-
-

LOgo
-
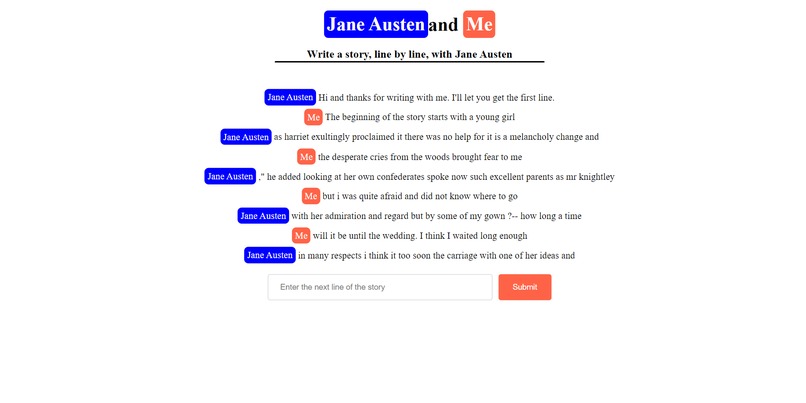
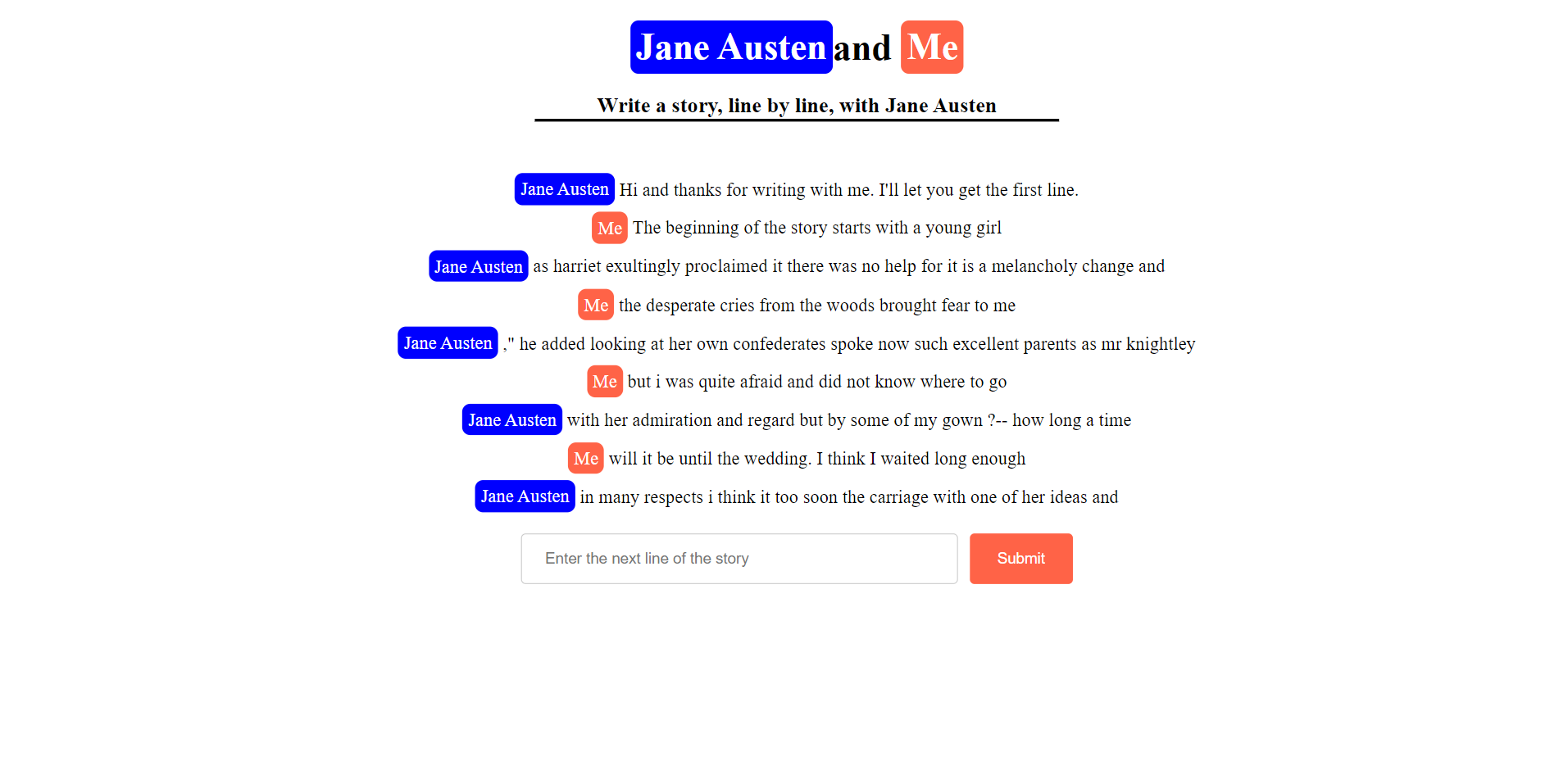
Example Story

