-
-

Isiko's Avatar Experience
-
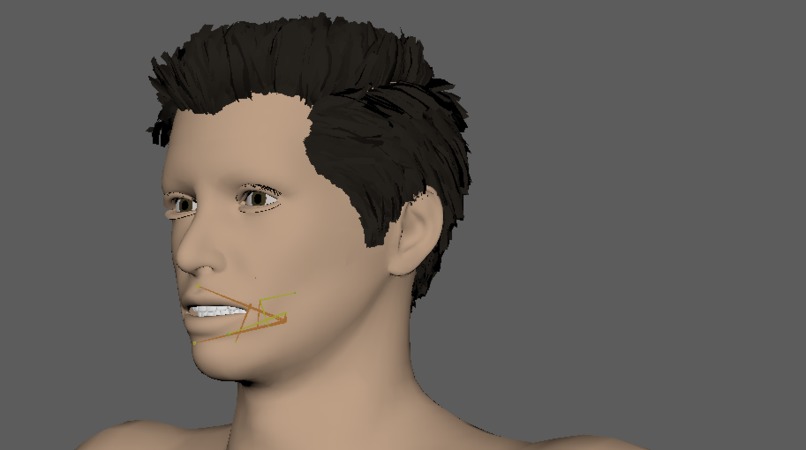
A glimpse into the inner workings of the avatar
-
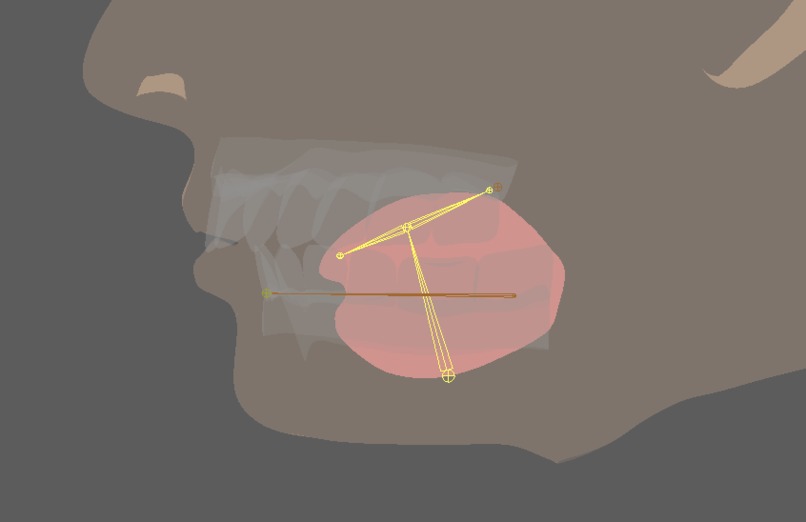
A midsagittal view of the avatar


Inspiration
At the heart of most language platforms are written components. This raises numerous challenges our app attempts to solve.
The name of our app, Isiko, is the Xhosa language word for “culture.” Our team was keen on tackling the issue of preserving low-resourced languages, which grow closer to extinction over time. We propose a new axis of storing and disseminating language information, breaking away from the traditional "speech"/"script" corpus formats.
Moreover, it provides opportunities for individuals with speech impediments, paralysis, or other physical disabilities, to engage in communication.
What it does
Isiko is a multilingual, multispeaker avatar system based on 3D motion capture of the vocal tract (electromagnetic articulography).
The first feature of Isiko is real-time speech-driven avatar animation. As you speak into a microphone, a streaming virtual avatar will be animated, modeling your vocal tract with high fidelity. This feature in particular could be utilized for tutoring new language-learners and providing reference for how they can correct mispronunciations and other grammatical errors.
On top of the avatar imitating our facial and vocal movements during speech, the avatar can also engage in natural multilingual conversation with the user. This both provides the user a natural interface for communication, but also the opportunity to learn from and imitate an expert trained to enunciate in a language of interest.
How we built it
To achieve our low latency results, we take a two-stage training approach. Since our paired dataset of speech and 3D vocal motion capture is small, we first use the powerful latent knowledge of self-supervised speech features to train a strong slow offline model.
Using this model, we then pseudolabel VCTK, a large multispeaker English dataset. This corpus allows us to train a causal generative model tailored towards streaming avatars from speech. We condition our predictions on the current batch of speech as well as previous predicted EMA, to infer what the new EMA will be (a HiFi-CAR model). For our real-time facial mimicking page, we utilized Flask to build a backend that streams requests to the model on the server as the user speaks. We powered the conversational avatar using OpenAI’s API endpoints, alongside other endpoints for transcribing & manipulating audio. For development of our website, we utilized a combination of Reflex and more standard web development languages like JavaScript.
Challenges we ran into
One of the most prominent challenges that we faced was the task of integrating 3D renders onto a website. Along with the challenge of learning an entire new framework in three.js, we also had to navigate a forest of dependency and import errors when trying to integrate three.js with Reflex. Another challenge was the problem of mapping just six point locations from inside the mouth (i.e. tongue tip, lips, jaw) into a fully-fledged avatar. The final difficult challenge that we ran into was the task of integrating the model into an actual website. This was due to the streamed nature of the technology – we relied on being able to reconstruct facial movement in real time. This was not fully compatible with an environment where our frontend needed to send every sample to a server to input into the model, and then the server needed to send data back to the frontend to update the visualization.
Accomplishments that we're proud of
We're most proud of the fact that we're amongst the first groups in academia and general industry to work with real-time speech to avatar technologies. We really stuck through our highs and lows this weekend, from the conversion of speech to EMA, to wrangling with 3D, to navigating LLM responses. We’ve achieved a great offline product and are super close to a low latency streaming avatar. Nonetheless, we're proud of having taken a stab at this issue as we've already learnt so much within these past two days.
What we learned
This project was incredibly insightful for learning about the inner workings of the mouth during speech production. After training our model, we were able to experiment with how well the model would generalize to vocal behaviors that were not present in the training data – one super interesting example of this was the click consonants used in Xhosa. We also learned just how difficult it is to build and deploy a website. There are so many moving parts to building a website, and the task of integrating intense visualizations and hosting demanding models into this already challenging ecosystem was a very instructive experience.
What's next for Isiko
We think there's impactful potential our product can create across numerous industries. Speech avatars could assist with the preservation and teaching of low-resource languages, particularly those lacking written form, as we bypass the step of written text when converting from speech audio to facial movement. These avatars also synergize with current-day advancements in video games and virtual reality – the reconstruction of facial expressions for avatars using players’ in-game verbal communication will facilitate a more authentic and interactive gaming experience. Lastly, in the medical field, our technology that turns speech audio into facial expression could empower those afflicted with forms of paralysis with a powerful tool for communication.


Log in or sign up for Devpost to join the conversation.