Ironsite
Inspiration
The construction industry is the backbone of our economy, yet its productivity has remained nearly stagnant for decades. Research from the Richmond Fed shows that while other sectors have modernized, construction still suffers from fragmented data and manual oversight.
The missing link is not more labor — it is spatial intelligence: the ability to understand exactly how a site moves and builds in real time.
We set out to give superintendents “eyes on the ground” that never blink.
What It Does
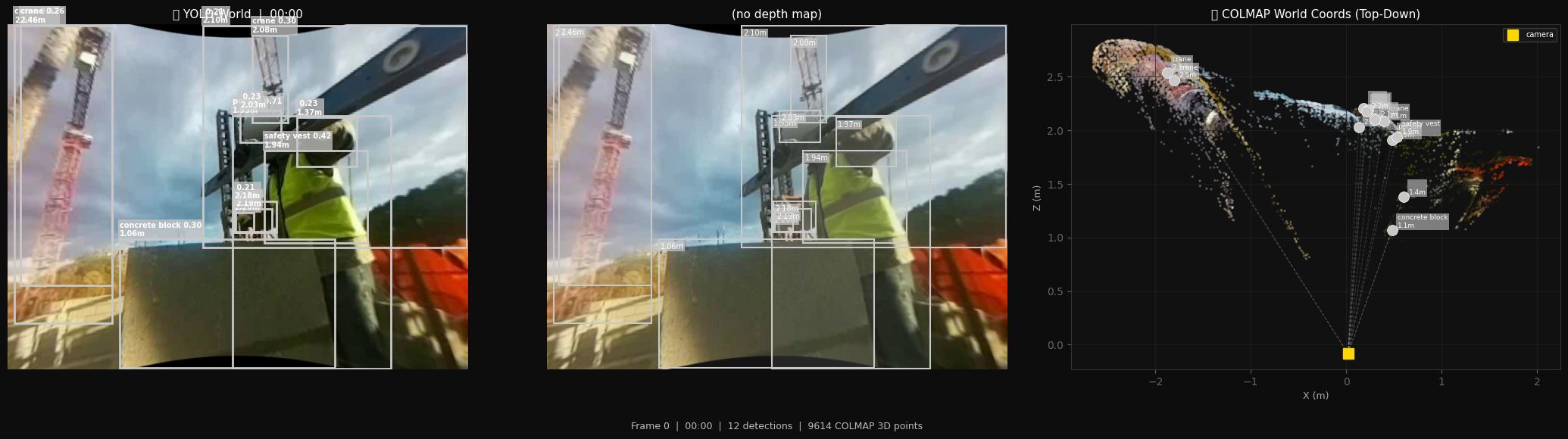
Ironsite turns standard body-cam footage into a structured 3D intelligence layer for any construction site.
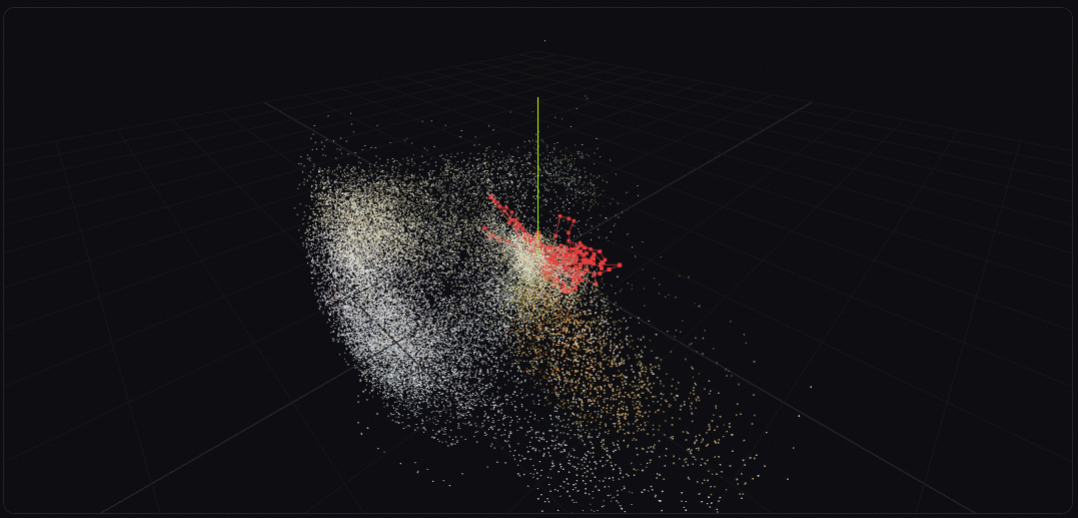
3D Scene Reconstruction
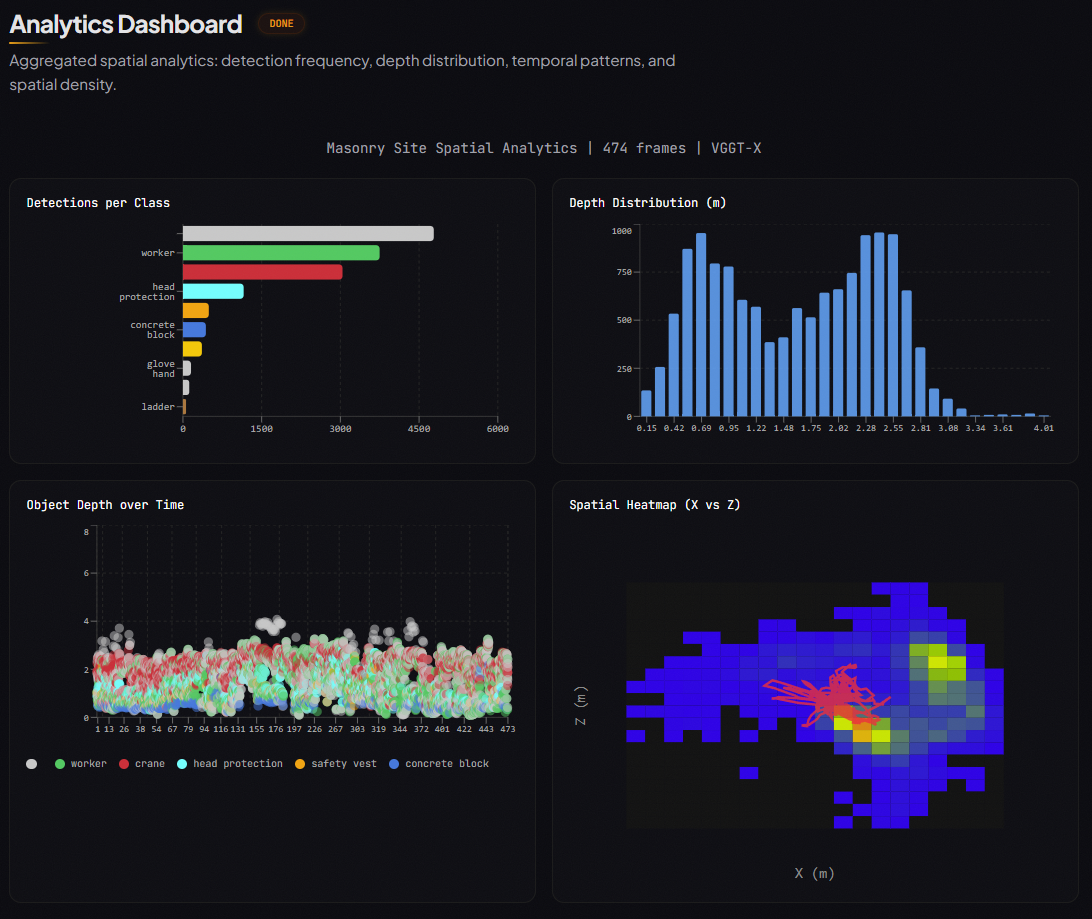
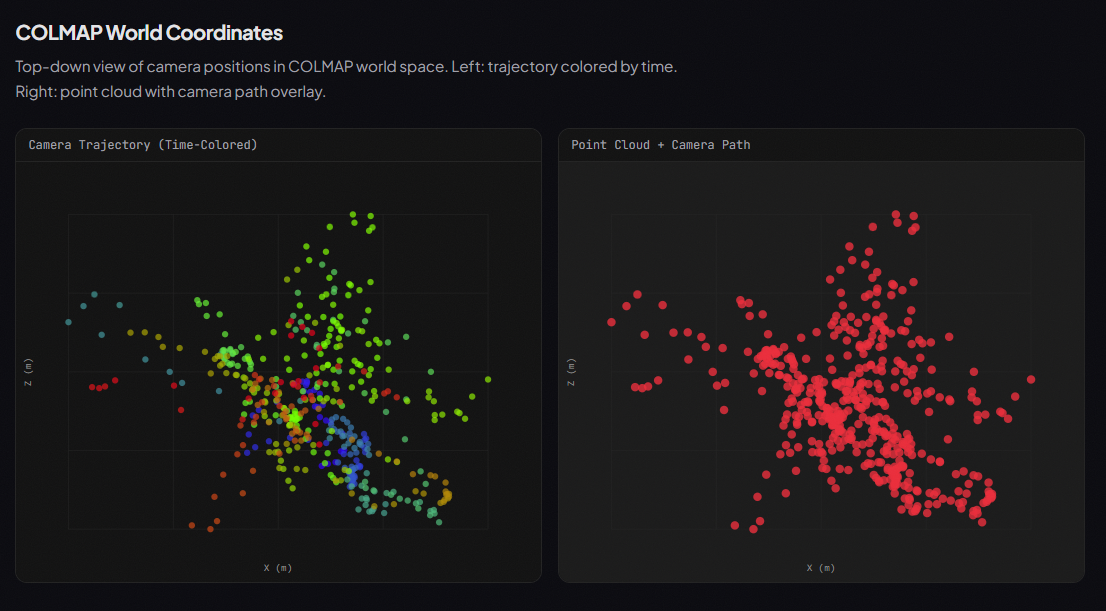
Generates a full point cloud with camera trajectory, mapping worker paths and precise coordinates of materials like concrete blocks, rebar, and tools.
