Ironbook
Preserve the knowledge of every expert on your shop floor before they walk out the door.
Awards
Grandprize (5k) - Ddoski's Toolbox
Inspiration
11,000 Americans turn 65 every single day. By 2027, 4.1 million workers will hit retirement age, and nowhere is the damage more acute than manufacturing.
Skilled machinists, technicians, and engineers carry decades of irreplaceable knowledge: why a machine sounds different when a bearing is failing, which tooling setup works for a specific aluminum alloy, where the oil fill port hides on a 30-year-old press. A recent survey found that 57% of retiring Baby Boomers have shared less than half the knowledge needed to do their job and 21% have shared none of it. That knowledge walks out the door with them, permanently.
Passing it on the old way doesn't scale. A typical apprenticeship takes 4–5 years. Meanwhile, 584,000 manufacturing jobs sat unfilled in January 2024 alone.
We built Ironbook to close that gap, not with manuals or videos, but with a living, queryable 3D model of the physical world, paired with an AI agent that can navigate it in real time.
What It Does
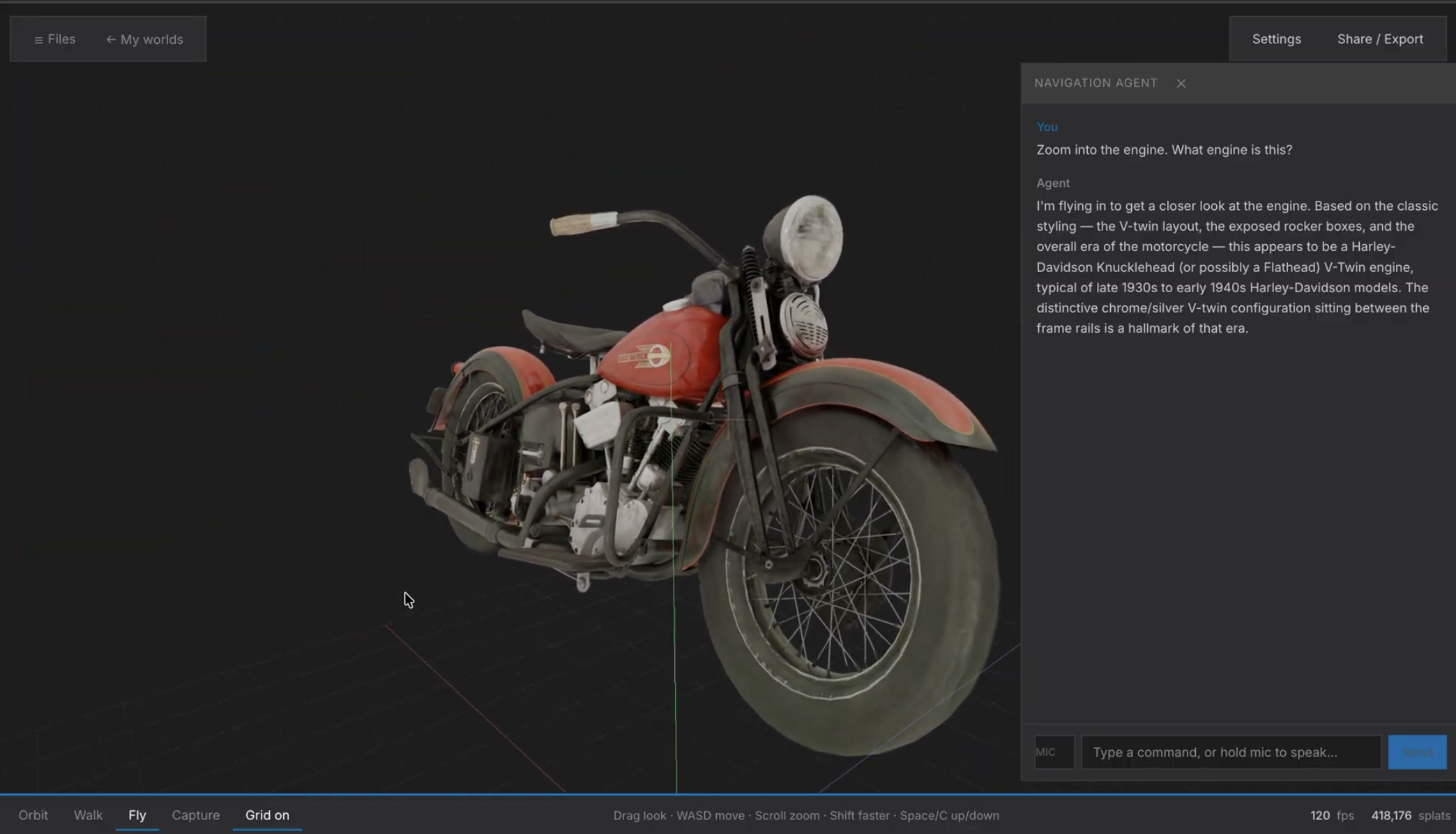
Take your phone, walk around a machine, a part, or a workstation, and photograph it from multiple angles. Ironbook reconstructs a photorealistic 3D Gaussian splat and pairs it with an AI agent that can navigate that scene in real time.
Instead of a static photo or a flat PDF manual, a new technician can:
- Ask natural questions — "What's that valve on the left side?" or "Show me the oil fill port."