Inspiration
Going into queer_hack21 I had natural language processing on my mind. I am still fairly new to NLP (I just added Linguistics as a minor to my CS major maybe a month ago), but I knew that's where I wanted to start. I followed the research wormhole down to natural language generation and decided to learn something new. In addition, I also wanted to incorporate my love for the arts, and so I ended up with the idea for a line-by-line story where one line is written by the user and then the next line is written by a natural language generator. To include the arts, I decided to use a famous author as the foundation for the model and in the end decided on Jane Austen!
What it does
This website is a line-by-line story generator where the user supplies every other line of the story. The other lines are supplied by an AI Jane Austen. This Jane Austen will use the text that you wrote as a basis for her next line!
How we built it
I built an N-gram model which basically uses word pairs next to each other to predict the next word. By applying this prediction model at the very end of a text, I can continuously generate new words and end up with an entire sentence. Specifically, I used a 3-gram (aka trigram) which uses the frequency distribution of 3 adjacent words. My model uses the previous two words to probabilistically generate the next word based on its training on 3 Jane Austen corpora. The 3 Jane Austen texts I analyzed were 'Sense and Sensibility', 'Persuasion', and 'Emma'. In order to use your input to continue the story, the beginning of AI Jane Austen's line is based on the last few words of your input.
Challenges we ran into
Asides from trying to learn a lot of new tools, the biggest challenge was data! I need a lot of data to make a better model and just working with such large amounts of data can be a hassle. I used 3 corpora of Jane Austen books. I was using the Gutenberg corpus supplied with NLTK as the foundation for my data. Initially, I started this whole project based on Shakespeare but after I had built the N-gram model of Shakespeare, the words were too obscure and there was not enough data (only about 80,000 word pairs). I was not pleased with the result and changed gears to look into other corpora which brought me to Jane Austen. The N-gram model for Jane Austen had a lot more data to work with (I got about 350,000 word pairs) and English felt more natural than Shakespeare meaning that a user would have an easier time making lines that looked similar to the n-gram models. Along with lots of data means you probably want to filter out some data which I tried and succeeded mostly. For my model, punctuation was counted as a separate word meaning it would distort the word pairs frequency distribution so I tried to just filter out almost all of the punctuation. In addition to punctuation, uppercase laters were falsely adding new word pairs so I just removed all uppercase letters from the data.
Accomplishments that we're proud of
I'm so proud of how much I learned just from this weekend. I have never done natural language generation, I never worked with JSON files before, I even worked a decent amount in python which is definitely still in the process of learning, and now I have a project!
What we learned
I learned a lot about natural language generation and specifically learned how to build and apply n-gram models which I had never used before! N-gram models use a corpus to build word pairs and use the frequency of word pairs to predict the next word. Here is a resource that carried me this weekend: link This was my Bible for the weekend! NLTK with Python came with corpora of different famous authors and built-in functions that were super helpful to messing with n-gram modeling. Python is not a very strong language for me, but this textbook was so helpful that I decided to try and follow along with its Python. So my Python skills have definitely improved. I also worked with JSON files trying to work with the large amount of data I had and transferring the data from Python into Javascript for my website. But definitely the overall take away form this weekend is the power of N-grams. In my research, I learned just how much use they have in other fields such as being used to predict DNA sequencing which just makes me want to look more into N-grams.
What's next for Jane Austen and Me
I was so excited to use the web speech API that there was a workshop on it, but I was working on other aspects of the project and didn't get to incorporate it in yet. It would be the very next thing I do! The idea behind it would be to allow users to speak lines rather than type them in and the API can read off each line as the story is written. Lindsay was super helpful with demonstrating the web specch API and with one more day I think I can incorporate it in. In addition, there is always room for improvement with the natural language generation model such as possibly using a 4-gram or 5-gram models.



Log in or sign up for Devpost to join the conversation.