-
-
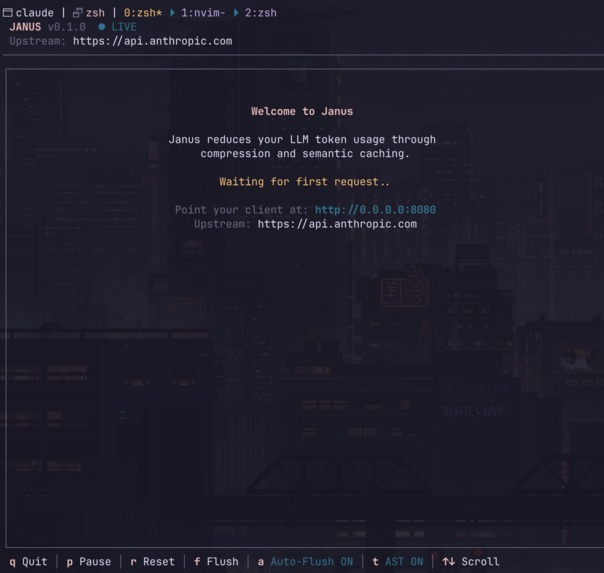
Uncoupled TUI screen
-
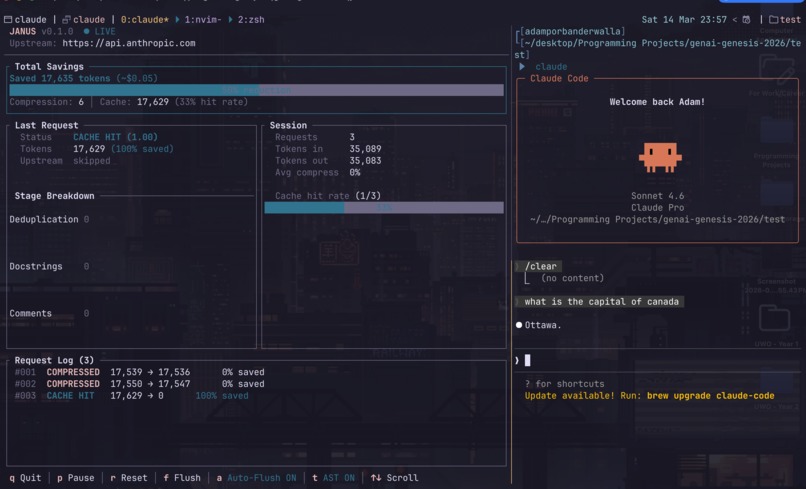
TUI with cache hit
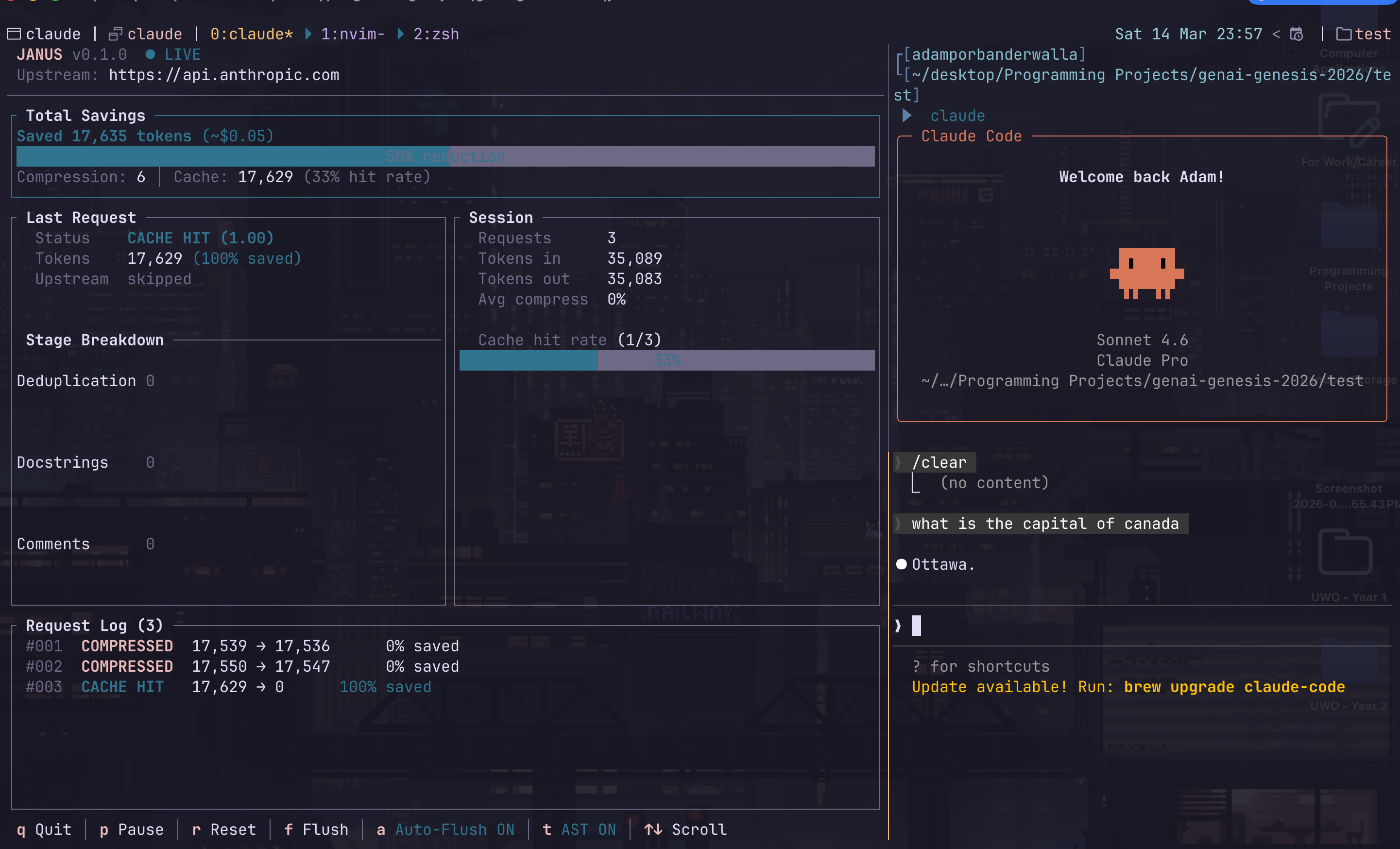
Inspiration
I and a lot of people use either agents or coding agents, but we end up using a lot more of our limited usage or spending more money than necessary by sending bloated requests. I wanted to build something that runs locally, losslessly, and efficiently that could significantly decrease the token usage, so we can get more utility out of these agents.
