-
-
-
-
Landing Page
-
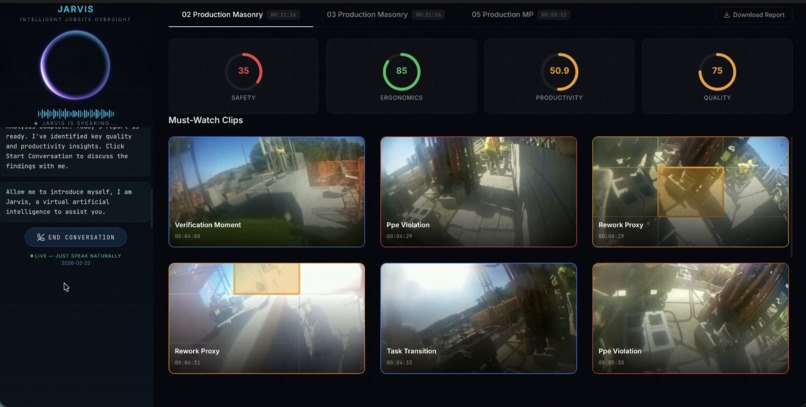
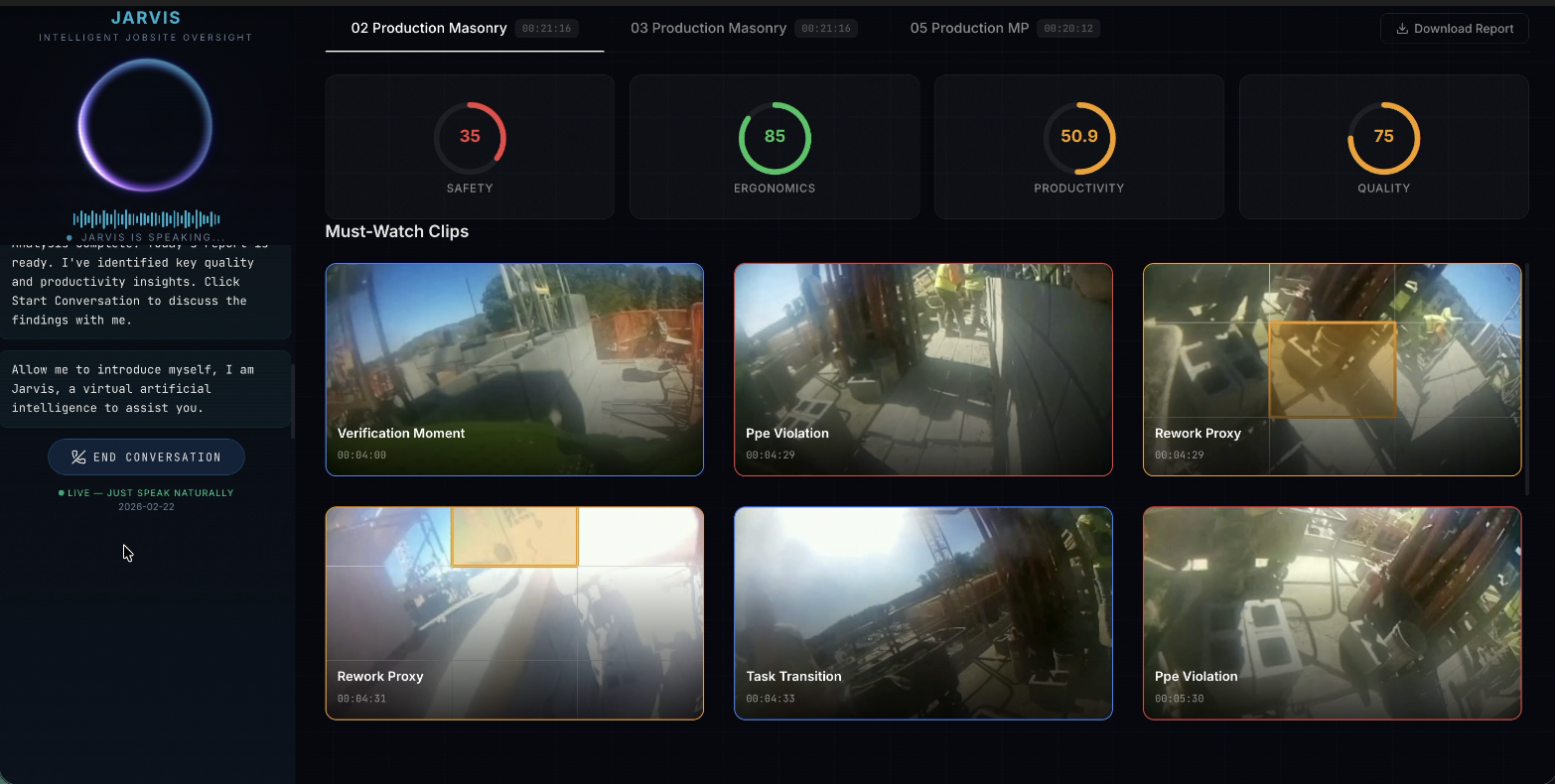
Dashboard
-
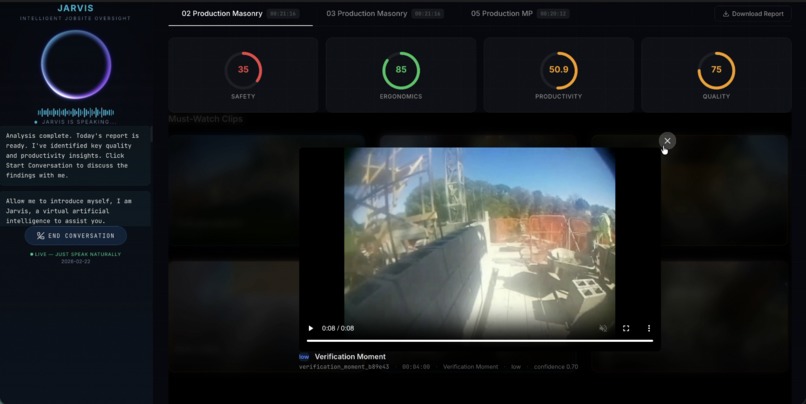
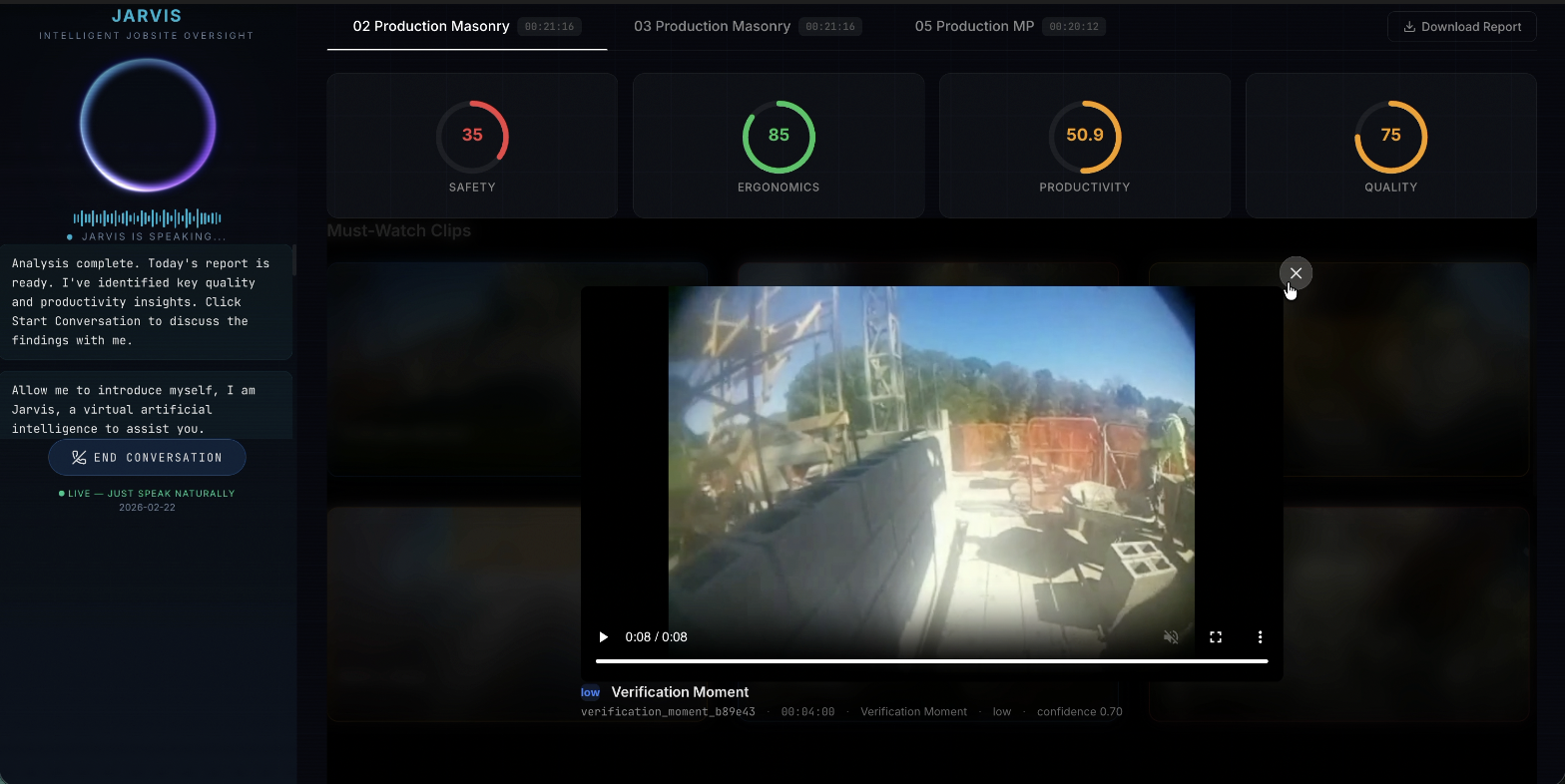
Clip View
Inspiration
Construction sites generate hours of headcam footage every day. We wanted to build something that would actually surface what matters without anyone having to sit through hours of footage.
But when we looked at applying AI to this problem, we found a deeper issue. Current vision-language models can describe footage. They cannot understand it spatially. The research backs this up directly: depth and height perception fails across all state-of-the-art models (GeoMeter Benchmark), attention is routinely misallocated on spatial questions (AdaptVis, ICML 2025), and egocentric video requires evidence-dense moment retrieval, not summarization (EgoConQS, 2025). These are not limitations we could prompt-engineer around. They required a different architecture.
