-
-
Poster
ishara
Final Writeup
https://docs.google.com/document/d/1qc4dv9OIP-N8LYkR5_jE1z-vDzRCXuX1Lwvw0cB01pc/edit?usp=sharing
Title
Ishara (Arabic/Urdu word for the English word ‘Sign’)
Who
Moustafa Makhlouf (mmakhlou), Fatimah Alshaikh (falshaik), Muhammad Haider Asif (masif)
Introduction
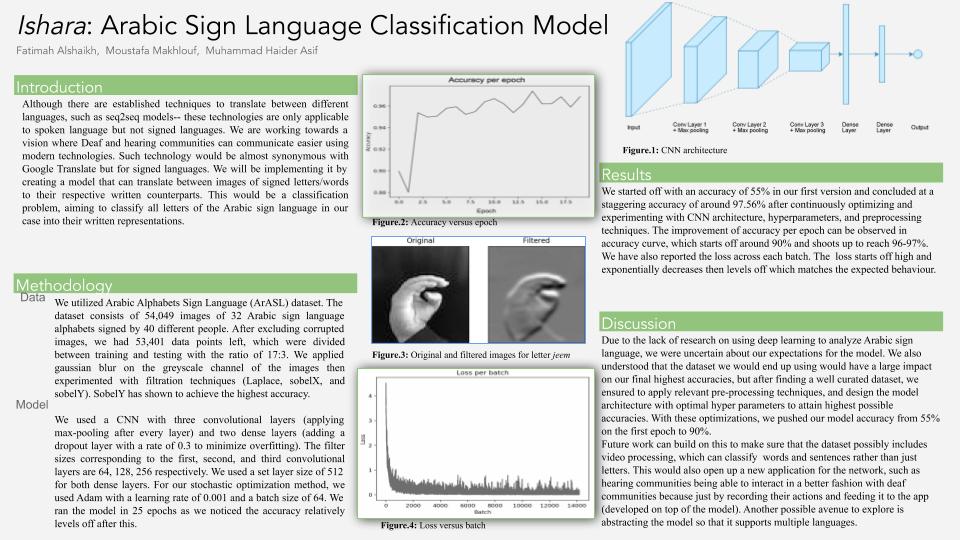
Although there are established techniques to translate between different languages, such as seq2seq models-- these technologies are only applicable to spoken language but not signed languages. We are working towards a vision where Deaf and hearing communities can communicate easier using modern technologies. Such technology would be almost synonymous with Google Translate but for signed languages. We will be implementing it by creating a model that can translate between images of signed letters/words to their respective written counterparts. This would be a classification problem, aiming to classify all letters of the Arabic sign language in our case into their written representations.
Related Work
As we mentioned before, there hasn’t been much work that’s been done in this field before, but we did find a model that translates ASL letters from images into their corresponding written letters. We do not intend to replicate this design or approach, or even use the dataset, which is part of why we chose to tackle a different sign language than the American Sign Language. We want to acknowledge previous efforts in tackling a similar problem.
https://arxiv.org/pdf/1710.06836v3.pdf
https://www.sciencedirect.com/science/article/pii/S2352340919301283
Data
We will be utilizing Arabic Alphabets Sign Language (ArASL) dataset. This dataset has 54,049 images of 32 Arabic sign language alphabets which are signed by 40 different people. Source: https://www.sciencedirect.com/science/article/pii/S2352340919301283
We plan on preprocessing these images by centering these images, resizing, converting to grayscale and removing noise using Gaussian filters. To make sure we extract meaningful features from these images and improve our accuracy, we plan on using edge detection techniques using Laplace and/or Sobel filters. We also plan to divide the dataset into training and testing sets with a ratio of 0.85-0.15. We will preprocess the images to create folders for train and test, and split the labels csv accordingly too. After separating the data into training and testing sets, we will create a pickled file for each, where each file will contain images and their labels. When running the model, we would unpickle these files and pass them on to the model.
Methodology
In our project, we intend to use convolutional neural networks to classify different letters of Arabic sign language, by using hand images as our dataset. In addition to creating our own dataset, we are going to construct a unique CNN architecture that would allow us to get the best accuracy on the test dataset. We plan on experimenting with different hyperparameters, activation functions, and layers and report our findings for each letter and all of them combined. Initially, we plan on using RELU activation function after every block of CONV2D layers and apply max-pooling after each convolutional layer except the last one. After the stack of convolutional layers, we’ll have a stack of dense layers , we also plan to then apply dropout after each dense layer except the last one. Finally, we plan on using softmax cross entropy of our loss.
Metrics
We will be reporting two types of accuracy to measure the performance of our model. First, we will be calculating the overall model’s accuracy, which would report the percentage of images classified correctly over the size of our testing dataset. In addition to that, we think it is important to report per-letter accuracy. This is relevant because there are some letters in Arabic Sign Language which look very similar, which might skew the overall accuracy. So, reporting per-letter accuracy can give us an insight if there are outliers the model should improve on.
Ethics
Who are the major “stakeholders” in this problem, and what are the consequences of mistakes made by your algorithm?
Answer:
This model is directed towards hearing communities to help them better communicate with the Deaf community. The general population is unaware of the representations of letters in Arabic sign language, and this model overcomes that barrier in communication between both communitiethis. Stakeholders in s problem are firstly the Deaf community, since the output of the model would essentially act as translation medium for their expression. Secondly, it allows the hearing community to understand the communication signs of the Deaf community. Mischaracterization from the model of some sign language letters would lead to miscommunication between the two parties which could potentially defeat (or worsen) the cause of the development of the model.
What is your dataset? Are there any concerns about how it was collected, or labeled? Is it representative? What kind of underlying historical or societal biases might it contain?
Answer:
Our dataset defined above has been collected from only 40 individuals. The citation of the data doesn’t mention the race of the individuals nor their age, but upon inspecting the images, it seems like the dataset includes both male and female participants. Moreover, the dataset doesn’t include a variation in lighting, location, noise, or camera angle. These are all limitations of the dataset that we are aware about. We understand that based on this collected data, our model may not be effective across all variations of the variables not accounted for in the dataset.
Division of Labor:
Preprocessing: Fatimah
CNN implementation: Fatimah, Haider, Moustafa
Train & test: Moustafa
Results analysis & Optimization: Haider






Log in or sign up for Devpost to join the conversation.