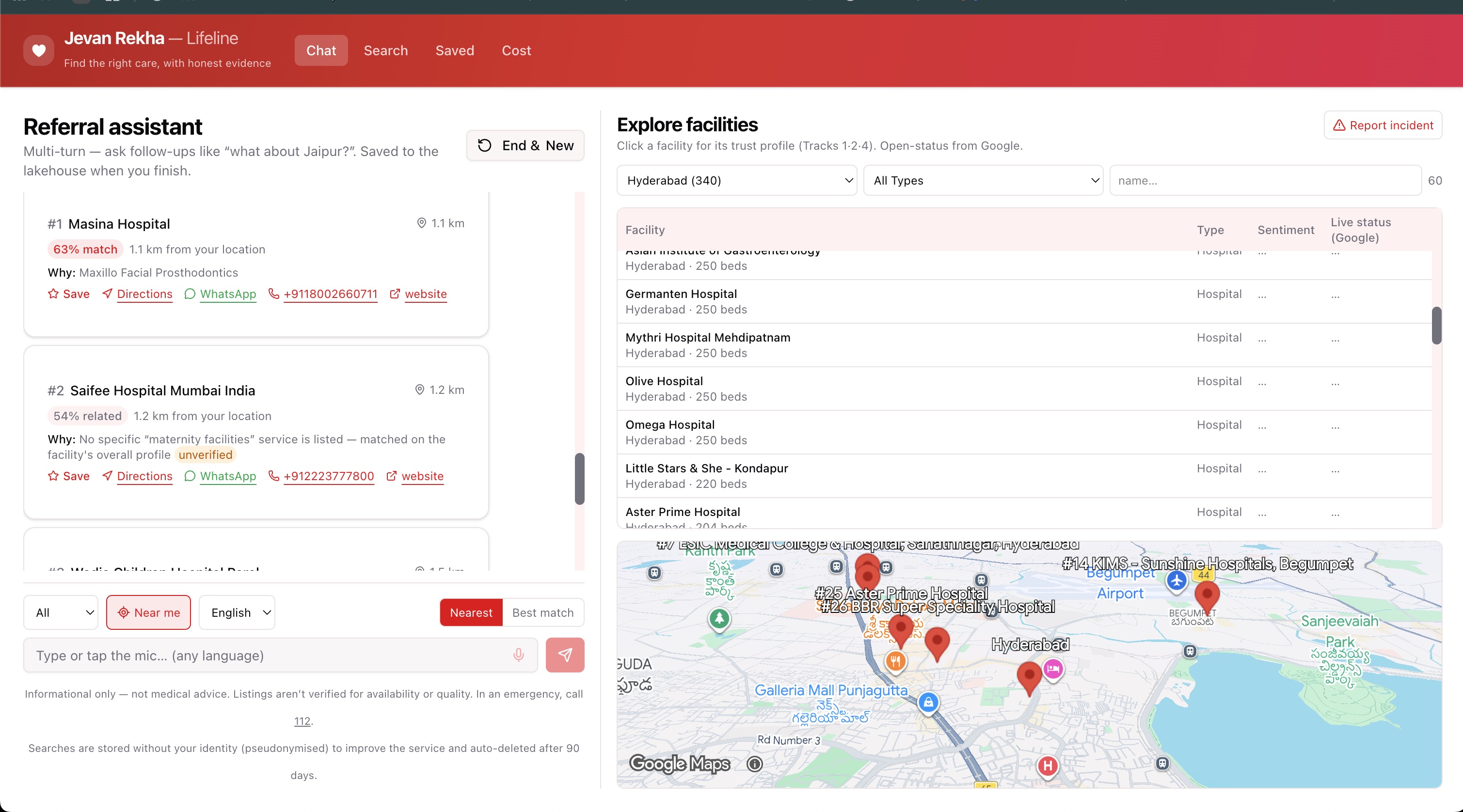
- 🔎 Filterable facility directory — browse by city / type / name, with live "Open now / Closed" + ⭐ rating from Google and a patient-sentiment column on every row.