What We Built
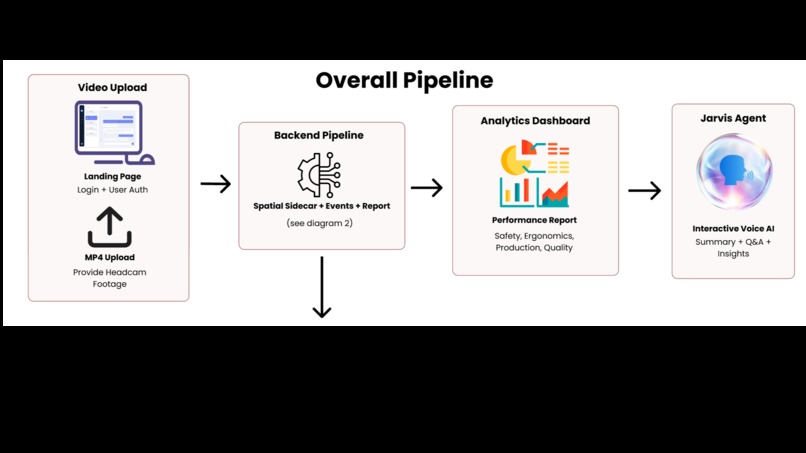
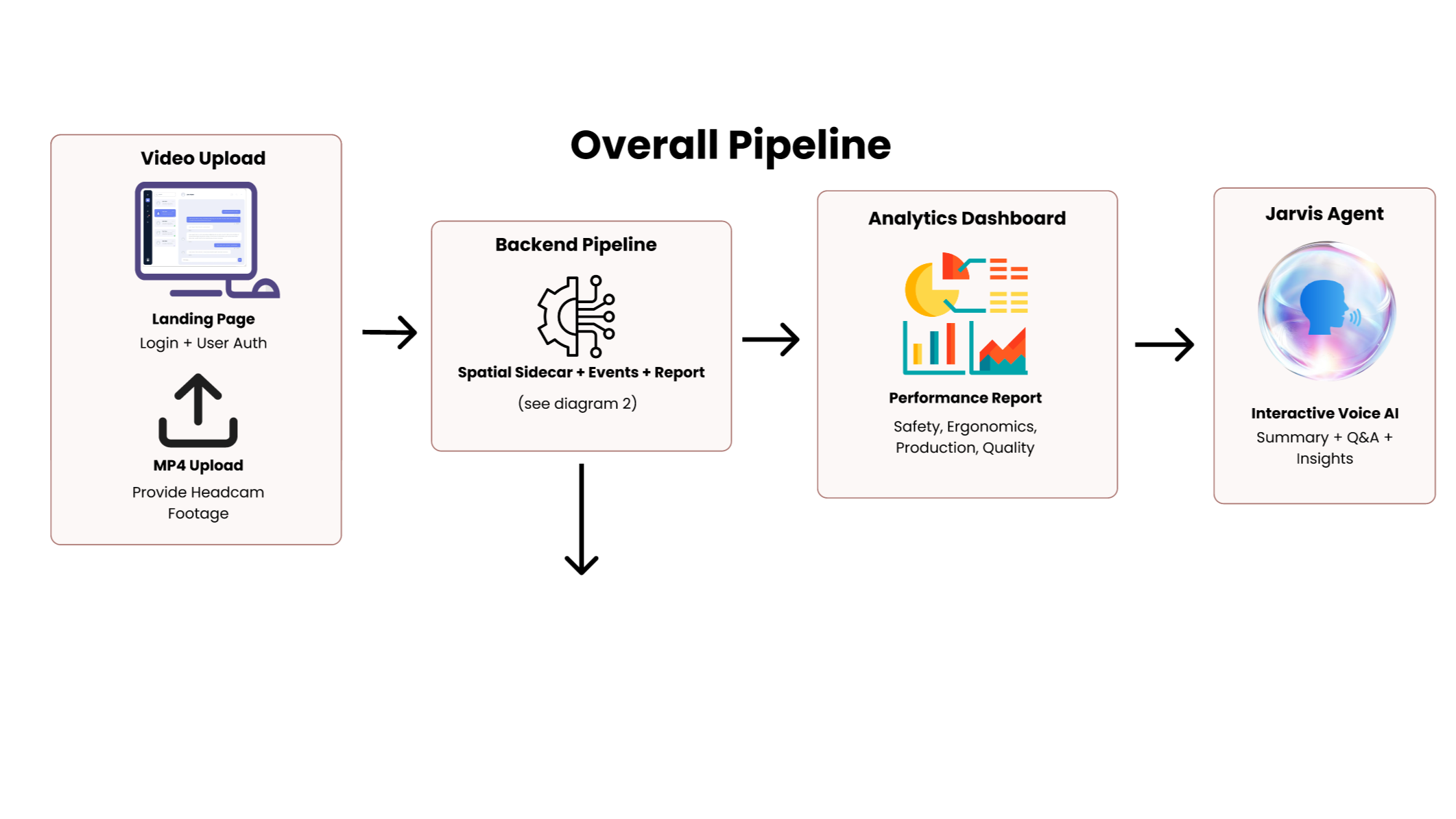
Jarvis is a construction intelligence system that takes raw headcam footage and produces a supervisor-facing daily report scored across 4 metrics: with timestamped clips and a voice AI agent that can answer questions about the workday.
