-
-
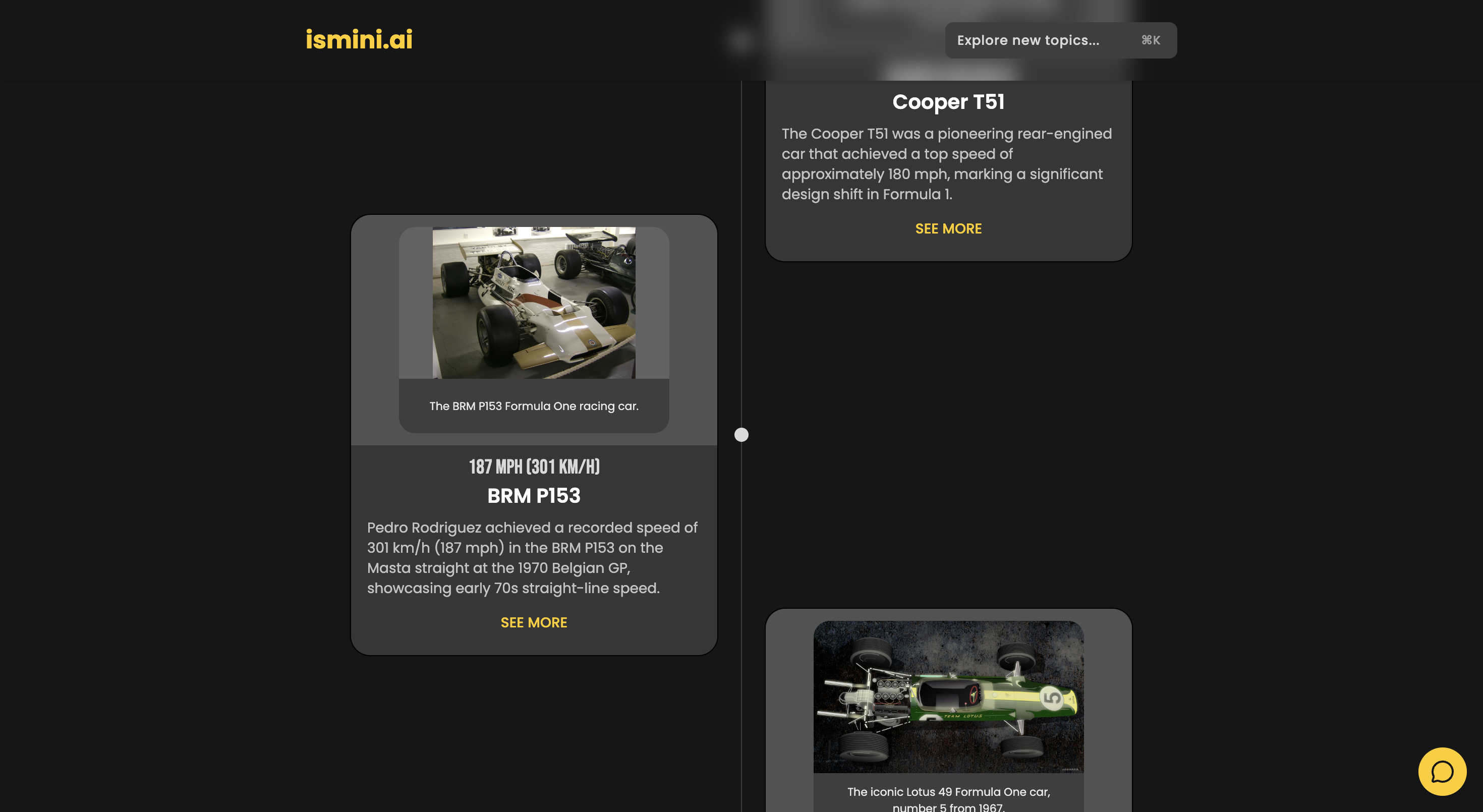
main page
-
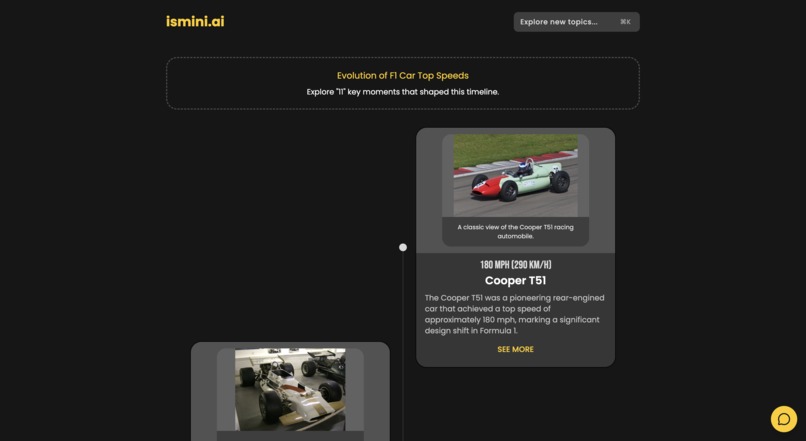
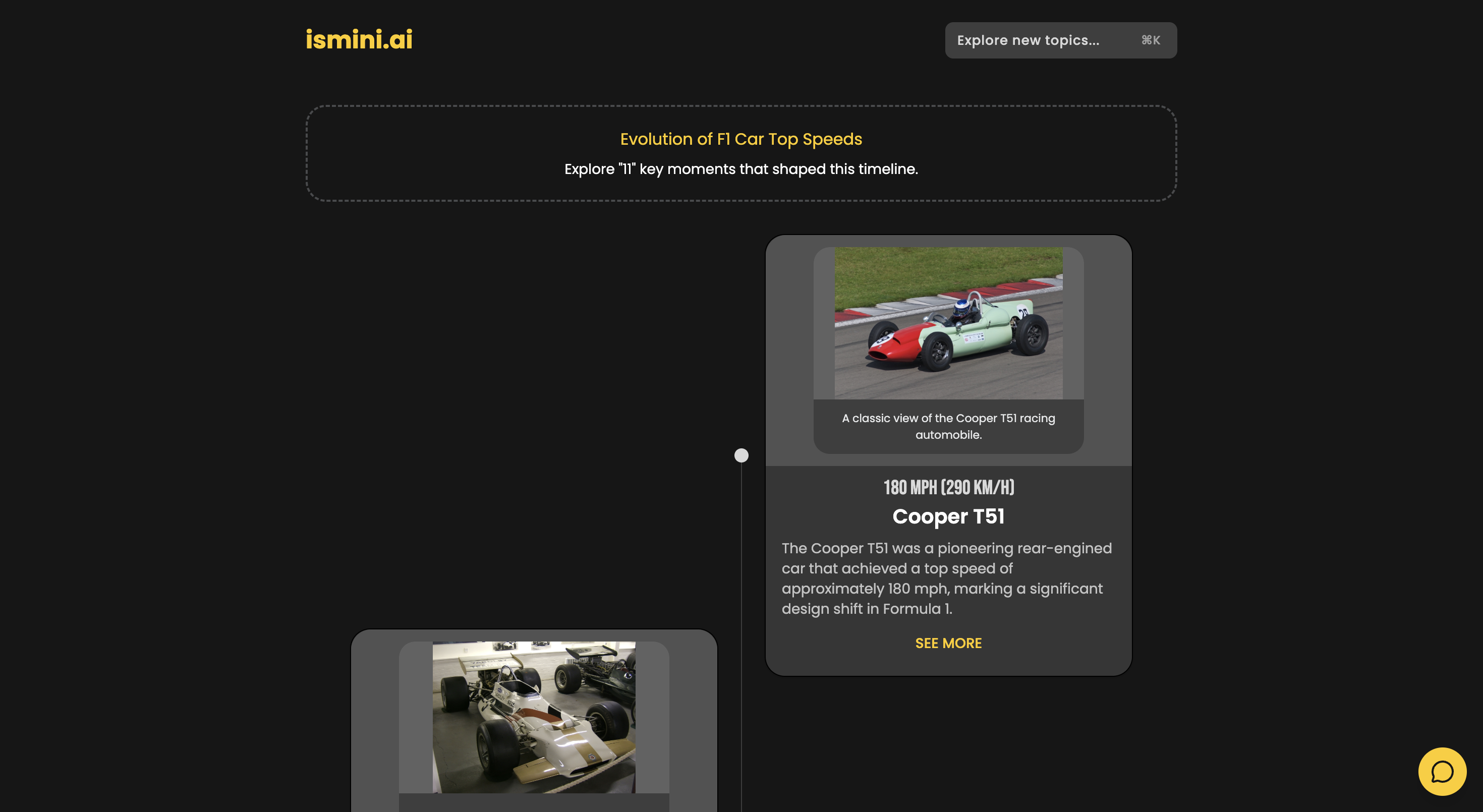
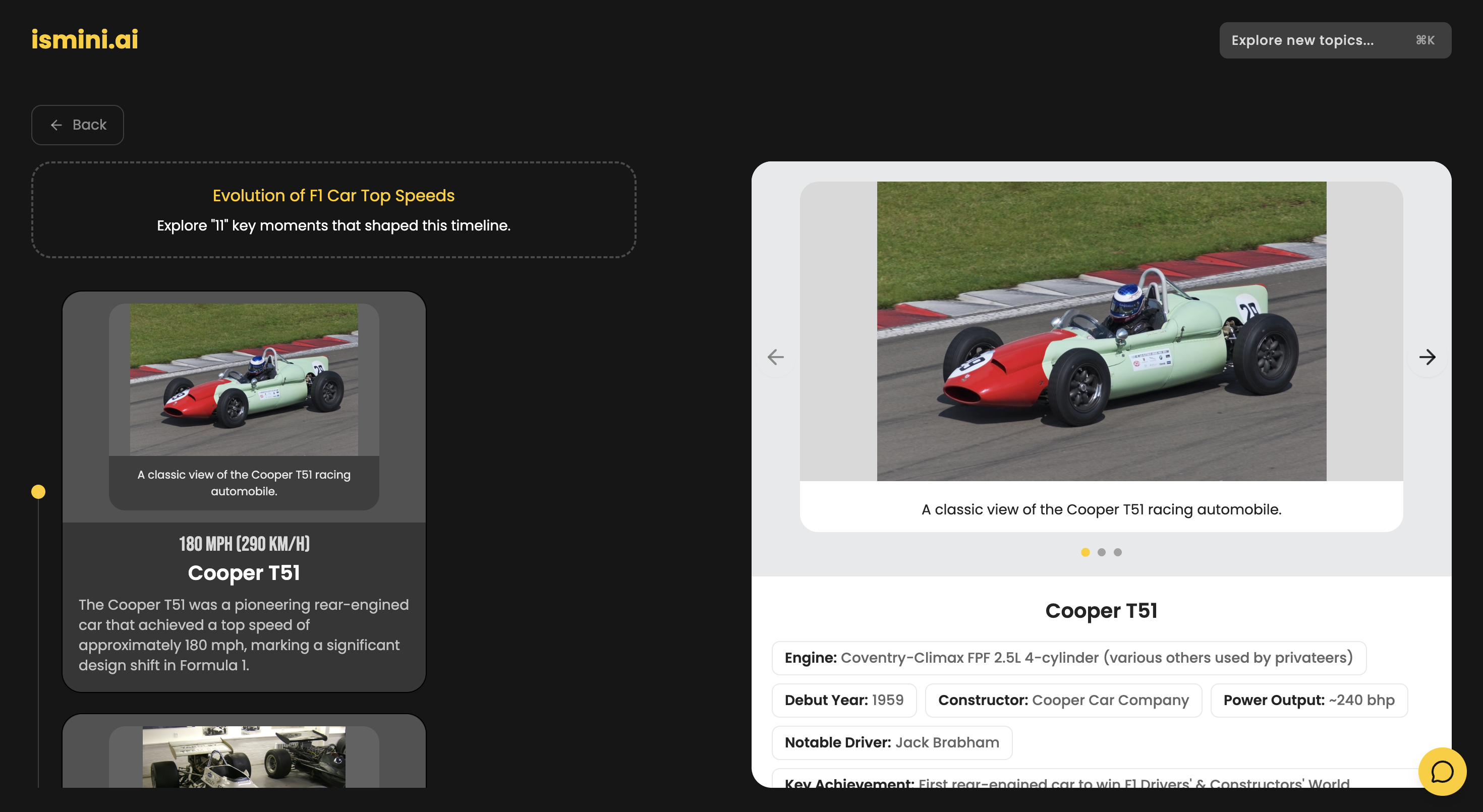
timeline view
-
