
Inspiration
The job market is highly competitive, and a lack of preparation during the recruitment process prevents many candidates from securing employment. Interviews are a crucial stage, yet they present a massive hurdle due to severe performance anxiety.
Research by JDP shows that 93 percent of individuals experience interview anxiety. Generation Z is especially affected. A Databoks survey reports 68.3 percent of them experience moderate to high anxiety, while Psychiatrist.com found 42 percent have a mental health diagnosis, with 35 percent naming job related concerns as a major stressor. Boterview even notes a rising trend of candidates avoiding video interviews entirely due to a lack of confidence.
This anxiety severely impacts the substantive quality of candidate answers, their vocal delivery, and their nonverbal communication. Traditional preparation methods like practicing with friends or just watching video tutorials are unstructured and unrealistic. Furthermore, existing digital platforms fail to provide realistic and personalized interview simulations. They offer a rigid turn based experience where the AI generates a question, the user records a response, and the AI scores it. It feels like filling out a form not like sitting across from a real interviewer. These platforms completely lack a comprehensive evaluation system that covers the substantive quality of answers, vocal delivery, and crucial nonverbal aspects like gesture and facial expression analysis.
Real interviews are messy. Interviewers interrupt. They react to your tone. They notice when you fidget. They have personalities some are warm and encouraging, others are blunt and demanding. We wanted to build something that captures all of that. When the Gemini Live API launched with native audio support, bidirectional streaming, and built in vision capabilities, we saw the opportunity to rebuild our interview experience from scratch not as a chatbot with voice, but as a genuine real time conversation with an AI that has a face, a voice, and a personality. Thus, Intervyou Live was born.
What It Does
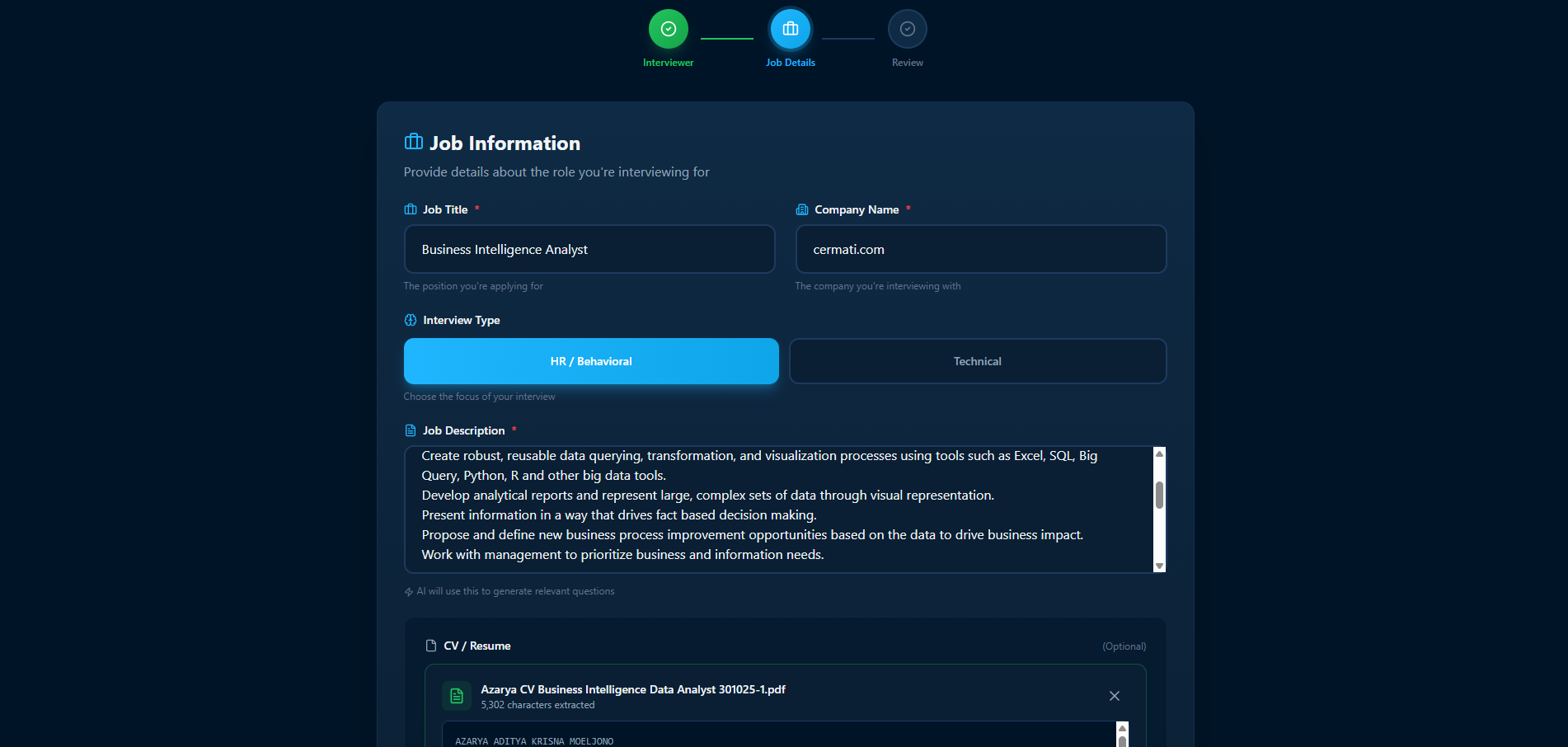
Intervyou Live conducts real time voice interviews with AI interviewers powered by the native audio model of Gemini. To ensure a highly personalized experience, the process begins with detailed user inputs. Users enter their specific Job Title and Company Name, paste the full Job Description, and upload their personal CV document in PDF format.