How We Built It
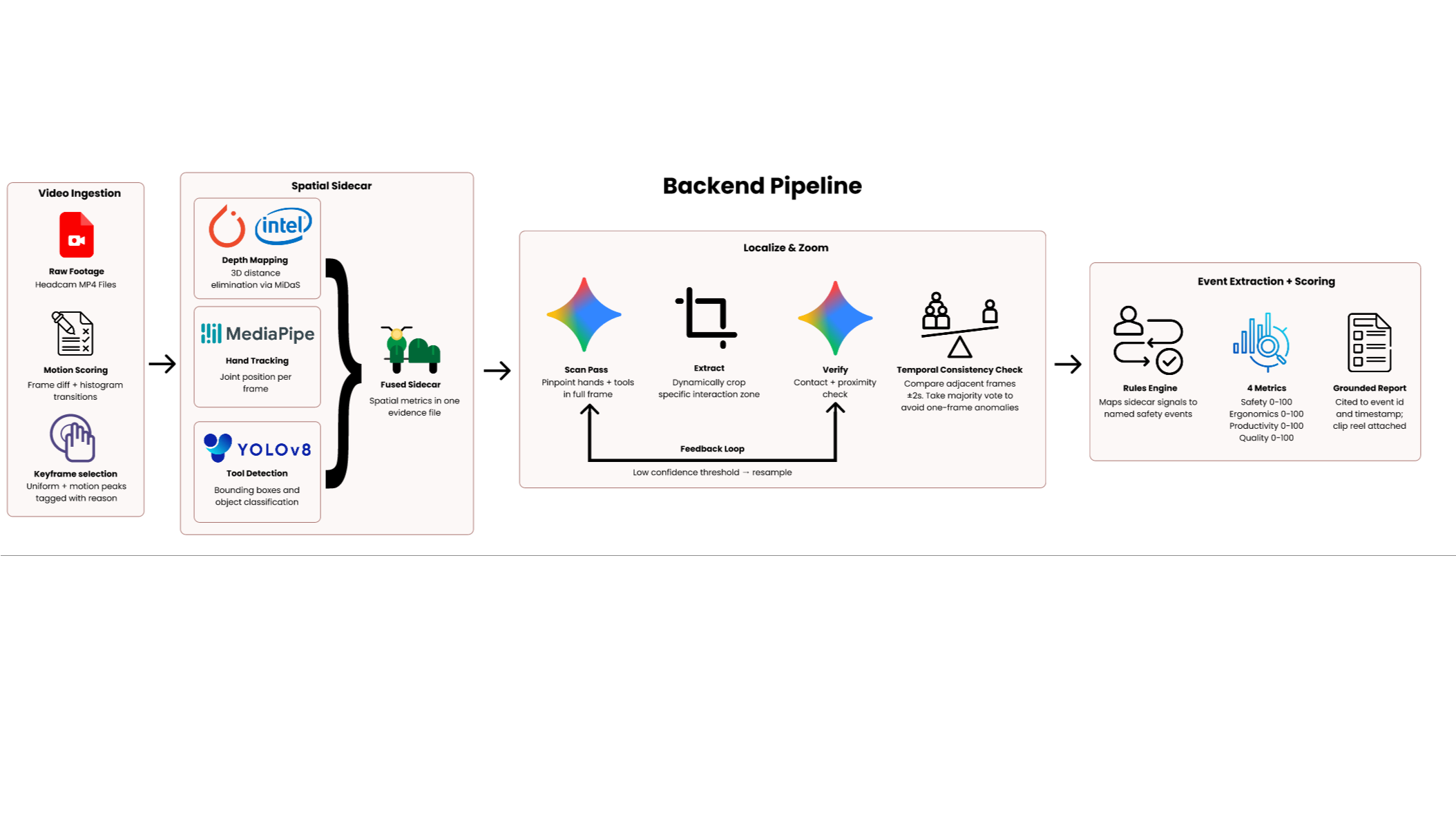
The pipeline runs in four stages.
