
Inspiration
One of us has a childhood best friend with Retinitis Pigmentosa (RP). It’s a condition that slowly tunnels your vision until you’re looking at the world through a pinhole and eventually, that pinhole closes entirely.
It is hard to be born without vision, but to have it taken away after you’ve already experienced the colors and the logic of the world is even harder.
We built Iris to be the bridge, a way to turn the visual chaos he is losing into a partner he can always talk to, able to execute tasks and remember context. Accessibility should be about understanding your intent instead of just reading pixels.
It’s our way of making sure that even when the vision fades, the ability to thrive, to create stays.
What it does
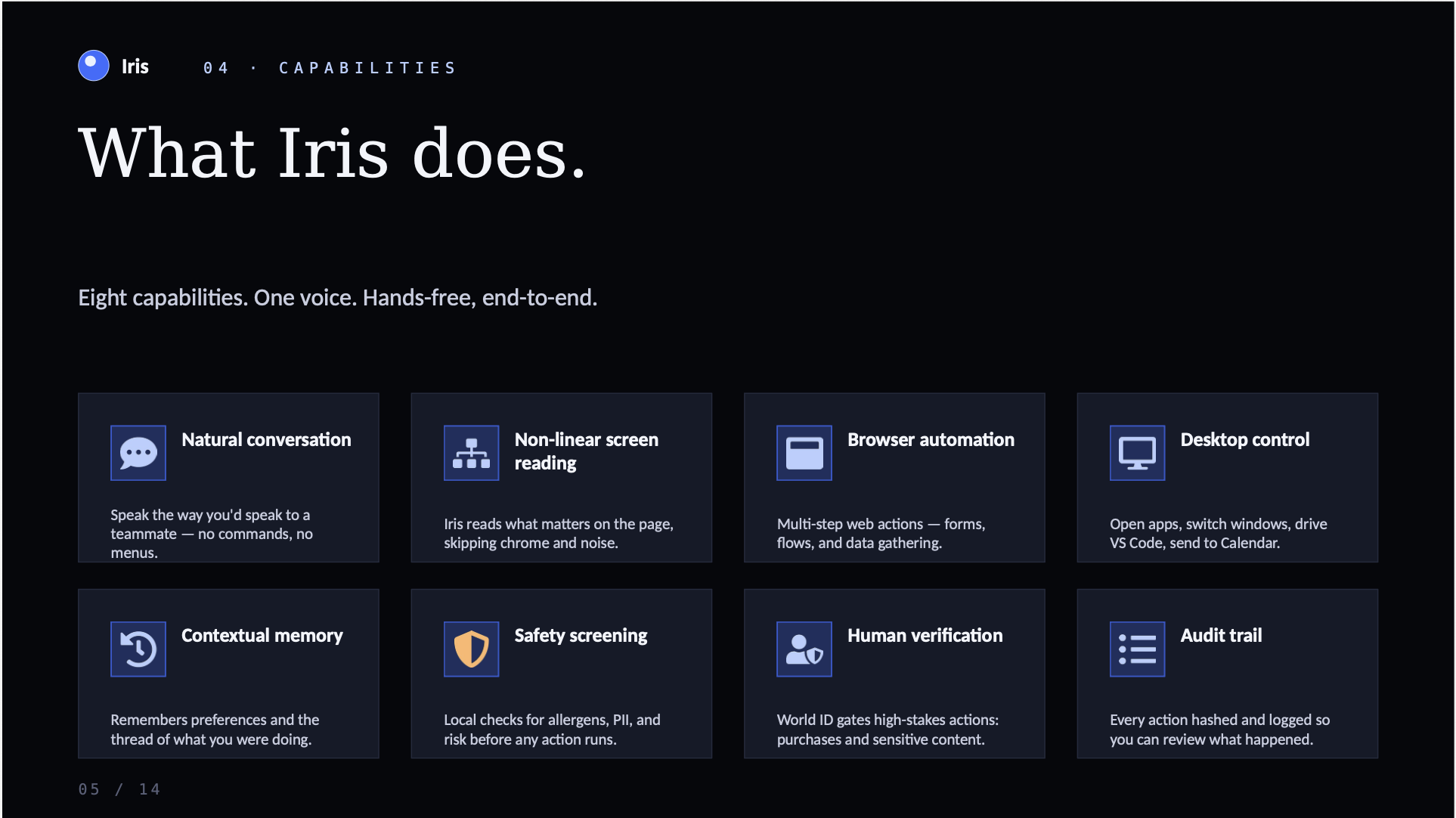
Iris is a voice-first accessibility agent that turns your operating system into a conversational partner.