- Let the agent navigate — the AI physically flies the camera through the 3D scene, zooms in, and highlights the object on screen
- Speak instead of type — voice input keeps hands free on the shop floor
- Build a living library — every scanned asset becomes a searchable, queryable record of institutional knowledge
The AI doesn't just describe where to look. It goes there, moving the camera through the scene spatially to answer the question in context.
How We Built It
Capture
Users upload 20+ overlapping photos of any object or space. The app provides a coverage score and warns about gaps in coverage.
Reconstruct: a 3-tier pipeline with no dead ends
- COLMAP runs structure-from-motion to recover precise camera poses and a sparse point cloud
- msplat — a Metal-accelerated 3DGS trainer — optimizes tens of thousands of 3D Gaussians on the Apple GPU, hitting ~24 dB PSNR in ~41 seconds on M-series chips
- MLX fallback handles CPU-only machines when Metal isn't available
- Depth-anything ONNX fallback uses monocular depth estimation for a navigable 2.5D reconstruction when no GPU pipeline is present
You always get something you can explore.
Query: an AI agent that acts, not just describes
An AI agent backed by Claude (vision + structured output) receives the user's message, a live screenshot of the current 3D camera view, and the current camera state. It returns:
- A natural-language answer
- A sequence of camera actions the frontend executes:
fly_to,look_at,highlight,rotate,zoom,move,reset_view, and more
The agent is connected to the viewer via an MCP-style action protocol, structured JSON that the frontend interprets and executes in real time as the conversation unfolds.
Render: a WebGL2 renderer built from scratch
A custom WebGL2 Gaussian splat renderer supports orbit, walk, and fly camera modes with WASD + mouse. It executes agent actions live, frame by frame, as the user asks questions.
Stack
| Layer | Technology |
|---|---|
| Frontend | React 18, Vite, TypeScript, custom WebGL2 renderer |
| Voice input | Deepgram SDK |
| Backend | FastAPI (Python 3.11+), uvicorn |
| Reconstruction | COLMAP → msplat (Metal) → MLX 3DGS → depth-anything ONNX |
| AI agent | Claude claude-3-5-sonnet, vision + structured JSON output, multi-turn history |
| Observability | Sentry (errors, transactions, Anthropic integration), Langfuse (LLM traces, token usage) |
Challenges We Ran Into
Getting real-time navigation to feel spatial. The core insight of Ironbook is that the AI doesn't describe the answer — it shows you. Designing the action protocol and getting smooth camera animation to execute agent instructions frame-by-frame required careful engineering on both the agent output schema and the WebGL renderer's animation loop.
Building a robust reconstruction pipeline. Real shop floors don't have studio lighting or perfectly overlapping photos. We built a 3-tier fallback system so the app produces something useful whether you have Apple Silicon and Metal tooling or just a CPU — while being transparent about which backend is running via a /api/health endpoint.
Grounding the AI in 3D space. Claude receives a screenshot of the current camera view as context. Getting it to reason correctly about spatial relationships (distinguishing left from right, near from far, what's occluded) required careful prompt engineering and structured output validation. The agent must reason about the scene in camera-space coordinates, not abstract space.
Handling HEIC from iPhones. Most shop floor photos come from iPhones. We added pillow-heif to transparently convert HEIC to compatible formats before they enter the pipeline, so users never have to think about file formats.
Accomplishments We're Proud Of
- ~41-second reconstructions on Apple Silicon — fast enough for on-the-spot captures on the shop floor
- A custom WebGL2 Gaussian splat renderer built entirely from scratch, with orbit, walk, and fly modes, and real-time agent-driven camera control
- An agent action protocol that turns Claude's structured JSON output into live 3D navigation — not just chat, but spatial exploration
- A 3-tier reconstruction fallback so the app works on any machine, not just GPU-equipped workstations
- 77 tests across backend (27) and frontend (50), plus full TypeScript strict-mode coverage
- A full observability stack (Sentry + Langfuse) for monitoring AI performance and errors in production
What We Learned
The hardest part of AI spatial navigation isn't the AI: it's the interface between language and geometry. Getting the model to express camera intent in a way the renderer can faithfully execute required treating the output schema as an API contract, not a suggestion. Structured output validation was essential.
We also learned that degradation matters more than perfection. A rough 2.5D scene that you can query is infinitely more useful than a failed reconstruction. Every decision in the pipeline was shaped by the question: what does the user get if this step fails?
What's Next for Ironbook
- Multi-user shared scene libraries — a team-wide knowledge base where every scanned asset is searchable
- Video upload → automatic frame extraction — capture a walkthrough video instead of individual photos
- Semantic search across assets — ask "show me every hydraulic fitting we've scanned" across all projects
- On-device reconstruction — field use with no cloud or server dependency
- Export to standard formats —
.ply, GLTF for integration with existing CAD and ERP systems
Built With
react · typescript · vite · webgl2 · fastapi · python · colmap · msplat · metal · mlx · onnxruntime · depth-anything · claude · anthropic · deepgram · sentry · langfuse · mongodb
Sources: Dozuki — Silver Tsunami workforce prep · McKinsey — Tradespeople wanted · Higginbotham — Silver Tsunami HR · THE FUTURE 3D — Gaussian Splatting Accuracy
Built With
- fastapi
- next.js
- pytorch
- sentry





Log in or sign up for Devpost to join the conversation.