- 🛰️ Photorealistic 3D map — Google's
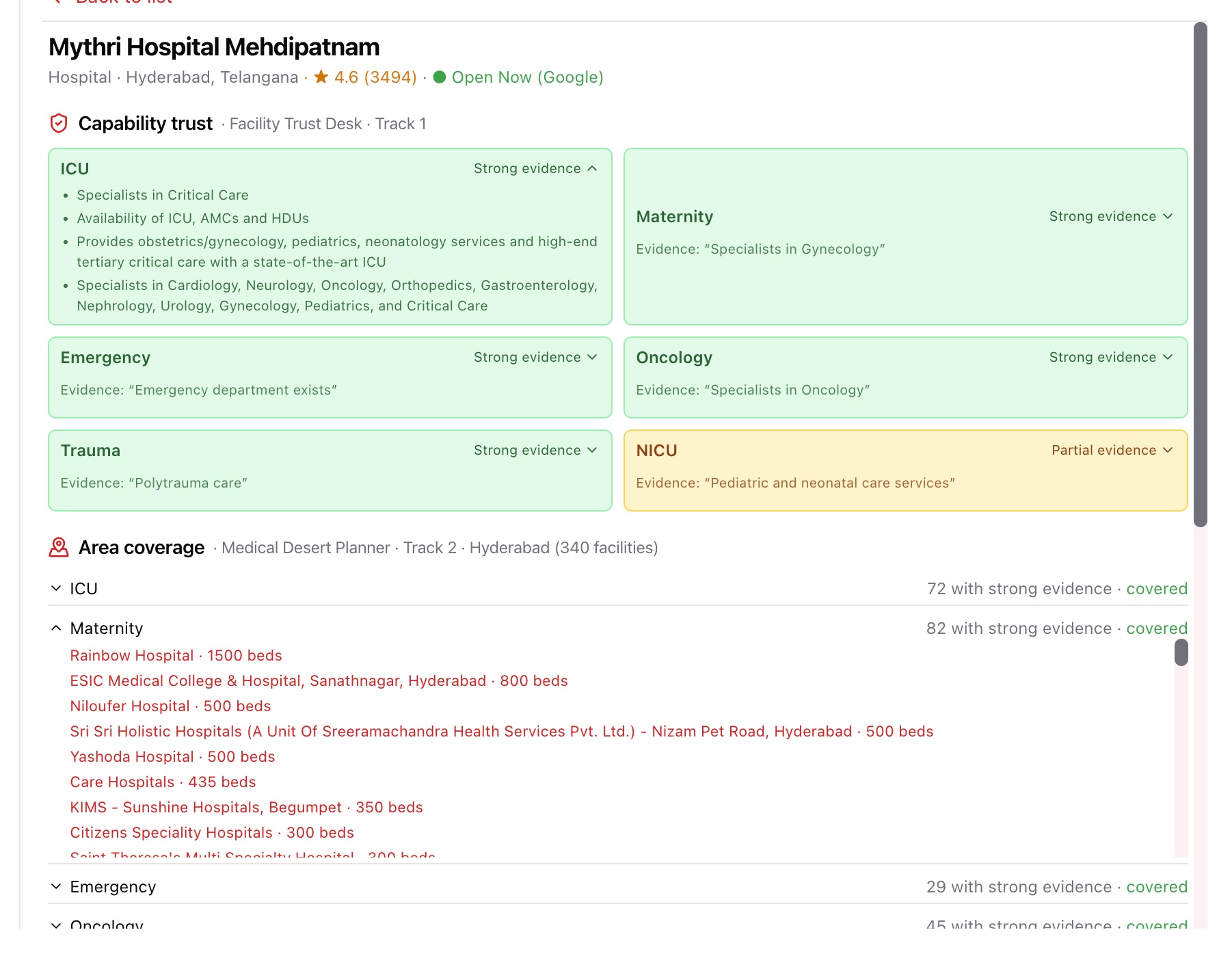
Map3DElementflies into the city and plots facilities in true 3D (automatic 2D Leaflet fallback if the key/API is unavailable). - 🩺 Trust Profile — click any facility for a four-part, drillable dossier:
- Facility Trust Desk (Track 1) — per-capability trust signal (strong / partial / weak / suspicious / no claim) for ICU, Maternity, Emergency, Oncology, Trauma, NICU — each backed by the exact cited evidence (structured claim vs. specialty vs. prose), expandable.