Instead of reading every element on a page, she understands the underlying logic of your screen and summarizes what actually matters. She can execute complex tasks across the desktop and browser, from navigating messy web portals to managing workflows in VS Code.
What makes Iris unique is her attention to the nuances of your life. She maintains a memory of your personal context that a standard computer would ignore, like a peanut allergy or a brother's birthday. By combining screen understanding with personal memory, Iris acts as a proactive partner that handles the visual details so you can focus on your intent.
How we built it
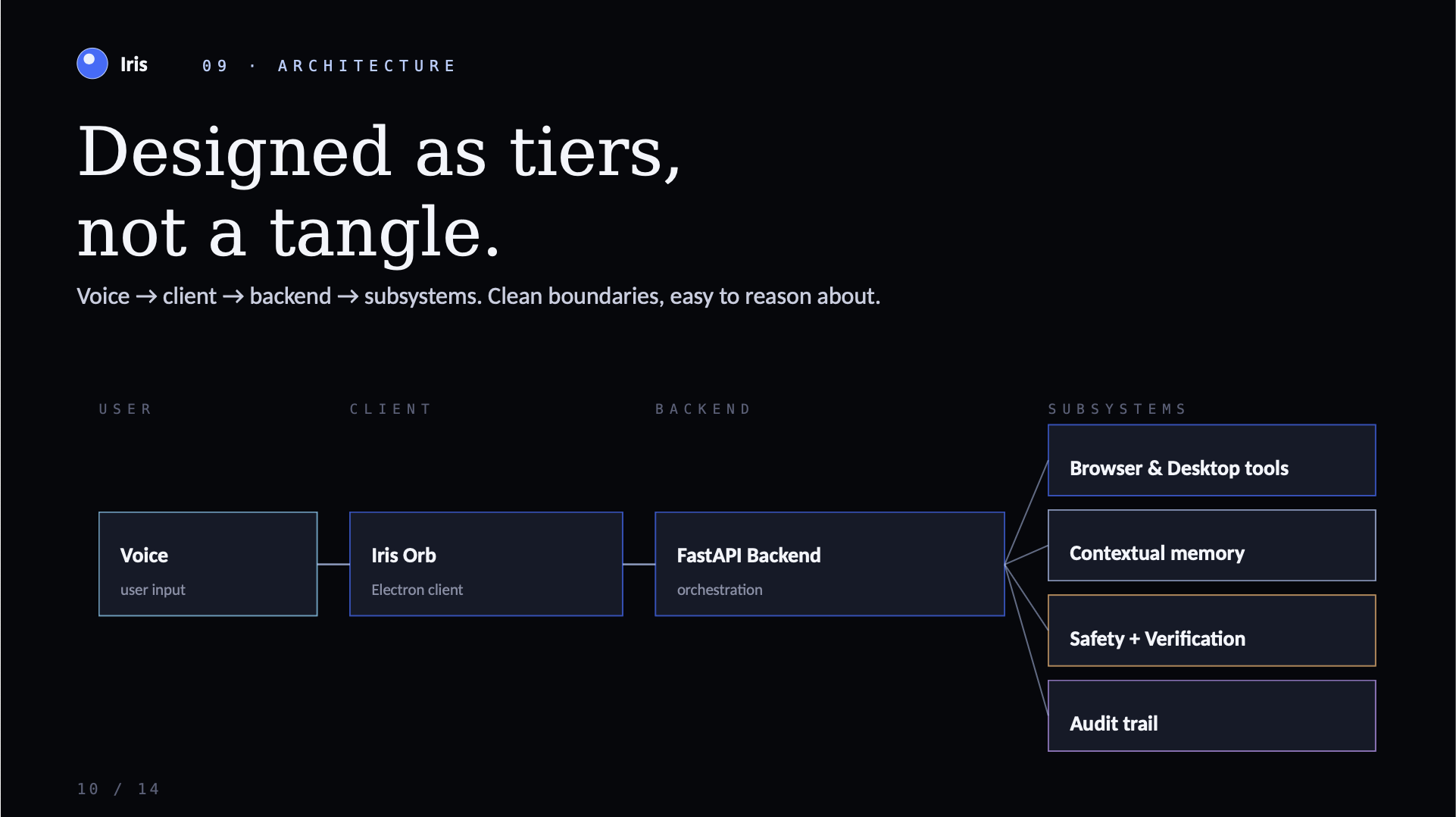
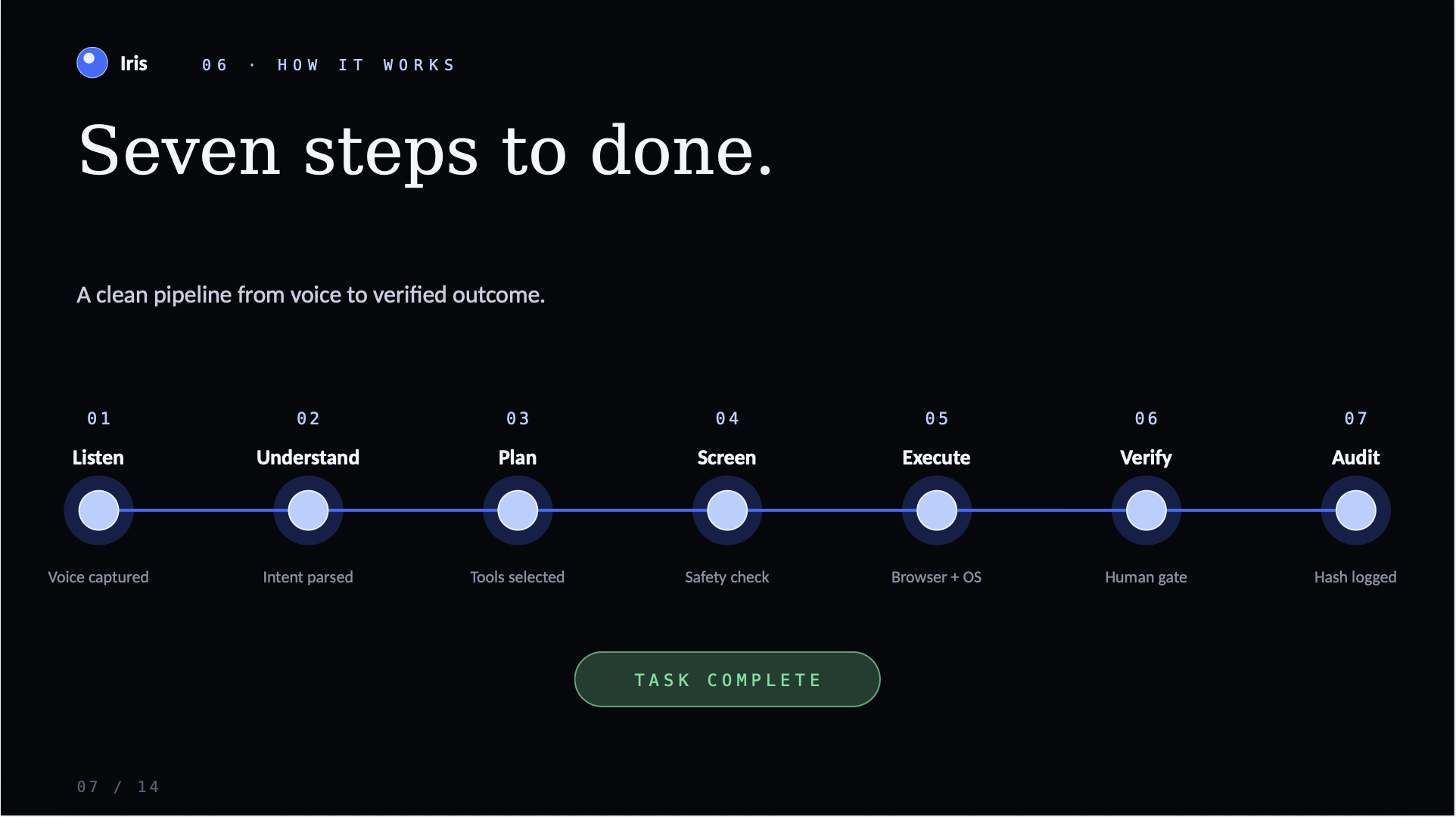
We built Iris as a “Head + Hands” system—conversation on top, execution underneath—with explicit routing, safety checks, and verification.