A lightweight AI model extracts the CV text, allowing the main system to understand the exact background and experience of the candidate. Simultaneously, the Job Description equips the AI with the complete context of the targeted role, including the required skills, domain knowledge, and daily responsibilities. By combining these inputs, the AI interviewer can dynamically generate highly relevant questions, probe specific technical requirements from the job description, and ask targeted follow up questions based on the past experiences listed in the CV.
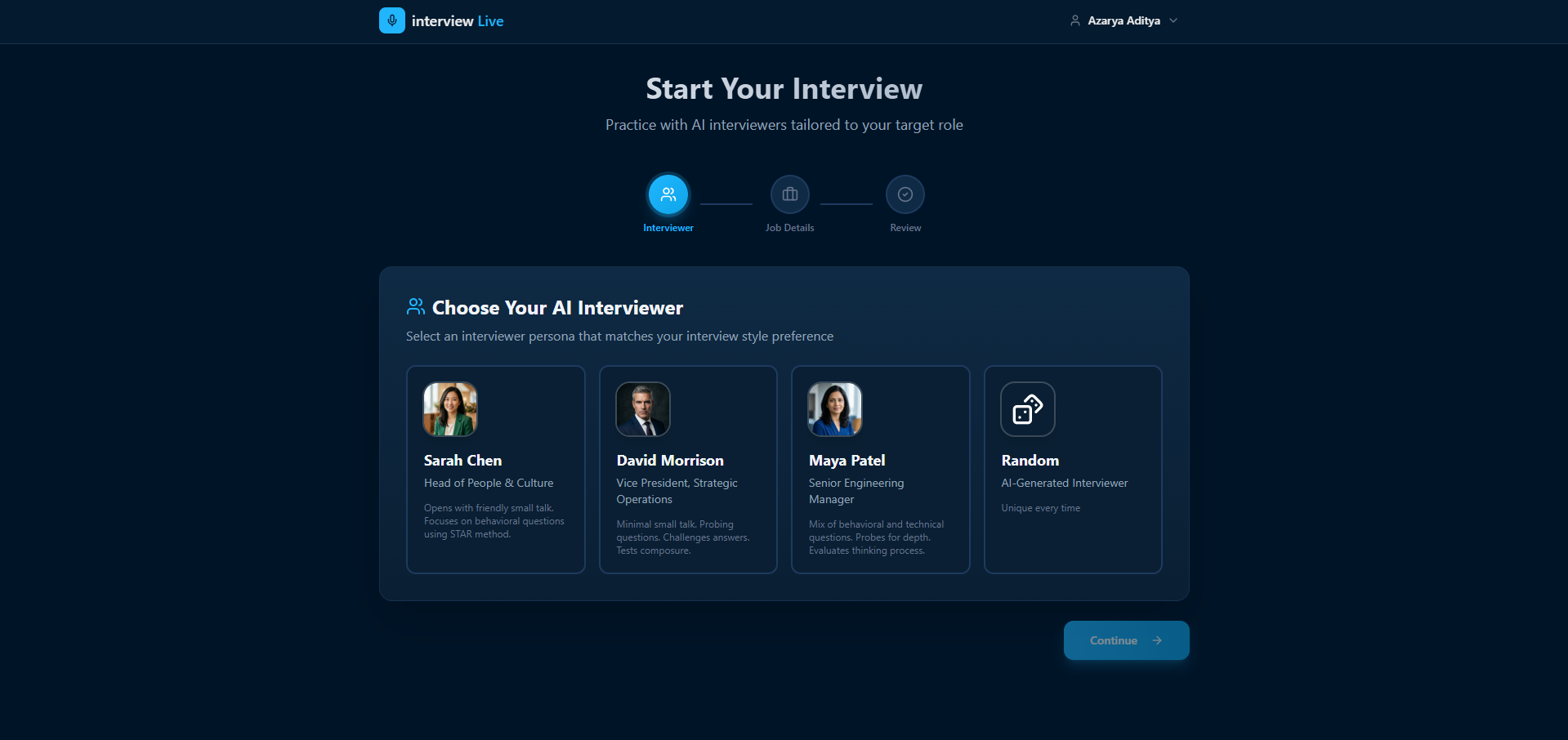
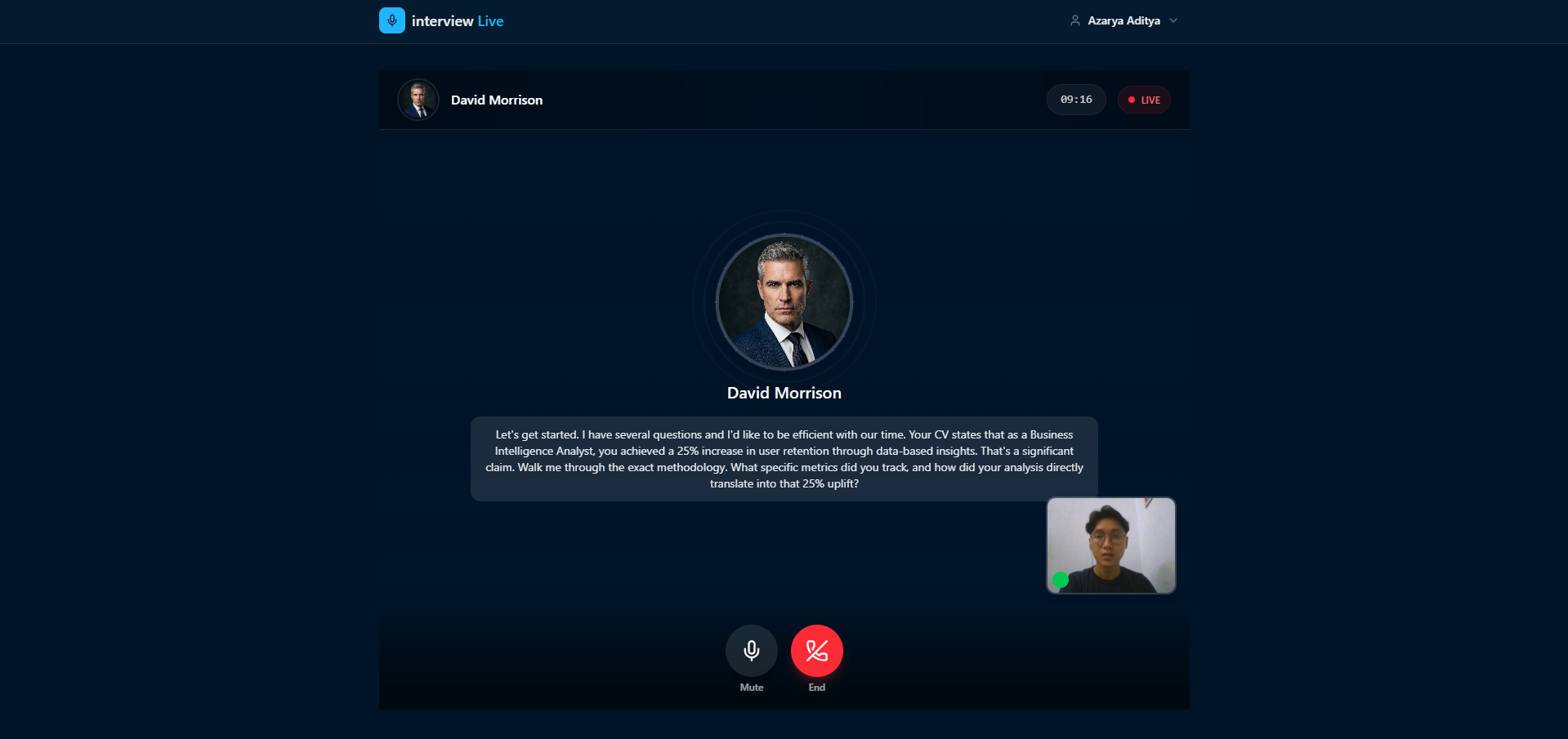
Users then choose an interviewer persona and jump into an actual conversation with no record buttons and no waiting for responses. To support realistic and long form interviews, the system features transparent session reconnection, seamlessly handling WebSocket expirations so candidates can converse naturally for ten minutes or more without interruption. We created four distinct interviewer personas, each equipped with their own Gemini HD voice, personality, and interview style:
- Sarah Chen: a warm startup HR lead who puts candidates at ease.
