
Inspiration
We’ve all dreamed of having our own “JARVIS” ever since watching Iron Man. Today, with Whisper’s state-of-the-art speech recognition and Gemini’s powerful reasoning API, that vision is within reach.
What It Does
SONA awakens at the sound of “Hey SONA,” instantly transcribes your voice with Whisper, and routes your query through our MCP framework to a conversational AI (Gemini or Sesame). Replies stream back in real time via a familiar chat-style interface—what you say, think, and do, all in one seamless voice loop.
# SONA in three steps:
# 1) listen ("Hey SONA")
# 2) think (Whisper → Gemini)
# 3) do (respond via chat UI)
How We Built It
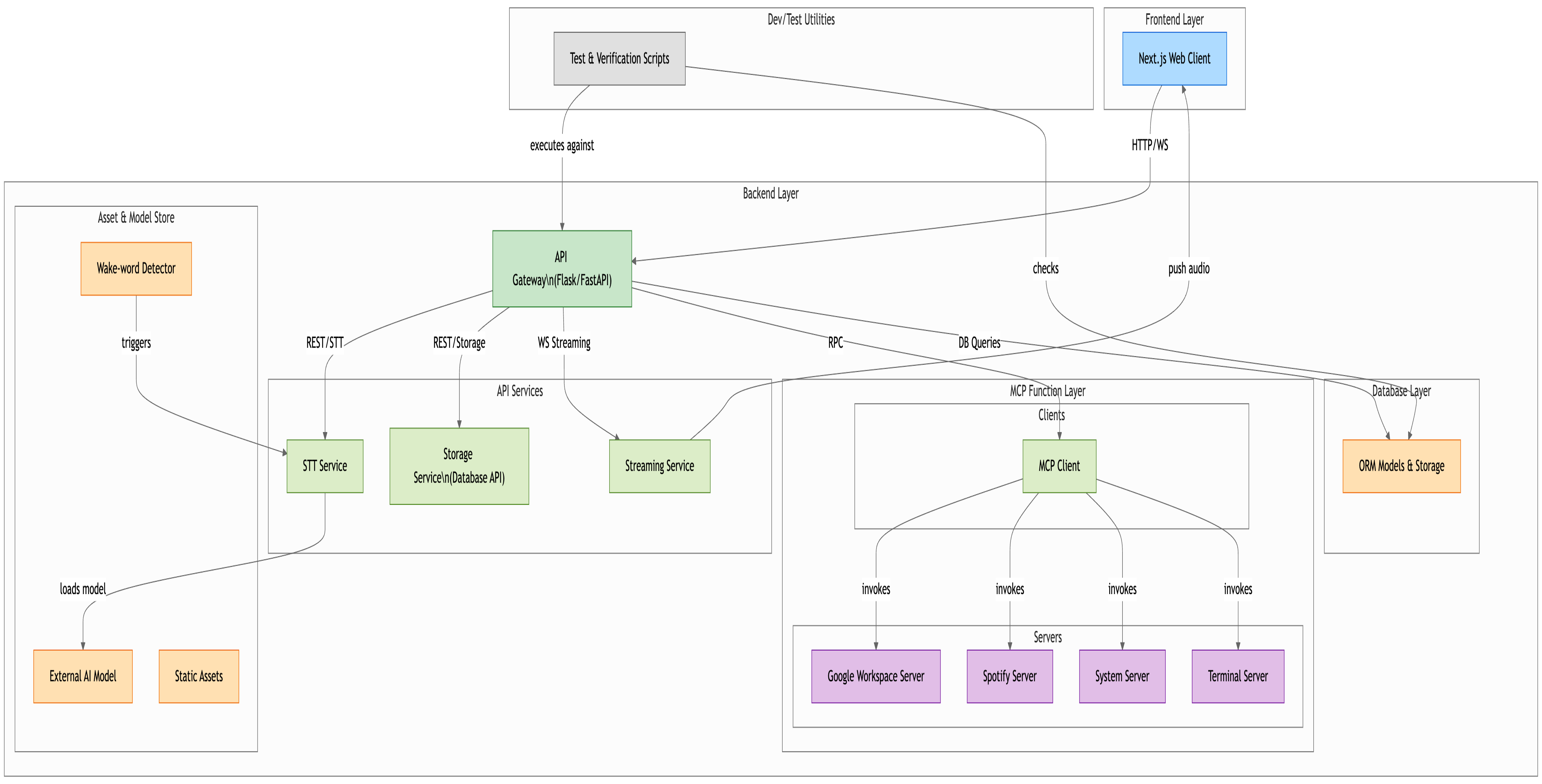
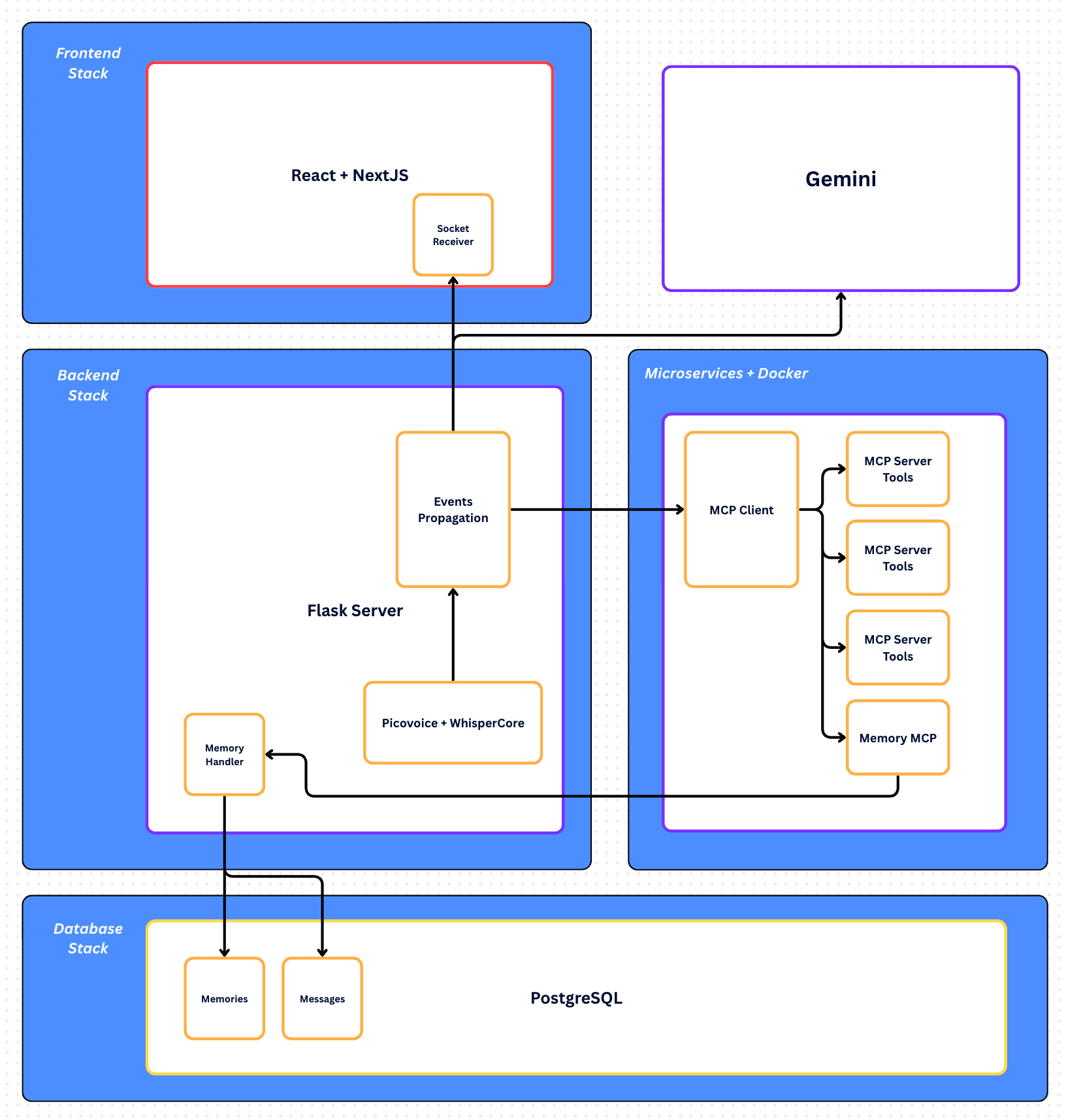
In our React/Next.js frontend, we use an AudioWorklet to capture 16 kHz PCM and run Picovoice Porcupine in-browser for sub-10 ms wake-word detection, then stream raw audio buffers over WebSockets to our Flask-SocketIO service. There, whisper.cpp provides live transcription, our FastMCP JSON-RPC framework orchestrates tool-enabled reasoning with Google Gemini or Sesame, and the AI’s replies are pushed back to the client for display in a chat-style UI—complete with seamless on-the-fly model switching.
Technology Stack
| Layer | Technologies |