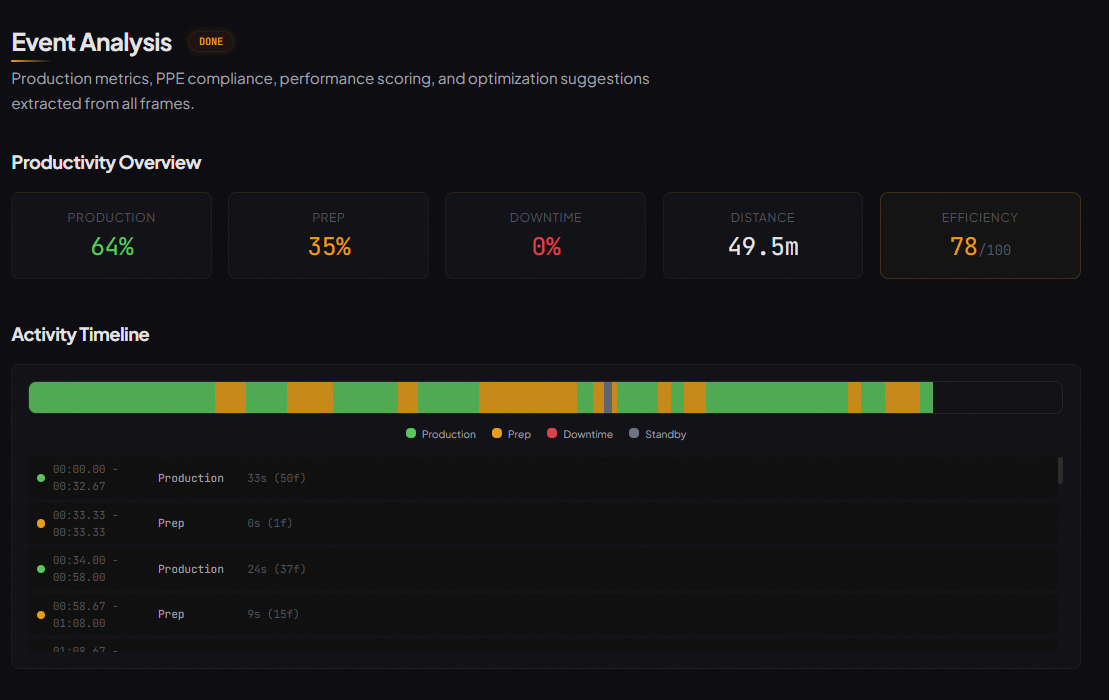
Productivity Analytics
Automatically classifies every second of footage into:
- Production
- Prep
- Downtime
- Standby
Delivers an efficiency score and time breakdown.
Safety & Compliance
Audits PPE in every frame — detecting hard hats, vests, and gloves — and flags concerns before they become incidents.
Spatial Memory
A FAISS-indexed knowledge base lets you query the scene:
- “Show me every frame where a hand was within 1m of a tool.”