- Maya Patel: an analytical engineering manager who probes for depth.
- David Morrison: a demanding corporate VP who challenges every answer.
- Random: an AI generated persona dynamically built on the fly using Gemini structured output.
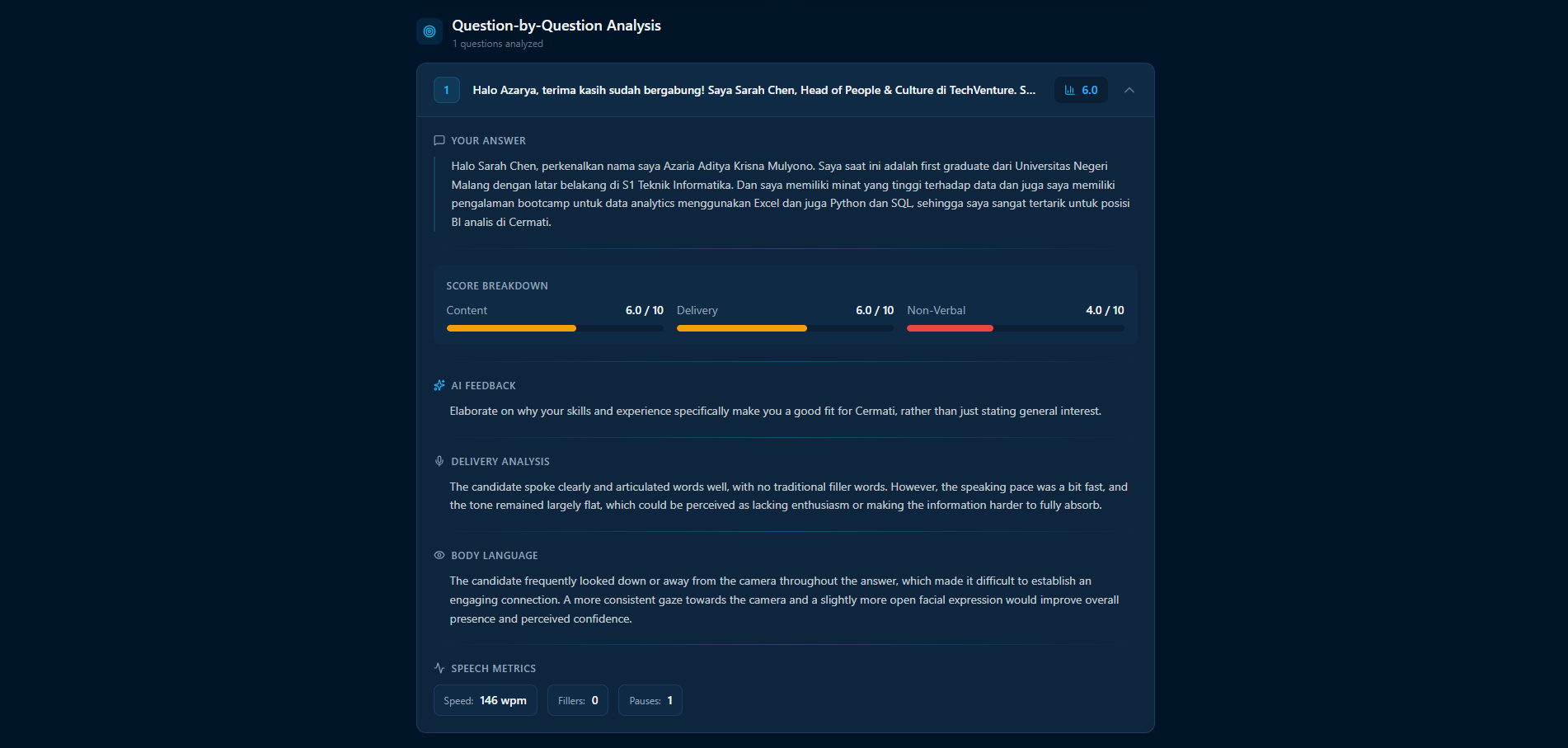
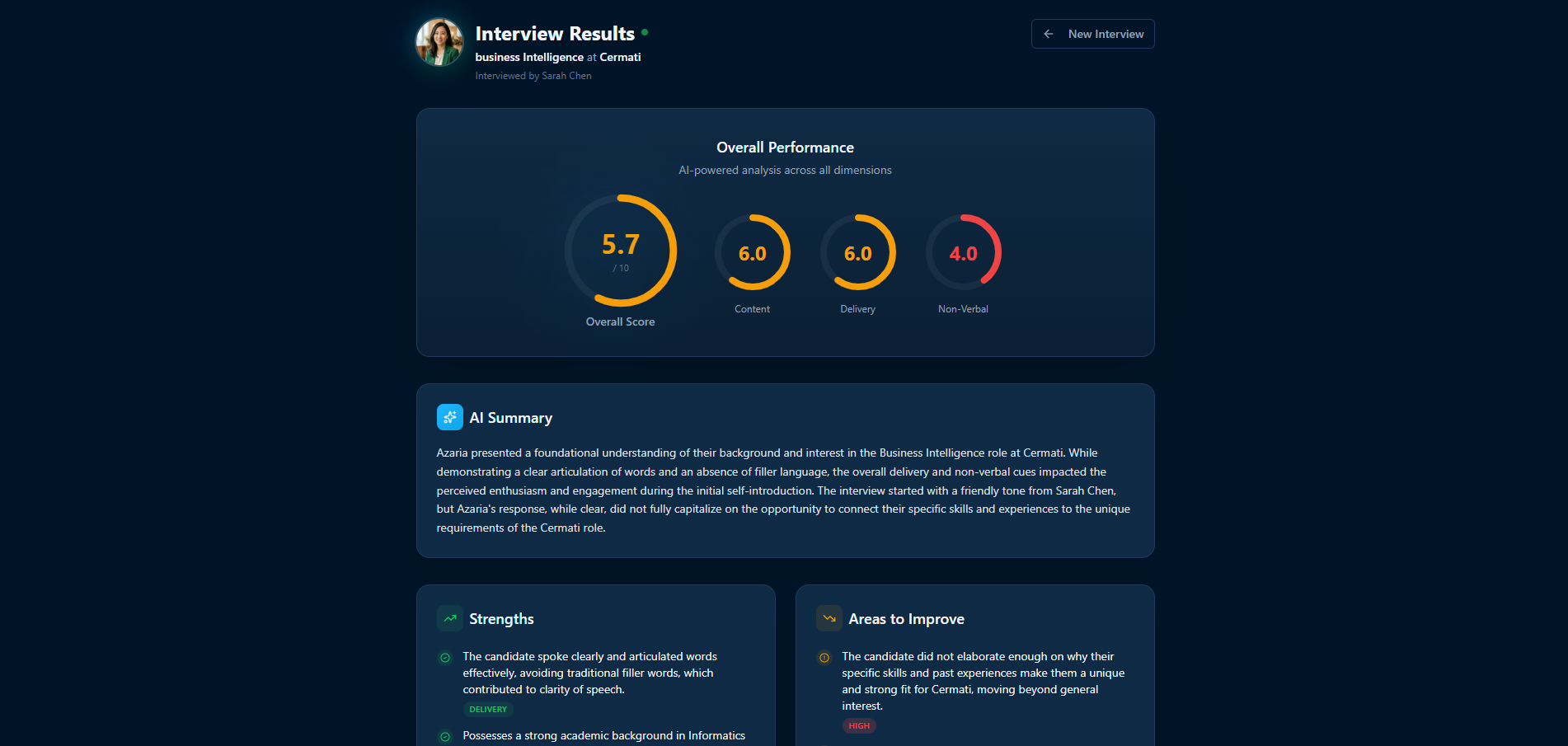
During the interview, each question and answer pair is scored in real time by a separate Gemini instance. Crucially, this evaluation utilizes the actual raw audio of the candidate to accurately assess speech delivery, rather than just relying on text transcripts. It also evaluates content quality and non verbal communication from camera snapshots. After the session concludes, these real time scores are aggregated into a comprehensive dashboard featuring per question feedback, strengths, weaknesses, and a narrative performance summary.