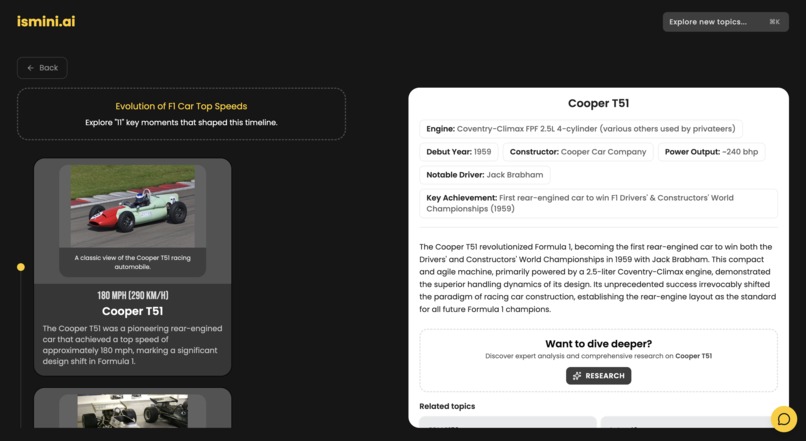
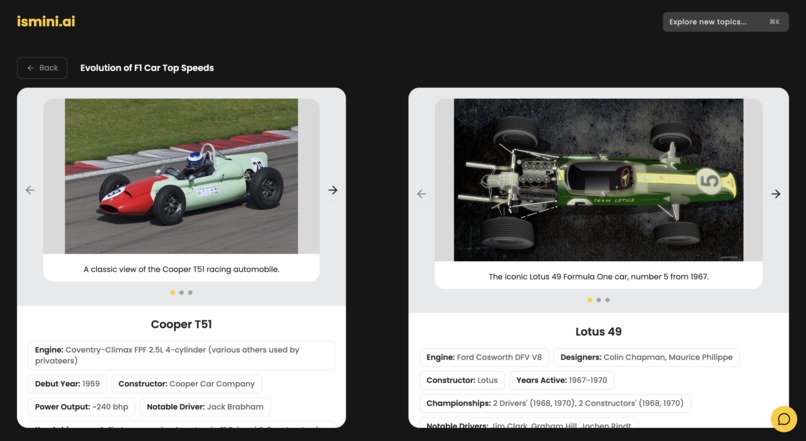
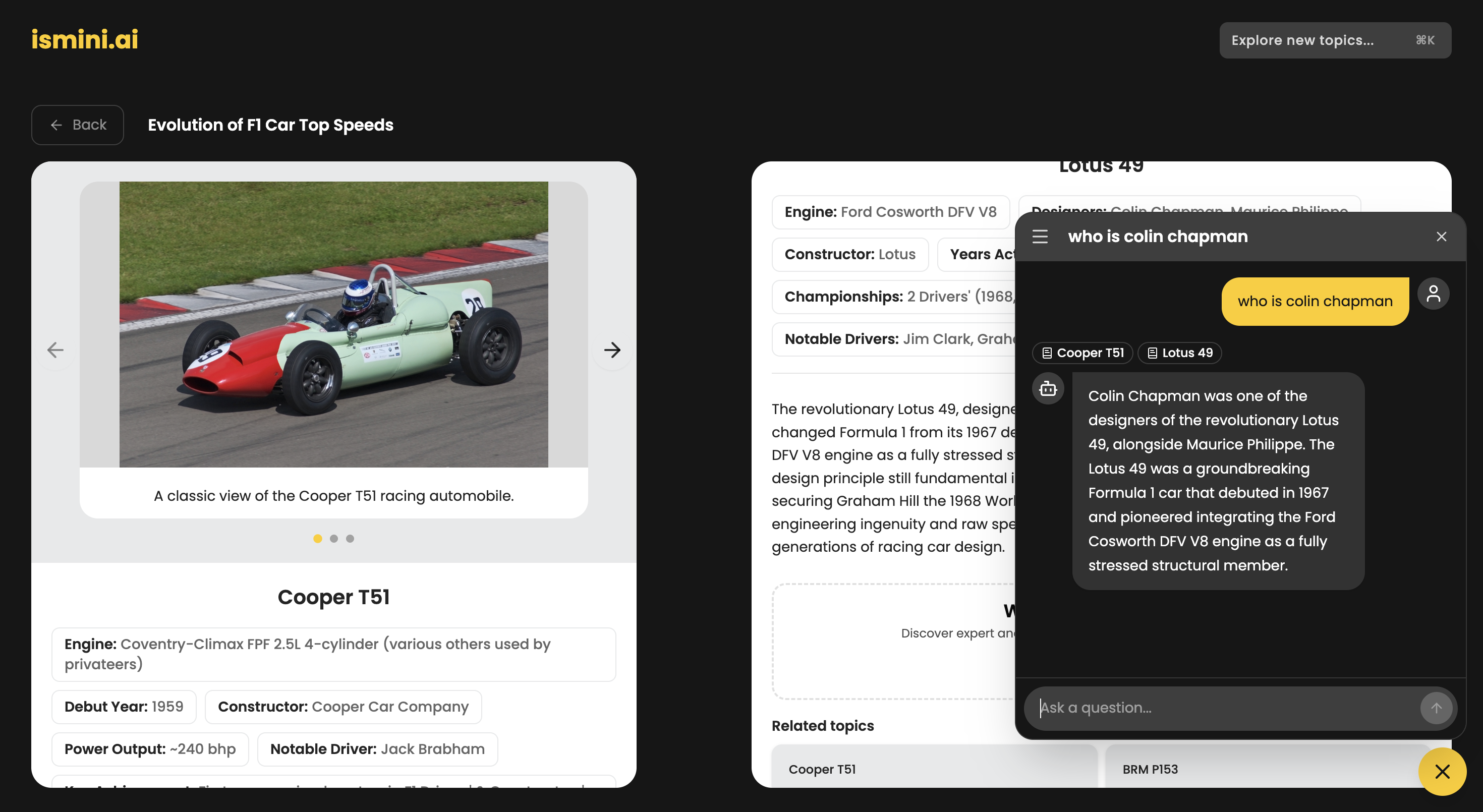
topic view
-
timeline view
-
chat
-
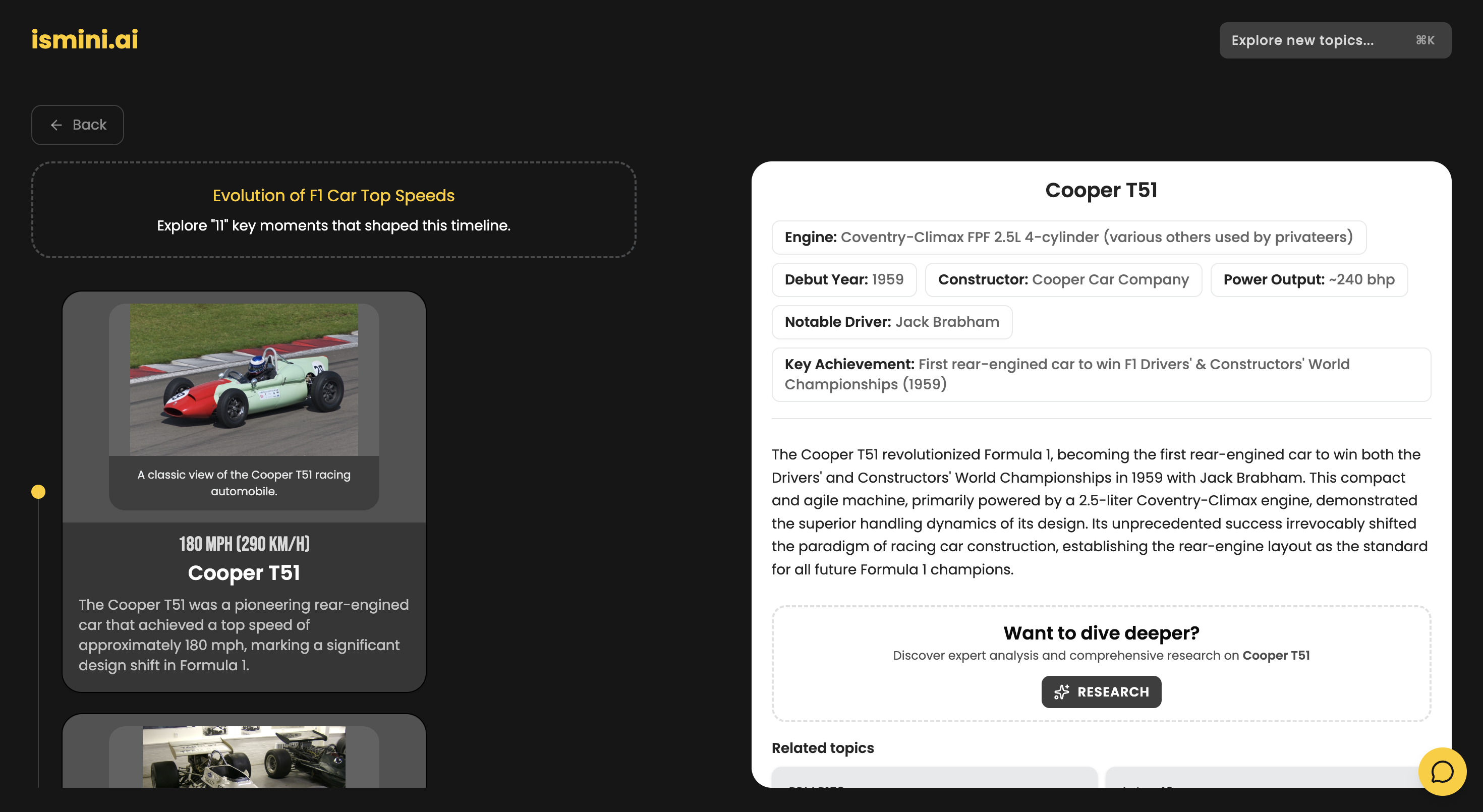
topic view
-