- Medical Desert Planner (Track 2) — area coverage: how many facilities in the city have strong evidence per capability, classified covered / thin / desert — click a row to list the actual facilities, then click a facility to chain into its profile.
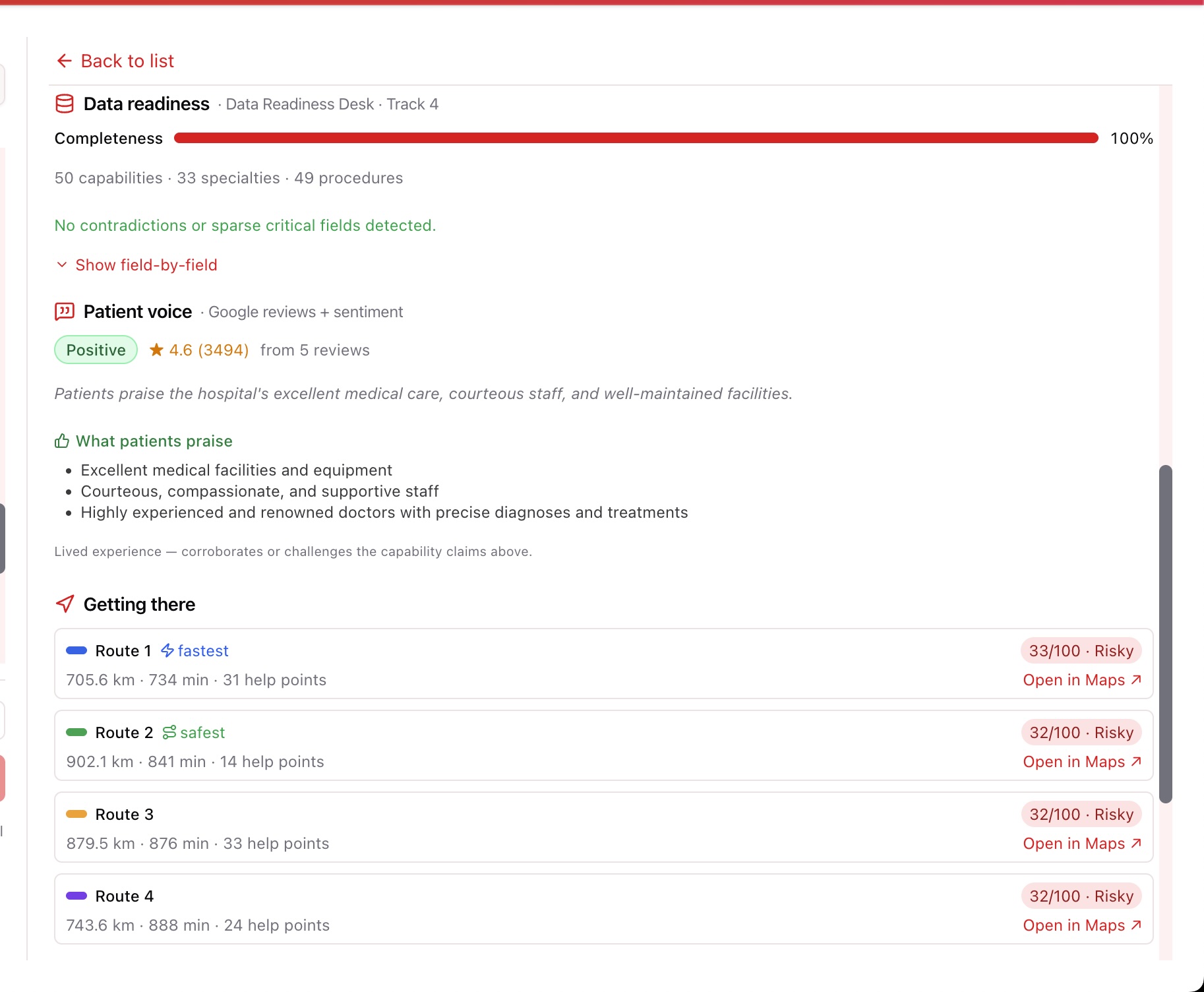
- Data Readiness Desk (Track 4) — completeness %, missing fields, contradictions / suspicious claims, and a field-by-field breakdown.