How We Built It
The architecture is a WebSocket proxy. The React client connects to our Express server, which maintains a persistent WebSocket connection to the Gemini Live API. Audio flows bidirectionally as raw PCM 16kHz mono from the user microphone and 24kHz mono from the Gemini voice. This is relayed through AudioWorklet processors for low latency capture and playback. Video snapshots at one frame per second from the user camera are forwarded to Gemini for visual context during the conversation.
The scoring pipeline runs a multi model architecture. The live interview uses gemini-2.5-flash-native-audio-preview for real time conversation, while a separate gemini-2.5-flash instance handles per question evaluation with structured JSON output. This model isolation prevents rate limit conflicts and allows scoring to run securely in the background during the interview itself. The results are completely ready by the time the user reaches the results page.
We built a prompt architecture to work around a known Gemini Live API limitation where long system instructions cause the model to silently hang. The persona identity and interview rules go into the system instruction, while the full job description and CV are injected via client content commands after setup completes. This lets us support detailed job contexts without hitting the hang bug.
Challenges We Faced
Multimodal Duration Limits. The Gemini Live API restricts continuous high frame rate video sessions to a strict token budget limit, often capping around two minutes. Since realistic interviews require at least ten minutes, we altered our video pipeline. Instead of continuous video, we run a base audio session and send one canvas snapshot every second as base64 JPEG images over WebSockets. This bypasses the heavy token budget constraint, easily extending the session to our ten minute target while still providing the AI with periodic visual context to evaluate posture and facial expressions.
Echo feedback loops. When the AI interviewer speaks through the user speakers, the microphone picks it up, and the Voice Activity Detection interprets it as the user talking thus creating an infinite loop. Browser echo cancellation alone is not enough. We built a three layer defense: mandatory browser AEC, tuned VAD sensitivity settings, and server side audio gating that discards microphone audio while the model is speaking. Although this prevents candidates from interrupting the AI mid sentence, it perfectly aligns with professional interview etiquette where candidates naturally wait for the interviewer to finish their question before responding.
Session reconnection. Gemini Live API WebSocket connections expire after around 10 minutes with a GoAway signal. We implemented transparent session resumption using resumption handles but discovered that both the GoAway event and the subsequent connection close event trigger reconnection logic, creating two parallel Gemini sessions with garbled overlapping audio. We fixed this with a state machine guard that prevents double reconnects.
Transcription accuracy. The streaming ASR transcriptions from Gemini are often inaccurate, truncated, or even in the wrong language yet the model hears the raw audio perfectly. Rather than relying on these fragments for scoring, we have the scoring model produce an accurate transcription as part of its evaluation since it already receives the user audio. This replaces the streaming ASR text in the database at zero extra API cost.
Audio forwarding timing. After the Gemini setup completes, ambient microphone noise would immediately trigger the VAD, making Gemini think the user was speaking and preventing the AI interviewer from starting its greeting. We added a three second grace period that blocks audio forwarding until the model begins speaking.
What We Learned
Working with real time audio streaming at the intersection of browser APIs and cloud AI services taught us that the hardest problems are not the ones you plan for they are the edge cases that emerge from the interaction between systems. Echo cancellation, VAD sensitivity, reconnection races, and transcription accuracy were all problems we discovered only through testing with real audio in real environments.
We also learned that the Gemini Live API, while powerful, has several undocumented behaviors like system prompt length limits, unsupported fields that cause silent failures, and string versus number type sensitivity that require careful experimentation. We have documented all of these in our codebase for future developers.
Built With
- express.js
- gemini
- node.js
- prisma
- react
- shadcn
- sqlite
- tailwind
- typescript
- websockets


Log in or sign up for Devpost to join the conversation.