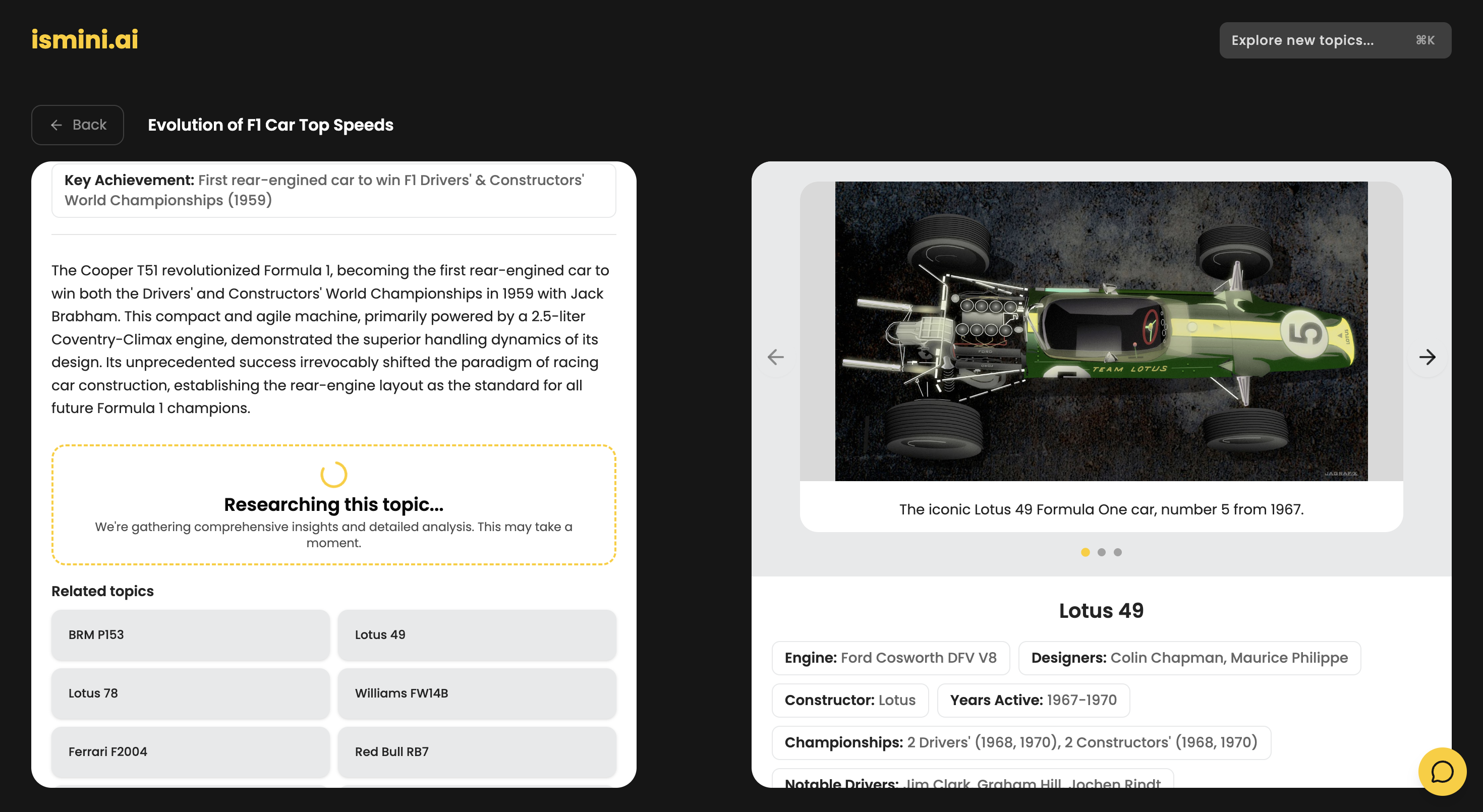
research view
-
research view
-
topic view
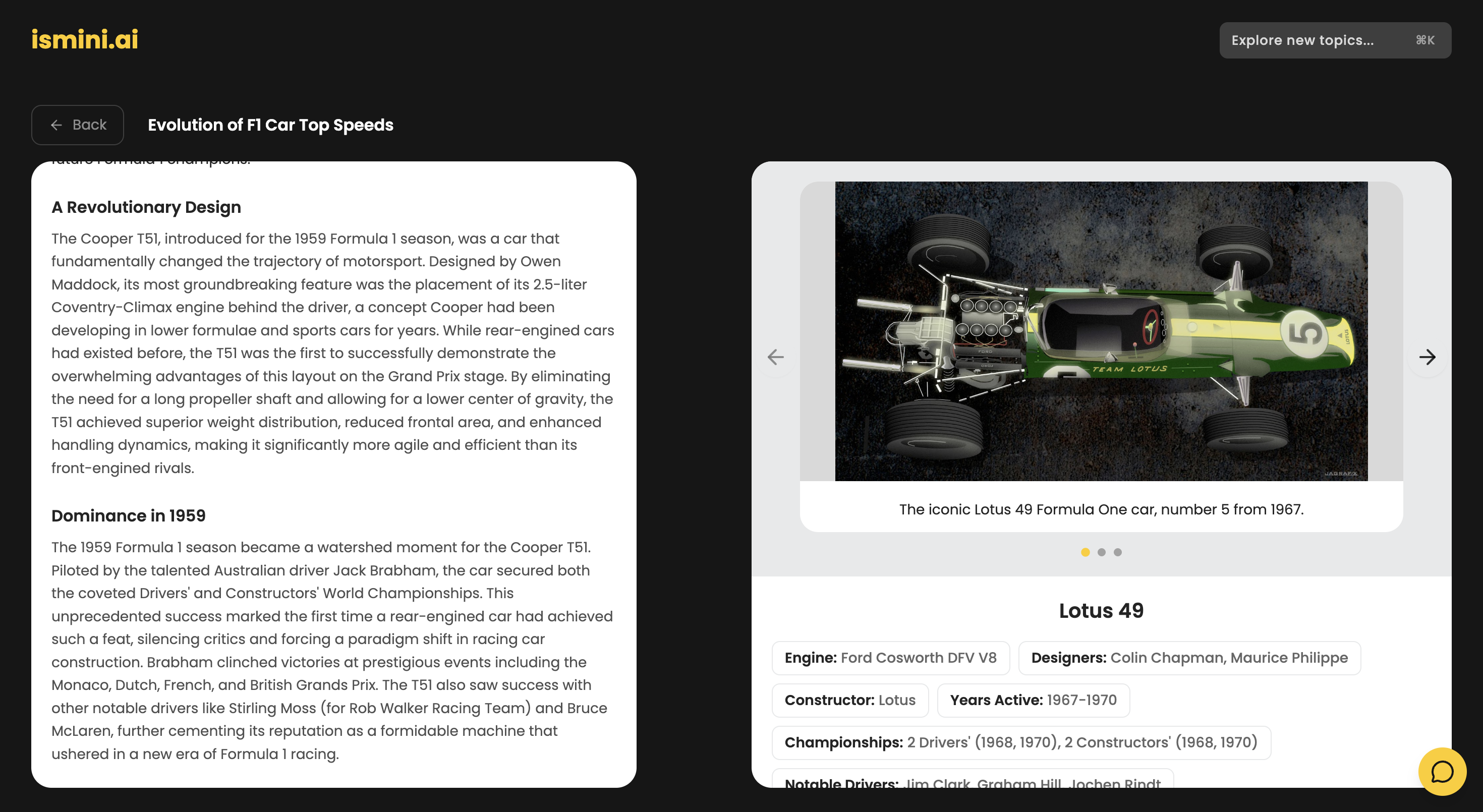
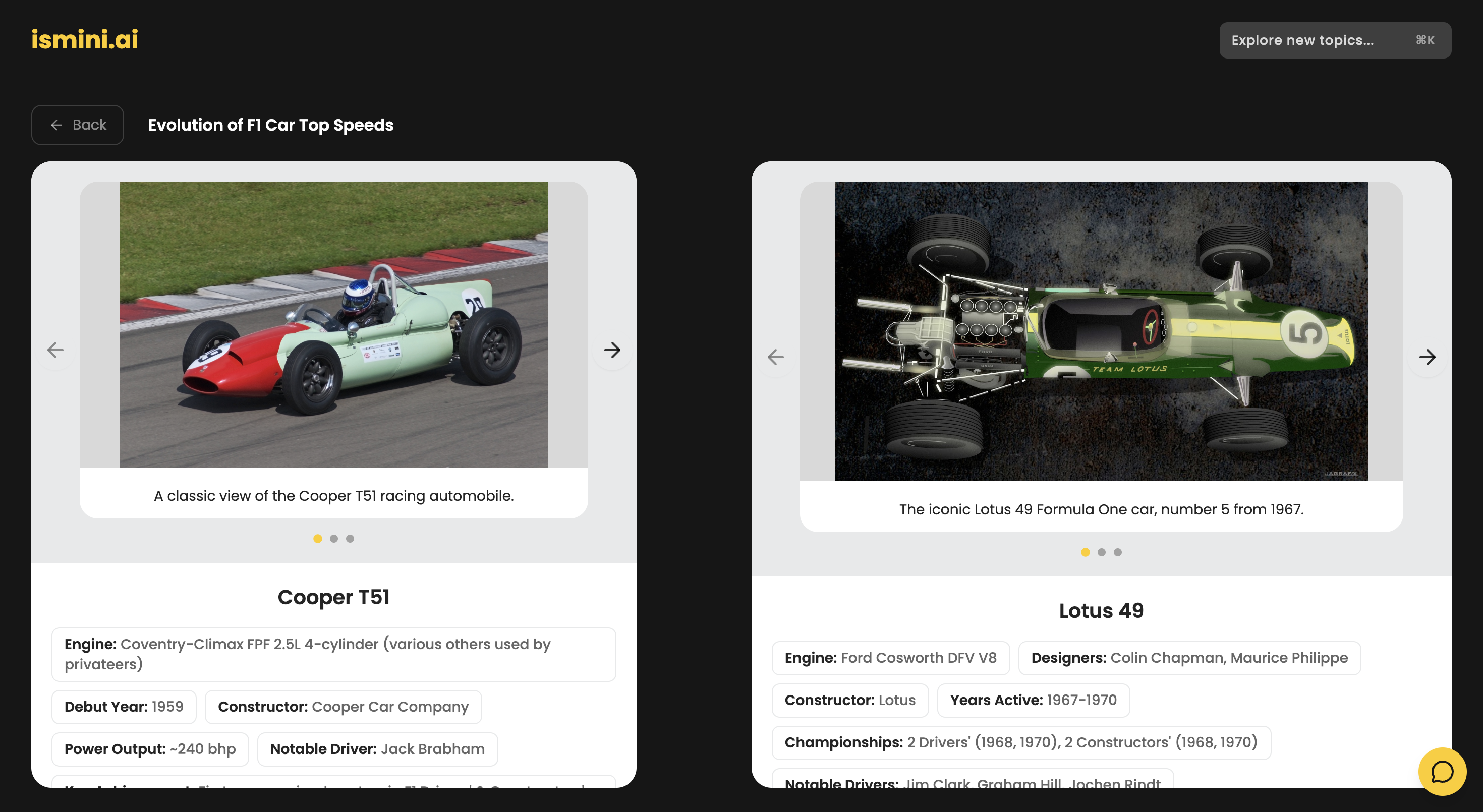
Inspiration
When you search for a complex topic, whether