-
-
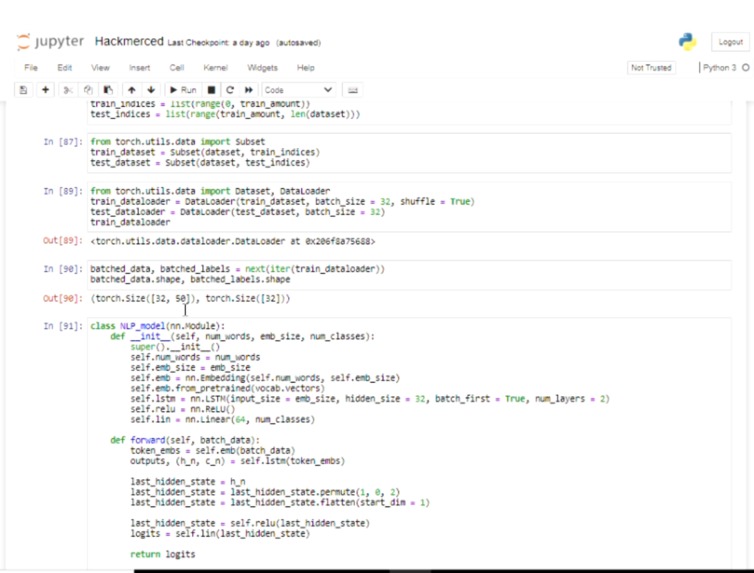
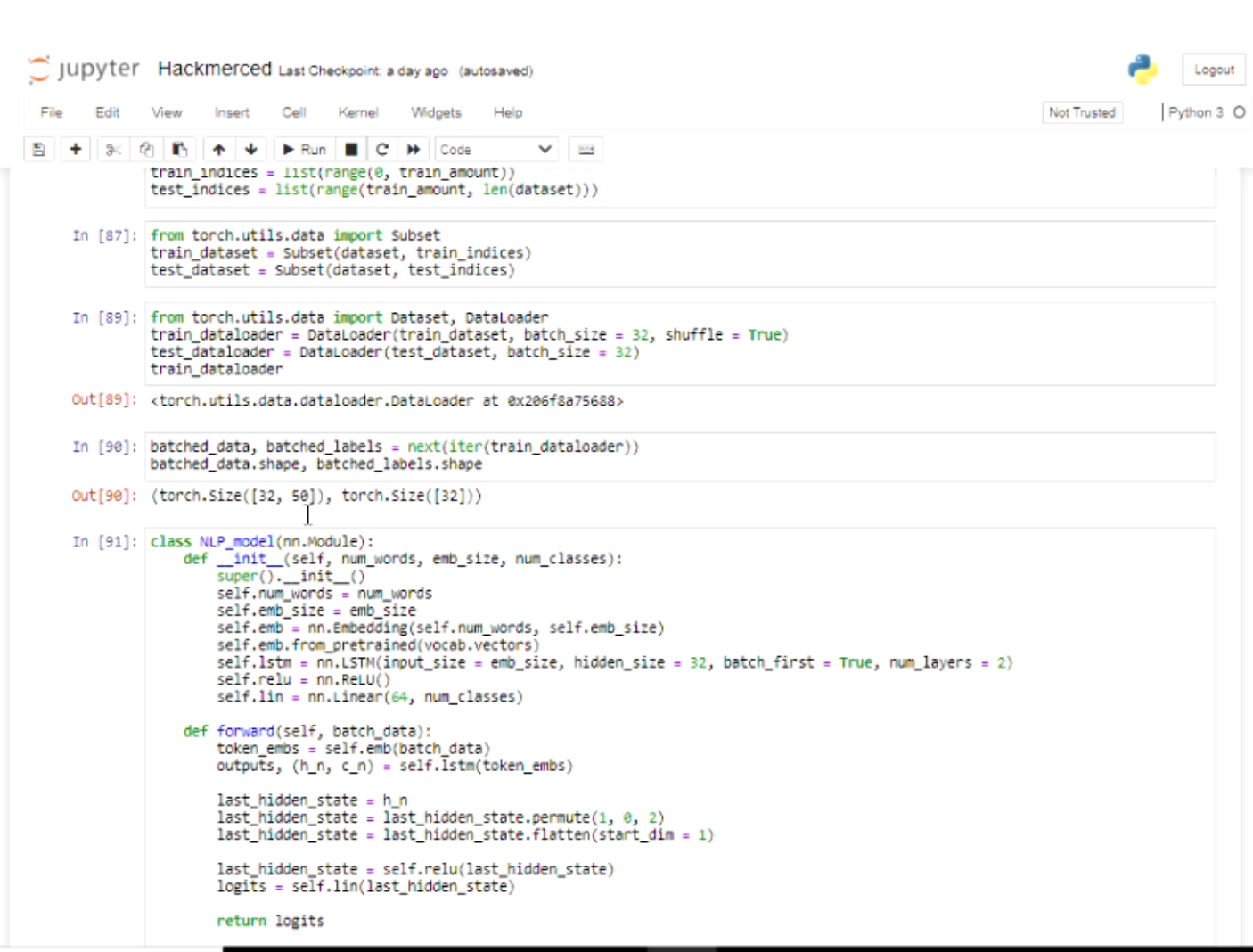
NLP Model
-


Inspiration
We found inspiration by looking at the large amounts of websites that contain unreasonable amounts of derogatory terms or offensive speech. This language may have unforeseen effects on an unsuspecting user. To minimize this, we wanted to build a platform that would allow us to verify the "safety" of a site and warn users beforehand. So, we focussed our project on analyzing the "security" of a site to prevent users from entering areas containing cyberbullying, cyber harassment, obscene language, and hate speech.
What it does
Our website takes in a user inputted URL and classifies the safety of the site for a user. We classify the site based on three filters: profanity, hate speech, and safe. We also keep track of the most frequented sites that are either dangerous or safe to allow our users an easy-to-access list of options to check out or avoid.
How we built it
We built the website using Python Flask, Jinja2, and HTML/CSS. The website was able to become dynamic because of Jinja2 which allowed easy integration with the data from our server.
When the user submits a URL, we have our Selenium web-driver pull the raw HTML ( which includes the javascript-loaded text ). We then pass this to BeautifulSoup to parse and filter the data. After this, we pass the data chunk by chunk into our natural language processing model. The model then outputs a classification on the type of text entered: profanity, hate speech, other. We then use this to classify the overall website.
Challenges we ran into
We had a lot of challenges with building the natural language processing model itself. These issues ranged from minor syntax and formatting problems to larger problems with the training of the model. Luckily with the assistance of the mentors and hours of tinkering, we were able to work through these problems and arrive at our current working solution.