ElevenLabs (The Brain / Voice Session + Tool Calling) We used ElevenLabs Conversational AI to run the live conversational loop and streaming narration. Iris can call client tools to trigger real-world actions (open URLs, open apps, interact with pages) while keeping the conversation natural and low-latency.
Fetch.ai (The Orchestrator / Multi-agent Hands) We integrated a mission-based orchestration layer so Iris can delegate tasks to specialists (browser, OS, coding) instead of relying on one monolithic agent. The bridge routes structured missions, preserves context across handoffs, and returns execution results back to the brain for next-step planning and narration.
ZETIC + Gemma (Safety Shield) Before Iris speaks or acts on sensitive/medically relevant payloads (e.g., allergens, personal data), we run a safety screen powered by a lightweight Gemma model behind a safety gate. This gives Iris a “screen-then-act” pipeline: $$ inspect \rightarrow classify\ risk \rightarrow redact/block/allow $$
World ID (Gatekeeper / Human-in-the-loop for high-stakes steps) For high-stakes actions (purchases, sensitive information, irreversible commands), Iris pauses and requires World ID verification. This makes execution explicit and user-approved, reducing accidental triggers and unsafe automation.
Solana (Audit Trail) After verified actions, Iris writes an audit event with an action hash so decisions and outcomes are traceable. $$ action \rightarrow hash \rightarrow audit\ log $$
Cognition (Engineering Specialist via MCP) We integrated an MCP engineering specialist server to support a self-verifying coding loop: repo-aware inspection + local verification (compile/tests) before reporting results. This turns coding from “I think this works” into “I verified this locally.”
- Electron + React UI: a voice-first overlay interface designed to stay out of the way while keeping transcript + status visible
- FastAPI backend: system actions (screen/AX capture, narration, safety gates, tool bridge, automation endpoints)
- Browser/OS automation layer: connects Iris’s intent to concrete actions (web navigation + desktop app control)
Challenges we ran into
- Supervisor/worker reliability: routing errors happen if “who does what” isn’t strictly defined. We stabilized delegation by tightening tool contracts and making routing explicit instead of implicit.
- Context handoff: multi-agent systems fail when state gets dropped between steps. We learned to preserve intent + constraints as structured state, not just chat text.
- Real-world brittleness: web UIs change, permissions vary, and automation can fail. We designed Iris to be transparent about progress and to handle failures gracefully instead of silently stalling.
Accomplishments that we're proud of
- Multi-turn refinement that feels human: Iris handles natural corrections mid-task without restarting the workflow.
- Real “Head + Hands” execution: Iris is not just a narrator—she can trigger browser and OS actions and report results back into the conversation loop.
- Trust-first architecture: safety screening before actions, World ID gating for high-stakes steps, and auditable logs after execution.
- Accessibility-first interaction model: optimized for clarity, minimal cognitive load, and non-linear understanding of what’s on screen.
What we learned
Humans don’t speak in perfect commands. They change their mind, forget constraints, and interrupt. The best agent isn’t one that follows a rigid script—it’s one that maintains state, asks for the right clarification at the right time, and stays transparent about what it’s doing. We also learned that accessibility isn’t a feature: it’s an engineering standard that forces better UX, safer defaults, and clearer system design.
What's next for Iris
- Deeper accessibility research: partner directly with visually impaired users to validate real workflows and refine interaction patterns.
- Richer “perception” layer: improve non-linear screen understanding so Iris can summarize complex pages reliably.
- More desktop capabilities: expand app control beyond browsing (mail, docs, developer tooling, system settings).
- Stronger safety + personalization: user-specific constraints (allergens, preferences, risk thresholds) enforced by default.
- New modalities: explore “text-to-braille” style outputs to complement voice-first computing.
Built With
- agentverse
- elevenlabs
- fastapi
- mongodb
- python
- typescript
- uagents

Log in or sign up for Devpost to join the conversation.