it's the history of the Silk Road or the evolution of Generative AI, you’re met with either dry, encyclopedic entries or fragmented blog posts optimized for SEO rather than education. We wanted to build something that didn't just give you links, but gave you a narrative. We were inspired by the idea of a "Narrative Discovery Engine", an AI that acts like a documentary filmmaker, researching, curating, and visualizing information into a cohesive, interactive experience that feels alive.
What it does
ismini.ai transforms a single natural language query into a rich, immersive narrative.
- AI Curation: It doesn't just list facts, it deploys a "Curator Agent" to design a structured skeleton of the story.
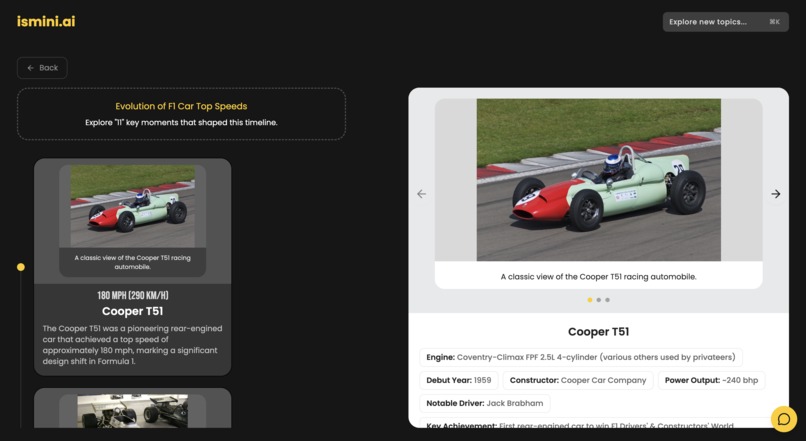
- Interactive Timelines: Users can explore topics through high-fidelity, chronological timelines.