- “Find all blocks at depth > 3m.”
How We Built It
We engineered a 9-stage AI pipeline that bridges flat video and 3D reality:
Preprocessing
Fisheye undistortion and adaptive keyframe extraction from body-cam footage.Detection
Grounding DINO for open-vocabulary object detection — no fixed class list required.Tracking
SAM2 propagates detections across frames with pixel-perfect segmentation masks.3D Reconstruction
We reverse-engineered VGGT-X to extract internal metric depth maps, camera poses, and dense point clouds.
The model was not built to expose these intermediate representations directly. We traced its architecture, extracted the right token representations, and converted them into usable metric depth and 6-DOF camera poses — effectively repurposing a foundation model for a new task.
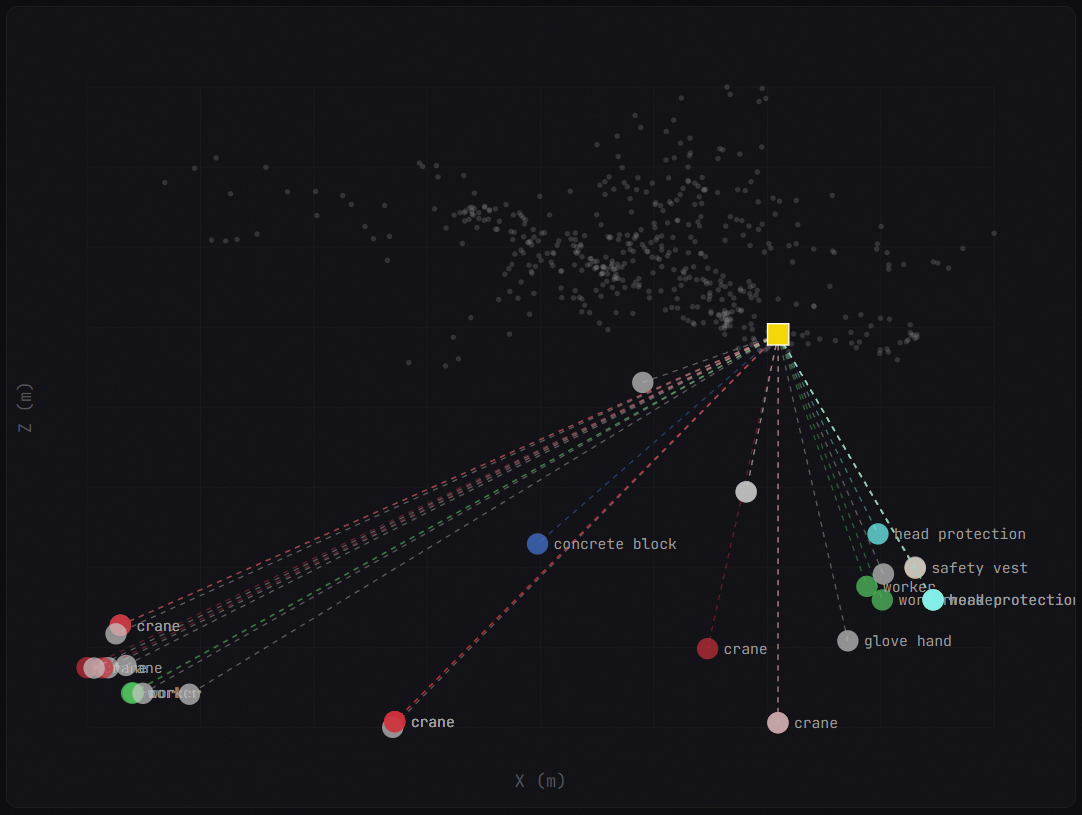
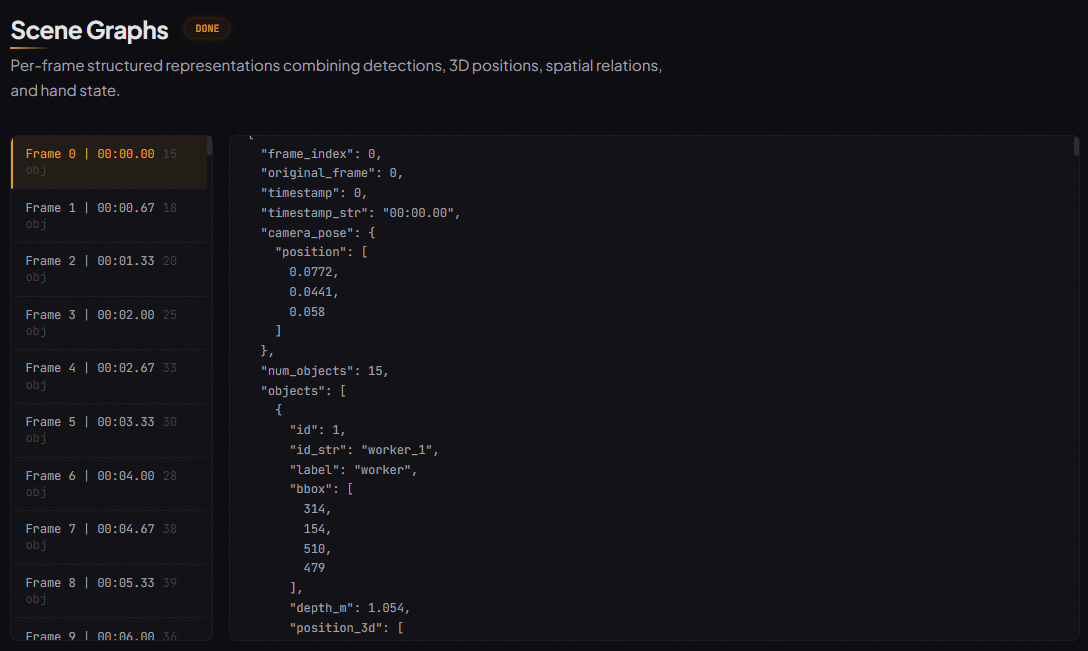
Scene Graphs
Per-frame structured representations that fuse detections with 3D coordinates, spatial relations, and hand state.Knowledge Graph
A NetworkX spatial graph encoding object relationships, proximity, and temporal co-occurrence.Event Engine
Rule-based activity classification, PPE auditing, performance scoring, and optimization suggestions.Spatial Memory
FAISS vector indexing over scene graphs for sub-millisecond spatial queries.VLM Narrator
Grok synthesizes everything into a human-readable site intelligence report.
Frontend
A story-driven React dashboard featuring:
- Three.js 3D visualization
- Real-time WebSocket updates
- Framer Motion animations
Each pipeline stage unlocks a new chapter as it completes.
Challenges We Ran Into
Construction sites are chaotic environments. Body-cam footage includes:
- Heavy fisheye distortion
- Aggressive motion blur
- Constant occlusion
We solved distortion through custom preprocessing.