- 💬 Patient voice — up to 5 Google reviews summarized by an LLM into what patients praise vs what they complain about + an overall sentiment — the lived experience that corroborates or challenges the capability claims above.
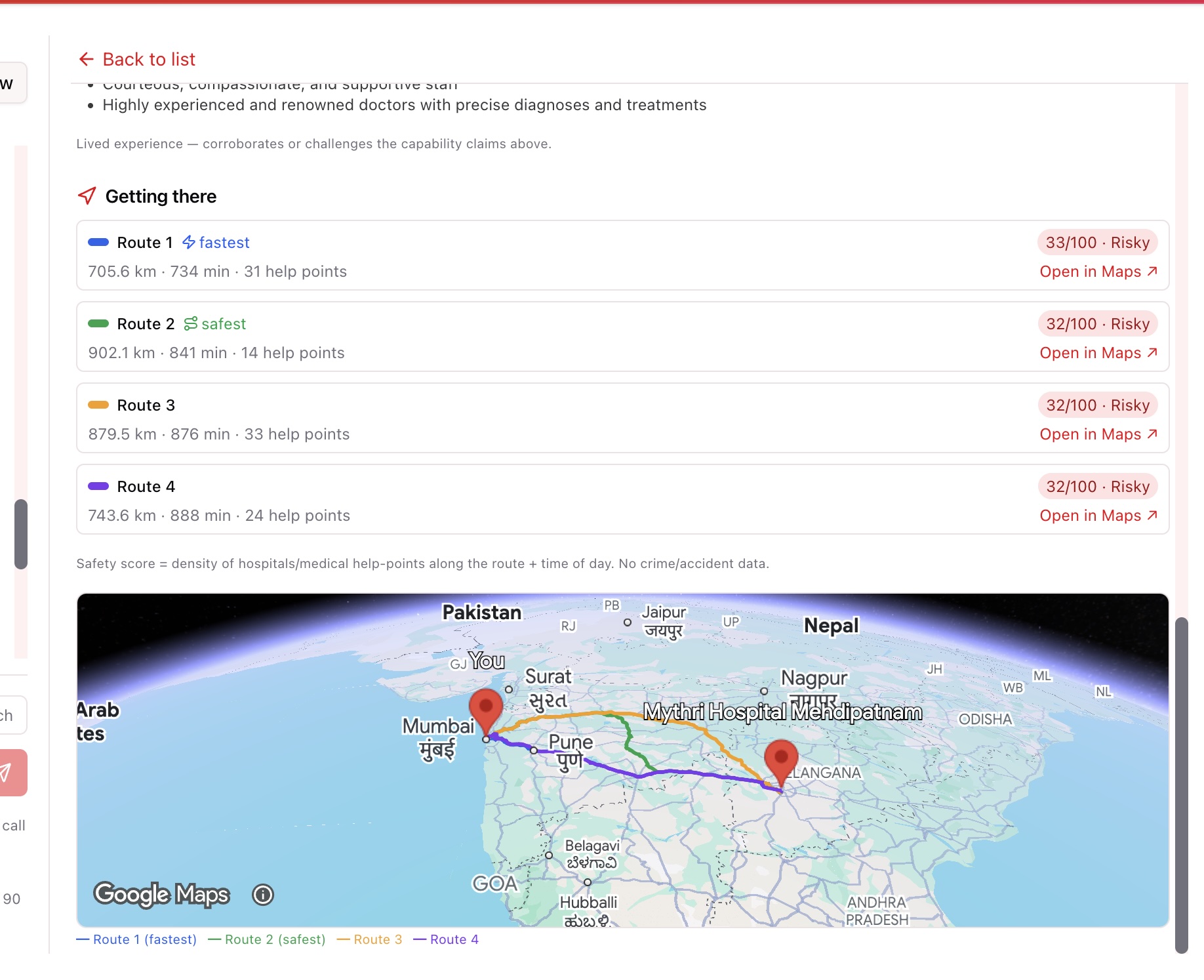
- 🧭 Safety-scored navigation — fastest and safest route alternatives, each scored by help-point density (nearby hospitals/medical) and crowdsourced incident reports, drawn as distinct colored polylines on the same 3D map (not a separate window).