What it does
Janus sits between you and the LLM's API, it first goes through a compression pipeline.
Stage A - Tool result deduplication: In a conversation with an agent if it calls upon a tool earlier on in the conversation and the file has not changed, instead of returning the same redundant information we send a line that tells the LLM to refer to the information earlier in the prompt. This works because with each request the coding agent sends the entire chat history, effectively reducing your token cost and giving you more "space" in the context window.
Stage B - Regex & Structural Compression: We eliminate Docstrings targeted for langauges like Python, JavaDoc, and Rustdoc. Then we remove all comments in the code, and normalize white spaces. We also condense stack tracebacks for instance if a Python or Node.js stack traceback is more than 10 lines we want to just grab the first 5 and last 5. Then if we see a repeated code block at some point in the code we just replace it with a message saying [Janus: duplicate of code block above -- N tokens omitted]
Stage C -- Sparse Pruning: Use tree-sitter to parse code blocks and remove functions that are unlikely to be relevant. This stage won't be seen much as it only run when files are extra ordinarily large, and it can be toggled from the TUI as it is lossy.
Semantic Cache: On top of the regular compression we use a Semantic Cache with Redis and vector similarity search. Requests that are semantically similar to previously seen requests, returns the cached response directly costing zero tokens and much quicker response time. This works by using a local embedded model that lets us generate a 384 dimension vector for each user request. Then we query the cache trying to find the K'th closest cached embedding. Then we compute the cosine similarity (1 - cosine distance) between query embedding and the closest embedding. If the cosine similarity is greater than or equal to 0.85 we consider it a cache hit and return that response, and skip the LLM call.
How we built it
- Built in completely in Rust
- Async Runtime: Tokio
- HTTP Framework: Axum
- TUI: Ratatui and Crossterm
- AST Parsing: tree-sitter (supports only: Python, JS, TS, Rust, Go)
- Embeddings: fastembed
- Cacheing: Redis with RediSearch
- Token Counting: tiktoken-rs
- Hashing: xxhash (xxh3)
- Containerization: Docker + Docker Compose
Challenges we ran into
Getting the semantic cache to work was one of the initial big struggles. Initially I was trying to figure out how to query redis properly as even on direct hits I wasn't getting the cached response that is when I implemented RediSearch. Also I had the cosine similarity needing to be 0.97 which was just too similar to the original so I was getting misses on things that should have reasonably been getting the cached response.
I also spent a lot of time trying to get session awareness but It wasn't getting any cache hits, because I was using session ID's as part of the key and I haven't found a great way to detect if the instances of claude code are different.
Accomplishments that we're proud of
It's functional with claude code, and can be integrated super simply into your setup. It works well with subagents, and it effectively saves you money over the course of long usage. This is something that I have just integrated into my work flow and am going to actively use it to improve upon itself.
What we learned
- Lots about asynchronous threads in rust.
- How semantic caching works.
- What the multi layered requests look like when an agent is planning and requesting tools.
- Using a local non vanilla redis for caching.
- Too many of different regex expressions.
What's next for Janus
Parallel Session Awareness: When you run claude code in parallel, currently if you have something cached from the other instance that will affect all other instances. Also I would like to add a way that you can see what each individual instance is doing, but I ran into too many errors when deploying sub agents and I need to come up with a good way to know if an instance has ended.
Implementing functionality with all coding agents and other models not just Anthropics: Currently it upstreams only to claudes API and works with only claude code (That I've tested, you could change the base_url for any coding agent and it should work if you provide your api key), so I want it to work with codex, and opencode out the box and as easily as it does with claude.
Working in regular LLM API calls: Currently the project is tailored for agents and more specifically coding agents. The compression methods are the same but currently Janus doesn't support a seamless way to integrate it as a middleware between client and host. The idea would be to deploy janus along side a project using Docker, so you could compress tokens for your agent or chat bot that was hosted on the web.
Open Router compatibility: Open router provides access to tons of free models so you could install claude code change the base_url and through Janus use one of the open router models, for a completely free experience.



Log in or sign up for Devpost to join the conversation.