-
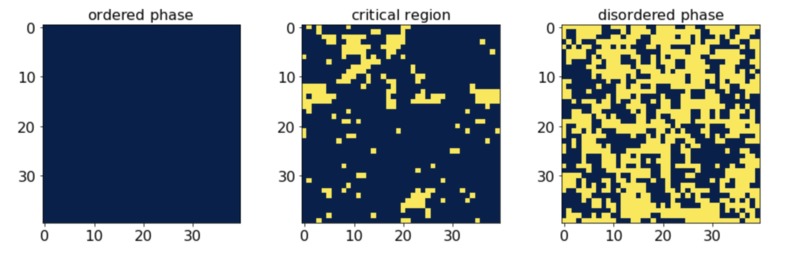
Three samples of the data
-
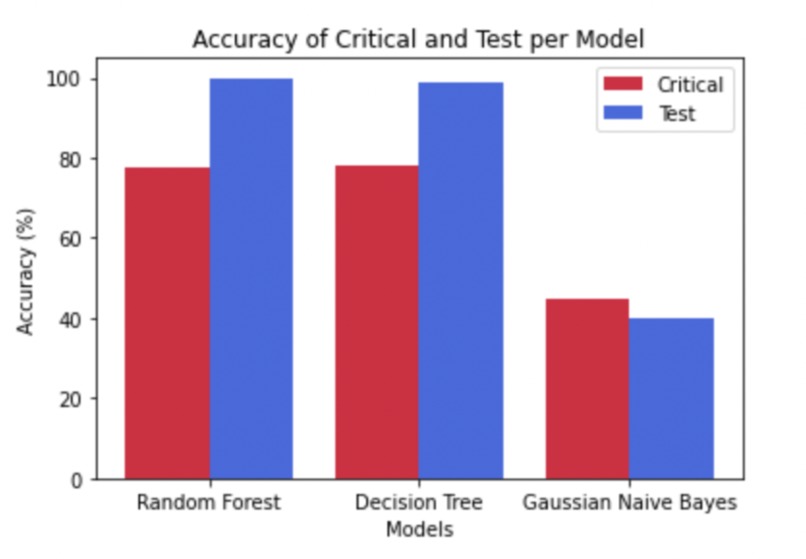
The first approach accuracies
-
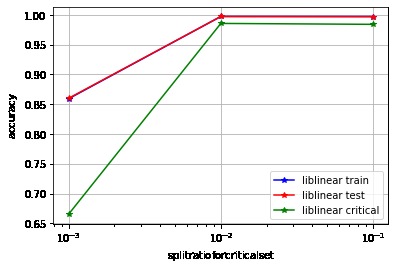
Logistic Regression performance using split ratios for the critical set for training


Inspiration
Our project is a phonon classification problem, drawing from the following paper (https://www.sciencedirect.com/science/article/pii/S0370157319300766). In this paper, the authors generated Ising model samples using Markov Chain Monte Carlo algorithms, attempting to classify them into ordered and disordered phases. The task was to write code that could only take the spin configurations as the input and then categorize the Ising state information into two categories. They used different supervised machine-learning models to perform the task. The models included: a simple logistic regression, random forest and two neural network models. Our goal is to improve their code, particularly around the critical region, and to try new models.
What it does
We take two approaches to solve this problem. One is to find alternative models from the Scikit-learn library to solve the classification problem in a timely manner. The other approach, which is a huge success, is to improve the logistic regression. We improved the classification accuracy for the critical samples from around 65% in their code to about 98%.
How we built it
Approach 1: We try to build our versions from the following models: Decision Tree, Random Forests, SVM, and Gaussian Naive Bayes.
Approach 2: We notice that when we run the logistic regression in the 1600 features (i.e., the spin configuration of each site), we get a convergence error. Therefore, we include the critical set in training. In the paper cited above, they decided to only train the model using the solely ordered and disordered sets and neglecting the critical set. However, we speculate that the most informative set for training the model is the critical one. Therefore, ignoring it will worsen the performance of the model. We define two measures of "orderness". The first one, which we call order_value, assigns each Ising state a specific value between 0 and 1. We add the number of the aligned spins adjacent to each other, multiply and square the result. We rescaled it to be between 0 and 1, where 0 represents the most disordered Ising state, and 1 represents the most ordered state. The second measure computes the number of aligned components. We finally split the data differently and found no issue fitting a logistic regression model to each measure separately. We reached very high accuracy when training the model with 50% of the data.
Challenges we ran into
Approach 1: The SVM model never finished running (stopped after 6 hours, costly).
Approach 2: When we combine the two measures in the logistic regression, we get worse performance for the critical set than only fitting with the first measure.
Accomplishments that we're proud of
We are proud that we managed to enhance the logistic regression in an efficient way, which allowed us to use the critical set and a sub-set of the original, to achieve better classification accuracy by defining a measure we compute from the spin configuration.
What we learned
We implemented 4 machine-learning models which are: decision tree, random forest, Gaussian naive Bayes and support vector machine in pursuit of the highest accuracy. This offered us the opportunity to gain hands-on experience with various ML models and data analysis. Also, we enhanced the logistic regression model accuracy by introducing a data preprocessing step.
What's next for Ising model classification
We are planning to use Bayesian optimization for estimating excursion sets (level sets), which should allow us to train the model using the critical set without specifying which sets are critical.





Log in or sign up for Devpost to join the conversation.