- 🚨 Report incident — crowdsourced safety reports (poor lighting, harassment, unsafe area…) that lower the safety score of routes passing nearby — the system gets safer the more it's used.
- ⭐ Shortlists — save facilities, set a review decision (candidate / contacted / referred / rejected) and a note; everything persists to Lakebase.
- 🔒 Privacy by design & 💰 cost dashboard — pseudonymized identity, 90-day retention, consent notice; a live cost dashboard measured from real Model Serving token usage.
🏗️ How we built it
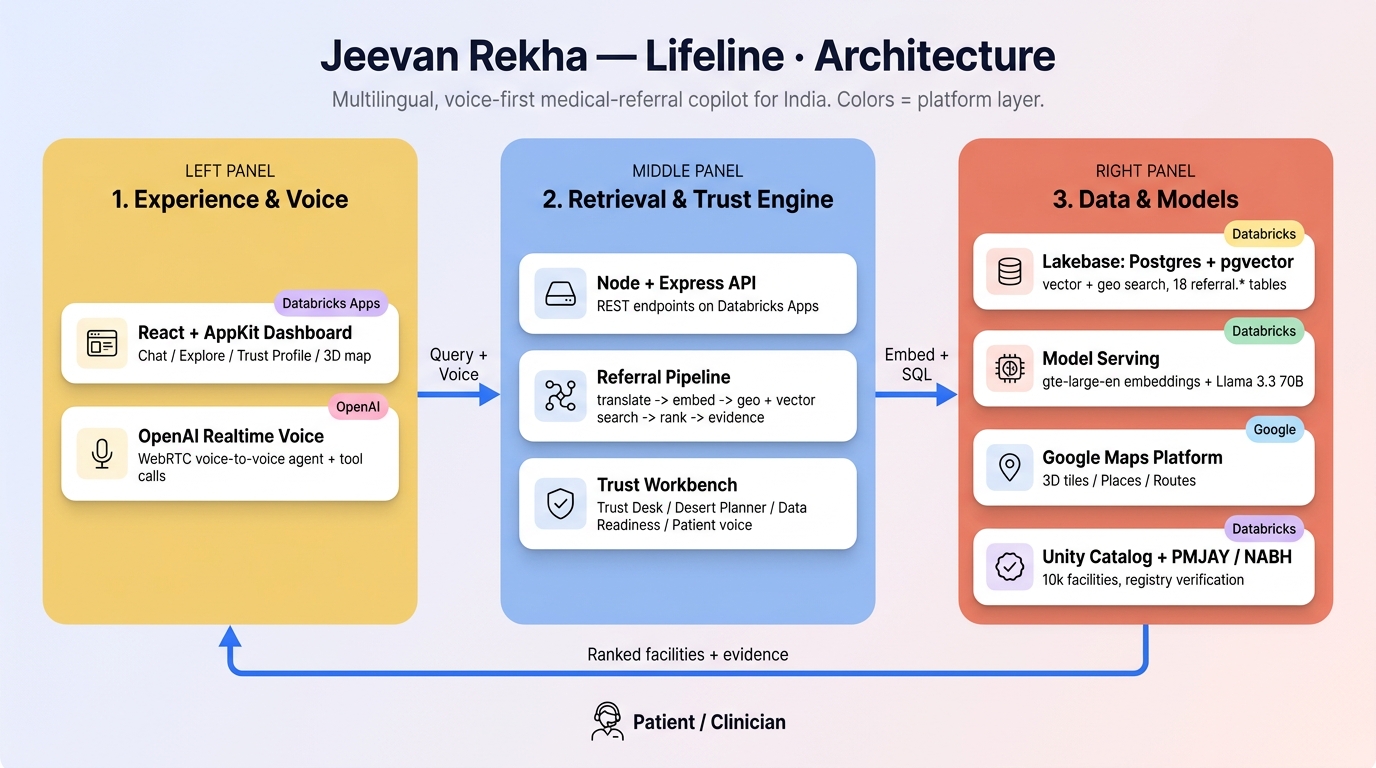
Architecture
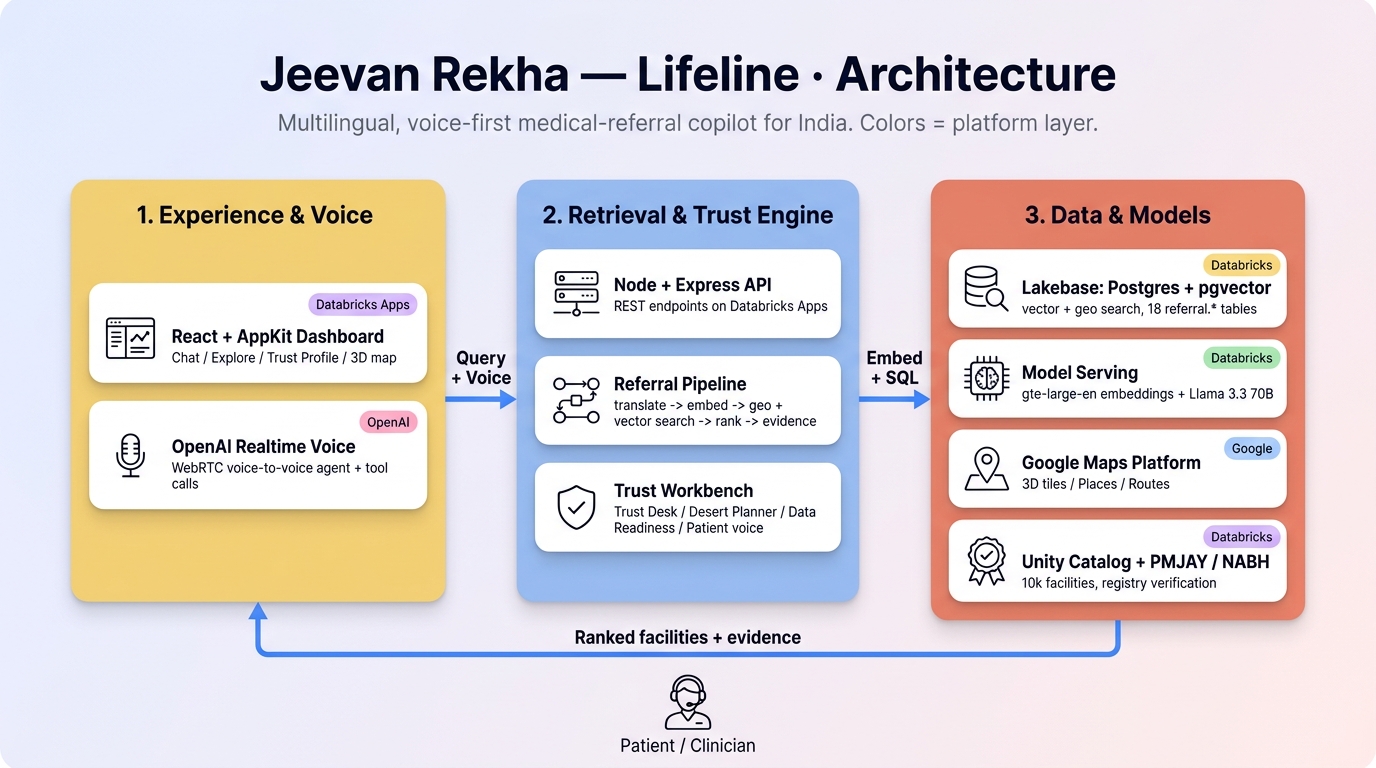
Everything runs on Databricks Free Edition — one app, one database — with a thin Google layer for maps, places, and routing.