The biggest engineering challenge was reverse-engineering VGGT-X. It was not designed to export depth maps and camera poses as standalone outputs. We traced internal token structures, extracted intermediate representations, and converted them into usable metric depth and 6-DOF camera poses.
Running DINO + SAM2 + VGGT-X per frame is computationally expensive.
To address this:
- We implemented token merging (FastVGGT) for ~4× speedup.
- We parallelized the pipeline with a ThreadPoolExecutor.
- We kept WebSocket updates responsive while GPU inference runs in the background.
Accomplishments We’re Proud Of
- Metric-accurate 3D reconstruction from a single moving body camera
- No LiDAR, no depth sensors, no multi-camera rig
- Successfully repurposed a foundation model beyond its intended design
Seeing a worker’s trajectory plotted through a colored point cloud alongside real-time PPE compliance and production scores felt like a genuine breakthrough in job site intelligence.
What We Learned
Spatial context is everything.
AI can detect a “person” and a “ladder.”
But spatial intelligence knows:
- That person is 0.5m from a trip hazard
- They are not wearing a helmet
- The interaction creates measurable risk
We also learned:
- Foundation models contain rich spatial representations internally.
- A unified scene graph is the most powerful abstraction for construction data.
- Once you have objects, positions, relations, and time — every downstream task becomes a graph query.
What’s Next for Ironsite
We are moving from retrospective analysis to real-time edge alerts.
Immediate Goals
- Streaming inference on body-cam feeds
- Real-time safety notifications
Future Expansion
- Integrate BIM data
- Compare live 3D reconstruction against blueprints
- Detect deviations the moment they happen
Goal: Make the site not just visible — but predictable.
Built With
- faiss
- fastvggt
- grok-3
- opencv
- python
- react
- sam2
- typescript
- vggt-x

Log in or sign up for Devpost to join the conversation.