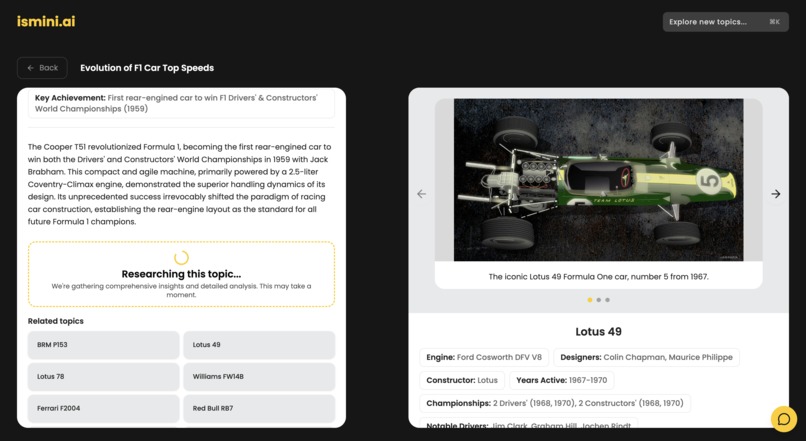
- Deep Research: On-demand agents scour the web and Wikipedia to write detailed deep-dives for every topic on the timeline.
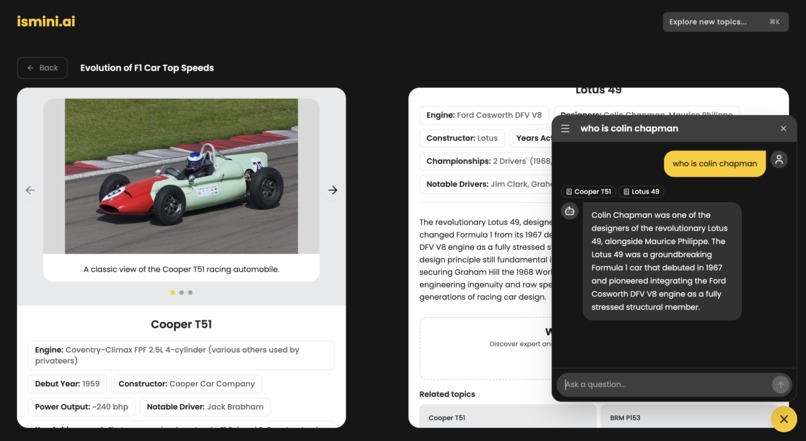
- Contextual Chat: It features a built-in assistant that understands the specific timeline you are viewing, allowing you to ask follow-up questions without losing context.
- Visual Intelligence: The system automatically identifies and fetches high-quality, relevant imagery from Wikidata/Wikipedia to match the narrative.
How we built it
We architected ismini.ai as a Multi-Agent Swarm using a modern, high-performance stack:
- Core Engine: Built with FastAPI for the backend and Pydantic AI for agent orchestration.
- LLM: We used Google Gemini 3 Flash as our primary LLM, leveraging its long-context window and speed for exhaustive research.
- Search and Memory: We implemented pgvector on PostgreSQL to handle semantic discovery, allowing users to find narratives through conceptual meaning rather than just keywords.
- Async Architecture: Because high-quality research takes time, we built a robust background processing system using Celery and Redis to handle agentic tasks without making the user wait on a loading screen.
Challenges we ran into
- Agent Orchestration: It was difficult to ensure that 10 different agents (Curators, Researchers, Rerankers) maintained a consistent "narrative voice." We solved this by creating a base agent class that enforces strict Pydantic schemas for all inter-agent communication.
- Vector Disambiguation: Pure vector search often returned multiple semi-correct results (eg: confusing "AWS Graviton 1" with "AWS Graviton 4"). We had to build a specialized Reranker Agent that uses LLM reasoning and the curator's specific context to select the exact topic match from a pool of search candidates.
- Unit and Sorting Consistency: For visual charts and timelines to work, the LLM must generate perfectly normalized data. We had to enforce strict "Base Unit" normalization (e.g., converting all lengths to meters, even if displayed as micrometers) and explicit sort_strategy definitions (TIME vs. VALUE) within the system prompts to ensure data could be compared and sorted programmatically.
- Image handling: Handling third-party images for timelines is notoriously difficult. We had to build a custom backend image intelligence service that validates and proxies imagery to ensure a smooth, broken-link-free UI.
Accomplishments that we're proud of
- Zero-to-One Narrative Generation: We're incredibly proud of the "Magic Moment" where a user types a three-word prompt and, 15 seconds later, is presented with a 10-stop, image-rich interactive history.
- The Contextual Chat: Getting an AI to "remember" the specific timeline it just generated for the user felt like a breakthrough in making AI feel like a true research partner or a reading partner.
- Architecture Efficiency: We managed to keep the system responsive even while running 5+ concurrent agentic web searches per query.
What we learned
- Agentic vs. Linear: We learned that Agentic Workflows (letting the AI decide its own research steps) are exponentially more powerful than traditional, linear prompt-chains.
- Structured Data is King: Using Pydantic to enforce "typed" AI responses (using pydantic-ai) makes the LLM outputs more robust and fail-safe.
- LLM Reasoning Depth: We discovered that modern LLMs, when equipped with web-search tools and specific narrative personas, can uncover deep historical and technical correlations that traditional search algorithms simply miss.