- Databricks Apps (AppKit / TypeScript) — a single React + Node app, deployed as a Databricks Asset Bundle.
- Lakebase (Autoscaling Postgres 17 +
pgvector) — the OLTP store and the vector index in one place, across 18referral.*tables (facility + capability/procedure/specialty,facility_vec,facility_geovalidation,facility_verification, conversations, shortlists, usage events, and our additivesafety_incident). - Databricks Model Serving —
databricks-gte-large-enfor embeddings,databricks-meta-llama-3-3-70b-instructfor translation, intent extraction, and patient-review sentiment. - Unity Catalog — the bronze lakehouse source (~10k real facilities) and the long-term conversation archive.
- Google Maps Platform — Photorealistic 3D Tiles /
Map3DElement(the in-app map), Places API (New) (live open-status, ratings, reviews), and the Routes API (alternatives + geometry). - OpenAI Realtime API (
gpt-realtime) — the voice-to-voice agent over WebRTC: the server mints a short-lived ephemeral key (/v1/realtime/client_secrets) so the browser opens the audio session directly to OpenAI without ever seeing the standard key, and the agent calls oursearch_facilitiesfunction tool (which runs the same/askpipeline). The browser Web Speech API remains as a zero-cost dictation/read-aloud fallback.
Retrieval core (the chat): translate-in → resolve origin → embed → semantic+geo search → rank + evidence + verify → localize-out, with a safety/data-quality check gating each stage. The core stays English; multilingual is a thin translate-in / search-English / translate-out wrapper — one English vector space, at most two extra LLM calls. Scoring blends meaning, proximity, and capacity:
score = 0.60·similarity + 0.25·proximity + 0.10·beds + 0.05·doctors
Trust workbench (the explore pane): server endpoints (/browse, /facets, /facility/:id/profile, /coverage, /places, /reviews, /routes, /incident) read the same referral.* tables — geo-validated the same way the chat search is (JOIN facility_geo ON geo_valid) so the two surfaces never disagree. Per-capability trust is computed from facility_capability/specialty/procedure with a shortest-match rule (a clean code like icuAndCriticalCare beats an incidental sentence match) and a suspect-claim guard (a dental clinic can't claim NICU). The safety route score samples ~20 points along each route polyline and counts hospitals (help-points, +) and reported incidents (−) within range, modulated by time of day.
Offline, a Databricks ETL (load_from_uc → embed_facilities → validate_coordinates → verify_facilities) builds the tables, the vectors, the geo_valid flag, and the registry verification.
🧗 Challenges we ran into
- Wrong coordinates. ~8% of source facilities were plotted in the wrong place (a "Noida" hospital landing 500 km away, a Patna site showing "3.9 km" when it was nowhere near). We built a bronze→silver coordinate-validation pipeline: inside-India + within 80 km of the robust city median, plus an optional OpenStreetMap cross-check (≤15 km).
geo_validis what every query filters on — bad points never appear, and they're excluded from origin geocoding too. - The pincode directory lied. India-Post centroids landed in the wrong state (PIN 201301 → "Agartala"), so we dropped it entirely and geocode from the median of validated facilities instead.
- Dirty data nearly killed the data layer. The scraped text contained embedded null bytes (0x00), which Postgres rejects — the first sync died on it. Sanitizing every text column was a prerequisite to serving anything: a Track-4 problem we had to solve before Track 3 could run.
- False-friend evidence. An early matcher cited a "Microbiology **Laboratory" as Maternity evidence (the keyword
labormatchedlaboratory); another cited "cleft lip repairs" for a dialysis query. We added word-aware keywords, a shortest-match rule, and a suspect-claim filter, with honeststrong/partial/weak/suspiciouslabels. - Google's "safest route" doesn't exist. No routing API exposes crime/accident data. We were honest about it: the safety score is help-point density + time of day, and we added a crowdsourced incident layer so reported hazards genuinely lower a route's score — the closest we can get to "safest" without a national crime dataset.
