-
-
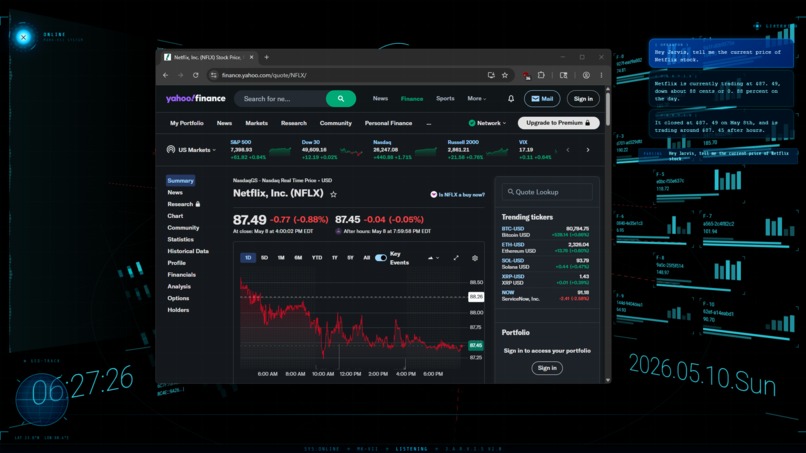
JARVISION in action
-
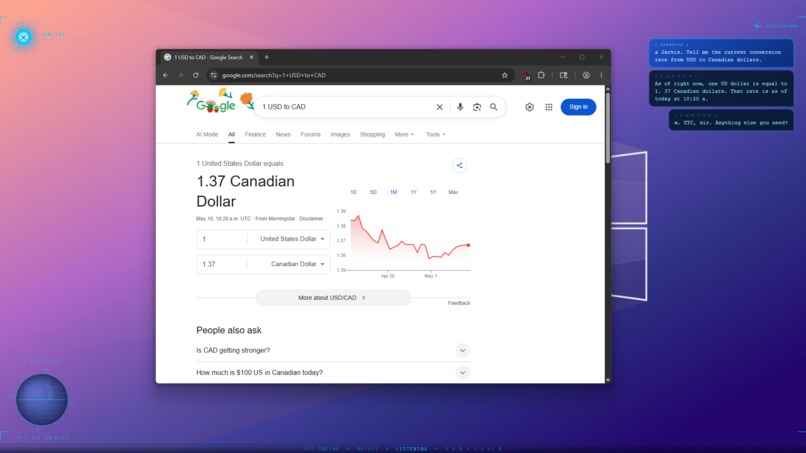
-
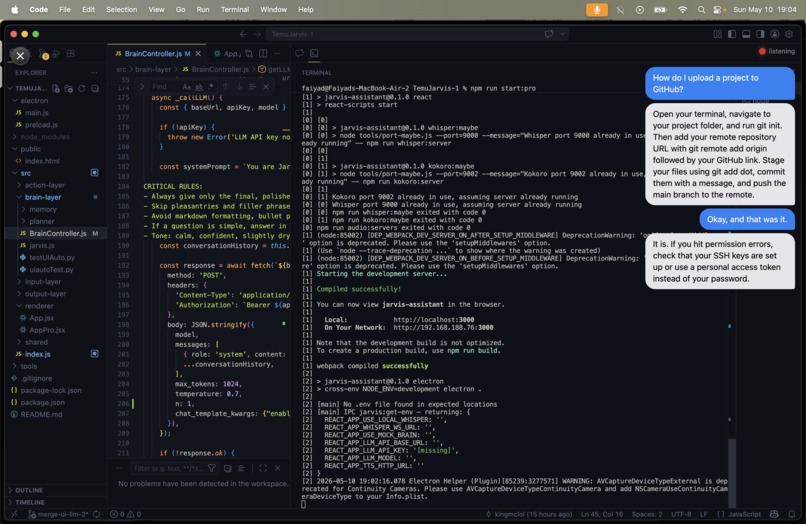
Different UI
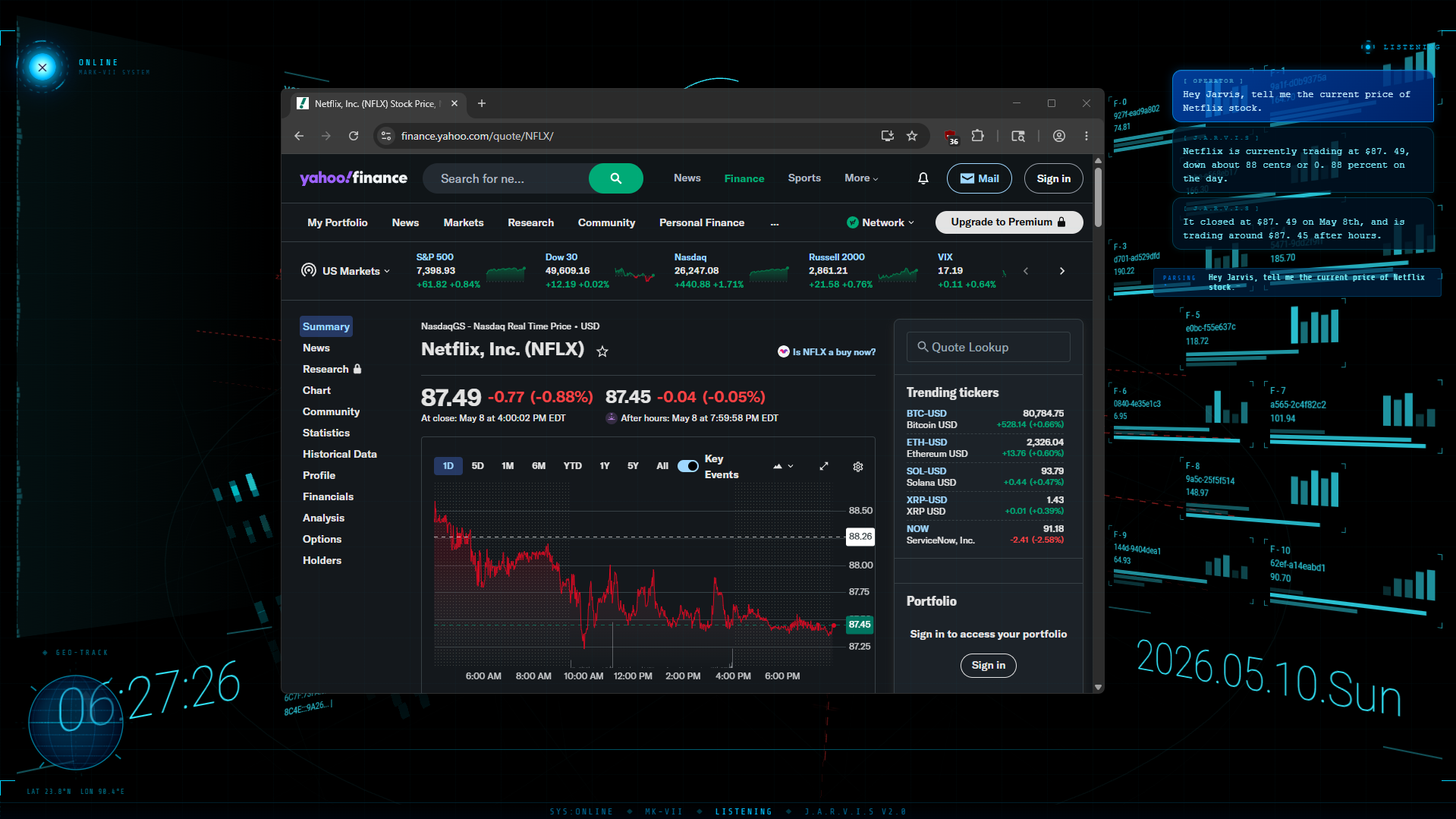
Inspiration
Imagine having J.A.R.V.I.S. — not as a fantasy, but as open-source infrastructure anyone can run. This project advances SDG 4 (Quality Education) by lowering barriers to information through voice-driven, hands-free access; SDG 8 (Decent Work) by automating routine tasks so people focus on higher-value work; SDG 9 (Industry & Innovation) by demonstrating open, modular AI infrastructure that doesn't rely on expensive proprietary platforms; and SDG 10 (Reduced Inequalities) through multimodal input — voice, gesture, and text — that adapts to users across different physical and cognitive abilities.
What it does
JARVISION is a multimodal desktop assistant with four main capabilities:
| Capability | How |
|---|---|
| Voice input | Say "Jarvis" to wake it, then speak your command. Powered by OpenAI Realtime API. |
| Browser automation | Gives multi-step instructions to a vision model using IBM watsonx that plans and executes web tasks inside a real Chrome window via Hermes. |
| Local speech output | Responds in natural speech using Kokoro ONNX — fully on-device, no cloud, no latency. |
Example flow:
- You say "Jarvis, search YouTube for cats"
- JARVISION parses the intent, generates a step plan, and shows it on screen
- Pinch to confirm
- Jarvis opens YouTube, clicks the search box, types "cats", and presses Enter — narrating each step aloud
How we built it
| Component | Technology |
|---|---|
| Desktop shell | Electron + React |
| Voice I/O | OpenAI Realtime API (bidirectional WebSocket) |
| Intent planning | GPT-4o — text → structured action plan JSON |
| Browser automation | Playwright + Flask + Qwen 3.5 4B via Featherless API (Jarvis server on port 5001) |
| Vision planning | Vision model using IBM Watsonx |