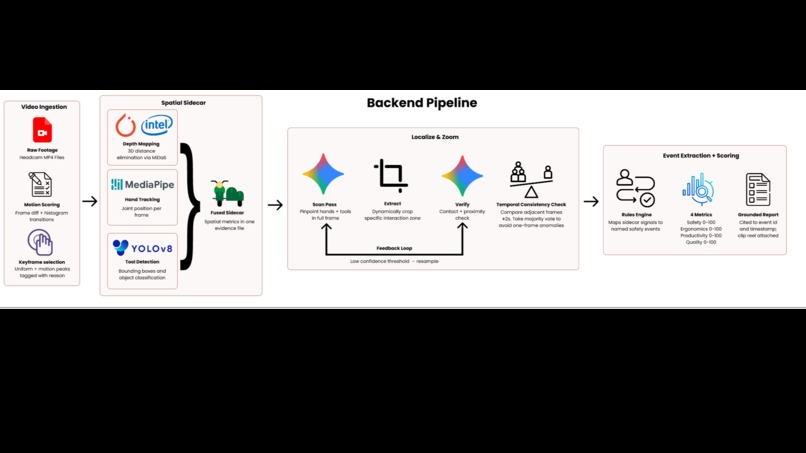
Keyframe selection scores every frame using pixel difference magnitude and histogram transitions, selecting only evidence-dense moments rather than processing footage blindly.
Spatial sidecar construction runs MiDaS depth estimation, MediaPipe hand tracking and YOLOv8 tool detection in parallel on every keyframe. The three streams fuse into a single JSON evidence file capturing interaction density, hand-tool overlap, 3D distance estimates and spatial region per frame.
Localize and Zoom loop handles high-severity events. Gemini scans the full frame and returns bounding box coordinates for hands and tools. The system crops the raw frame at those exact coordinates and re-queries Gemini on the zoomed crop — forcing the model to attend to the exact interaction zone rather than a wide ambiguous shot. A feedback loop resamples on low confidence. A temporal consistency check then votes across adjacent frames within 2 seconds to confirm the event is real.
Event extraction and scoring maps sidecar signals to named events: Near Miss, Idle Streak, Rework Proxy, Approach Hazard, Verification Moment, and scores four indices from 0 to 100. Every claim in the report is cited to a specific event ID and timestamp.
Jarvis, our voice AI agent, ingests the final report and becomes an interactive assistant the supervisor can talk to directly.
Challenges
The core challenge was that standard VLM inference is spatially unreliable on wide-angle construction footage. A worker's hand near a blade is a tiny cluster of pixels in a wide shot: the model cannot tell if contact is happening. The Localize and Zoom loop was the architectural answer to this, but getting the bounding box coordinates, crop extraction and re-query cycle to work reliably under a budget-limited API took significant iteration.
Egocentric headcam footage is also inherently noisy: fast motion, frequent occlusion, variable lighting. Making the sidecar construction stage robust to missing detections and degraded frames without failing the pipeline required careful fallback logic throughout.
What We Learned
Inference-time spatial intelligence is achievable without fine-tuning. The combination of explicit geometric preprocessing, agentic cropping and multi-frame voting produces spatial grounding that single-pass prompting cannot. The research literature on VLM spatial failures was directly actionable: each documented failure mode maps to a specific component in the pipeline.
Built With
- bash
- google-gemini-2.5-flash
- mediapipe
- midas-small
- next.js-16
- opencv
- python
- pytorch
- react-19
- tailwind-merge
- timm
- torchvision
- typescript
- yolov8-nano



Log in or sign up for Devpost to join the conversation.