- Photorealistic 3D looked flat.
Map3DElementonly streams 3D tiles when zoomed in; far out it shows a flat vector globe. The fix was a high-tilt fly-to at close range, plus an automatic 2D fallback so a blocked key or alpha-API hiccup never shows a broken map. - Free-tier limits & collaboration. A 512 MB Lakebase cap (we kept the schema lean, dropped lexical matviews on deploy, and skipped HNSW — a sequential cosine scan over ~10k vectors is still sub-100 ms; footprint ≈ 336 MB), a disabled serverless warehouse (re-engineered ETL to be Lakebase-native), and a 3-app workspace cap that meant two teammates kept overwriting one app slot until we moved to a shared git repo.
🏅 Accomplishments that we're proud of
- One app that answers all four track questions. A referral isn't just "where to go" — it's can they do it (T1), is the area underserved (T2), can we trust the data (T4). The Trust Profile makes all three first-class evidence on the facility you're about to act on.
- Claims vs. lived experience. Putting the dataset's claims next to real patient reviews + LLM sentiment is the most honest trust signal in the app — a hospital claiming oncology + trauma sitting at 2.4★ with "patients treated like trash" is exactly the discrepancy a referrer needs to see.
- Trust is the product, not a footnote — evidence citations, registry verification, coordinate validation, suspect-claim filtering, emergency escalation, and honest confidence labels throughout.
- A genuinely immersive 3D experience — flying into the city and drawing color-coded, safety-scored route alternatives directly on photorealistic terrain, all inside the app.
- All on Databricks Free Edition —
pgvectorinside Lakebase means geo-filter + semantic rank + evidence in a single SQL round-trip; no external vector DB, no extra infra, six-plus languages for two LLM calls.
📚 What we learned
- A vector index belongs next to your OLTP, not in a separate service. Putting
pgvectorinside Lakebase made geo-filtering, semantic ranking, and evidence one SQL round-trip — simpler and faster than a dedicated vector DB. - For health data, trust is a feature, not a footnote. Evidence, verification, validation, and patient sentiment did more for credibility than any accuracy bump.
- Wrong data hurts more than missing data. A confidently-wrong "3.9 km," a
labor→laboratoryfalse match, or a null byte in a description each broke trust harder than an empty field — the data-quality layer became the most important part of the system. - Translation as a thin wrapper around an English core gave us six-plus languages for the cost of two LLM calls and zero extra storage.
- Be honest about what you can't measure. Labeling the route as "calmer — help-point density, not crime data" and then crowdsourcing the missing signal was more credible than faking a "safety" number.
🚀 What's next for Jevan Rekha — Lifeline
- A planner-level Medical Desert view — rank the worst-served districts nationally (supply vs. demand) instead of per-city, using NFHS-5 district health indicators for demand-side risk.
- A dataset-wide Data Readiness dashboard — profile the whole 10k (missing-field rates, contradiction counts, highest-leverage records for human review), not just per-facility.
- Bulk PMJAY/HFR ingestion and procedure-level verification — cross-check the cited service against the registry's verified services.
- Swap LLM sentiment for
ai_analyze_sentimentonce the SQL warehouse is wired, and add MLflow tracing for span-level observability, rate limiting, and cost caps. - Grow the crowdsourced incident layer into a true safety graph, and add outbound WhatsApp referral hand-off for community health workers.
🛠️ Built with
databricks · databricks-apps · appkit · typescript · react · vite · node.js · express · lakebase · postgresql · pgvector · pg_trgm · databricks-model-serving · gte-large-en · llama-3.3-70b · unity-catalog · google-maps-platform · map3delement · places-api · routes-api · openai-realtime · gpt-realtime · webrtc · web-speech-api · leaflet · openstreetmap · zod · databricks-asset-bundles
🔗 Try it out
Built With
- databricks-lakehouse
- google-3d-hyperrealistic-maps
- open-ai-realtime-voice-agents
- postgresql

Log in or sign up for Devpost to join the conversation.