We also struggled with the data used to train the model. We were unable to find clean and diverse datasets, so we had to learn and use a lot of methods to make it usable and efficient. In the end, we were able to make the dataset work well when training our model and the result turned out pretty well!
Additionally, we found that the web drivers used by our web crawlers were not compatible with Heroku. It took us a couple of hours of research and tinkering to find roundabout methods to setup Heroku as well as our code to be compatible.
Accomplishments that we're proud of
One of our team members is a first-time hackathon participant and a new programmer. We were very excited to be able to work with him to complete and submit his first hackathon project!
We are also very proud of being able to successfully build the natural language processing model and deploy it onto a website. The model took a lot of time and effort so it was relieving and exciting to see it come together!
What we learned
We were able to learn a lot about working with PyTorch, natural language processing, and data science in general. With the assistance of the mentors, we believe that we were able to gain a much deeper understanding of these topics. We were also able to learn more about working with Python Flask and Jinja2 to make web applications.
We learned about the process of NLP and the different ways one can make a given dataset viable for training and the different types of NLP models that could give us more precise accuracy. The mentors were able to explain the different applications for NLP and also demonstrated to us the resources we could use in the future to create a model more efficient with the raw data we present it with.
What's next for Is It A Safe Space
We plan to refine our natural language processing model to run faster and more accurately. We hope to get a more diverse spread of data to train our model as well. Additionally, we are looking into making more applications of this model, such as a discord bot to monitor a safe online environment.



Log in or sign up for Devpost to join the conversation.