| Speech-to-text | Whisper.cpp + custom WebSocket wrapper |
| Text-to-speech | Kokoro ONNX (runs locally) |
| Containerization | Docker |
Challenges we ran into
The main challenge we faced was integrating all of our services into a single cohesive system. Our application relied on multiple components—including the voice service, text-to-speech (TTS), speech-to-text (STT), and the Electron desktop environment, which introduced complexity when connecting everything together. In particular, handling CORS issues and ensuring that all endpoints would communicate reliably on different operating systems was difficult.
Accomplishments that we're proud of
We successfully built a working MVP that integrates all core components of the system. The application captures audio, processes it through STT, generates responses using LLMs, and returns output via TTS, forming a fully connected pipeline across multiple services. We are most proud that our assistant is actually able to directly interact with and respond to on-screen content, demonstrating the practical potential of our project.
What we learned
Through this project, we gained hands-on experience working with new technologies such as Electron for desktop applications, Kokoro for voice processing, Whisper for speech-to-text, and various large language models. We also learned how to design and connect distributed services, handle CORS and API communication issues, and debug complex, multi-service architectures. This experience strengthened our understanding of full-stack integration and exposed us to real-world challenges in building multimodal systems.
What's next for JARVISION
We believe in grand visions, which is why the next evolution of Jarvision is a fully functioning assistant that can sit next to you. Once we iron out the logistics of a physical body, we can bring Jarvision into life with the power of the mind.



Log in or sign up for Devpost to join the conversation.