|---|---|
| Frontend | React & Next.js (TypeScript), Web Audio API / AudioWorklet (16 kHz PCM capture), Picovoice Porcupine (WASM wake-word), Socket.IO client, Chat UI |
| Backend | Python 3, Flask & Flask-SocketIO (eventlet), whisper.cpp, FFmpeg, FastMCP JSON-RPC framework, Google Gemini & Sesame APIs, Kōkoro text-to-speech |
| Infrastructure & DevOps | Docker & Docker-Compose, PostgreSQL, Nginx (SSL termination & proxy), environment-variable configuration |
Challenges We Faced
Building SONA meant venturing into uncharted full-stack AI territory. Our biggest hurdles were:
Taming Whisper latency
We tuned chunk sizes, FFmpeg flags, and parallel subprocesses to keep transcription under one second without overloading the CPU.Aligning wake-word callbacks
Coordinating Picovoice Porcupine’s WASM callbacks with our AudioWorklet capture pipeline took careful timestamp alignment to ensure “Hey SONA” fired exactly when expected.Rolling out our MCP framework
Designing a Model-Control-Protocol server and its clients was entirely new: we defined JSON-RPC “tools,” managed asynchronous calls, and plugged them into Gemini and Sesame endpoints.Gluing front end and back end
Stitching together AudioWorklet, WebSocket streaming, Flask routing, whisper.cpp, MCP calls, and React state in one cohesive codebase tested every layer of our stack.
Overcoming these challenges gave us deep, end-to-end insight into real-time audio processing, wake-word engineering, and multi-model AI orchestration.
Accomplishments
We built a working prototype of a voice-driven AI assistant that feels fluid and responsive. The real-time transcription, model-switching capability, and chat UI all came together smoothly, giving users a futuristic voice interface powered by state-of-the-art AI.
What We Learned
We gained deep, end-to-end experience building real-time audio pipelines—from fine-tuning wake-word detection and whisper.cpp transcription to orchestrating multiple AI models via our MCP framework. We also learned that streaming raw audio over the network for backend reformatting introduced unnecessary complexity.
What's Next for SONA
Next, we plan to add semantic search over long-term memory in PostgreSQL, integrate audio-based emotion analysis, and build tighter native tooling support on macOS and Windows. Our goal is to evolve SONA into the versatile, JARVIS-style assistant these platforms still lack.

Presentation Link
https://drive.google.com/file/d/16t8T9Q4PXQDQzQVevMKUq1KGUs_X5_By/view?usp=sharing











Log in or sign up for Devpost to join the conversation.