-
-
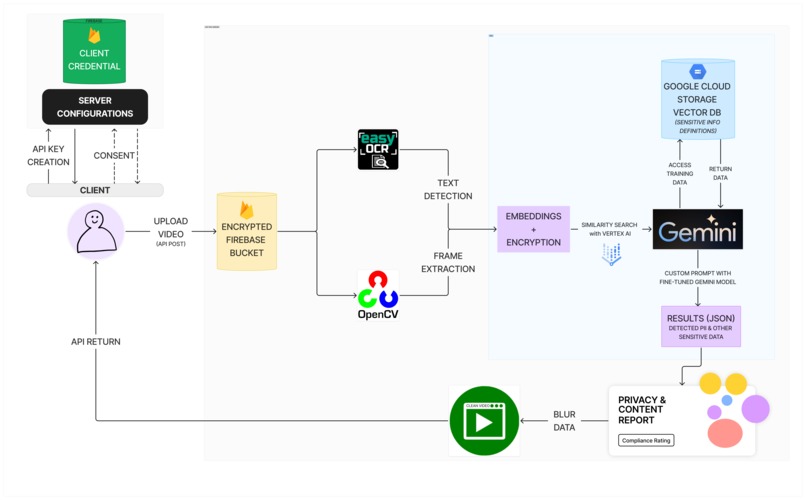
Technical Architecture

Inspiration
Millions of users share videos, short-form content, and create stories on social media every day. Facebook alone has approximately 2.1+ billion daily active users all over the world. However, the current system struggles to detect and remove sensitive information in real time. Videos containing passwords and personally identifiable information (so-called PII) like addresses and credit card details are frequently taken down only after user reports, which can be too late since the data has already been leaked. As human moderation becomes increasingly challenging, computerized supervision is essential. Iris is a fully autonomous system that enables companies and users to blur out sensitive information seamlessly. We wanted to create a special censorship engine that would sanitize a video so that we wouldn't have to do it ourselves, solving the problem at its source.
What it Does
- Detailed Quality Check: Utilizes Gen AI to scan through detected words and audio clips, summarizing the content identified.
- OCR, Gemini 1.5 Pro, and Vertex AI API Integration: Employs Easy OCR models for text detection in videos, Vertex AI for Vetor Search (RAG), Gemini 1,5 Pro for sensitive info detection from a semantic perspective
- Video Censorship: Automatically blurs regions of interest containing sensitive information.
Getting Started
- Clone the repository: git clone [repository-url]
- Install the required packages: pip install -r requirements.txt
- Create environment touch .env echo GEMINI_API_KEY=[Your API Key] > .env
Running the Backend
- Navigate to the backend directory: cd backend
- Install the necessary dependencies: npm install
- Start the backend server: node app.js The client API will now be listening for requests.
Running the Frontend
Navigate to the frontend directory: cd frontend
Install the necessary dependencies: npm install
Start the frontend application: npm start # or npm run dev for development mode This will open the webpage for the user to upload videos.
Key Components of the Prompt:
Input Description:
The AI is informed that the video may contain PII in forms that are not immediately obvious. This includes cases where text might be mirrored, hidden, or subtly embedded in the video. The AI needs to detect and account for these challenges during its analysis.
Output Requirements:
- Location Information: The AI must identify any data that reveals someone's physical location, such as addresses or landmarks. Special attention is given to details that may be obscured or mirrored. The AI will also provide specific examples or frames where this information is detected and assess the risk level.
- ID Information: The AI is tasked with detecting identification documents or numbers, like passports or social security numbers, even if they are partially hidden or difficult to see. The AI will describe the type of ID detected and evaluate the risk of misuse.
- Medical Information: The AI will look for any medical-related information, such as prescriptions or medical devices, and provide context around the challenges in visibility. The risk of exposure is then assessed.
- Financial Information: The AI is responsible for identifying financial data, such as credit card numbers or bank statements, even if they are hard to see or mirrored. The prompt ensures that the AI describes the financial information detected and assesses its sensitivity.
- Additional PII Categories: This catch-all category ensures that the AI identifies any other types of PII that don't fall into the previous categories. This could include emails, phone numbers, or personal photos. The AI must provide examples and assess the risk of exposure.
Task Description:
The AI is required to perform a thorough examination of the video to identify all relevant PII, considering various challenges like occluded or mirrored content. The AI should not only detect the PII but also provide a detailed explanation of its findings, specific examples, and a qualitative risk assessment (High, Medium, Low) for each category of PII detected.
Why This Matters:
In scenarios where PII is hidden or presented subtly, it is crucial that the AI model goes beyond simple detection. The prompt ensures that the AI considers various complexities and provides detailed, actionable insights that can be used to mitigate the risks associated with exposing sensitive information in videos.
Accomplishments that we're proud of
This project was built upon our original submission for Tiktok Tech Jam. While we didn't win that hackathon, Cheryl and I really believed in the potential of the project and decided to continue working on it. The original idea utilized Streamlit to ship the product quickly. For this hackathon, we revamped the whole user interface with React and changed our whole approach for the backend.
Challenges we ran into & What's next for Iris
Due to its nature being a Computer Vision project, it's extremely costly to test run everything. Latency was around 2 mins for a video under 1 minute when we tested it on our Lambda GPU servers, 3 mins with GCP, and 10 mins without a GPU server. It costed around $200 when we conducted test runs for 10 videos with Lambda alone.
We also played around with OpenAI GPT and Google Gemini, and we had to pay for the API credits ourselves.
Due to limited budget, right now, Iris also extracts frames and texts within video frames using EasyOCR. In the future, we hope to develop a custom neural network designed to analyze videos. We plan to build a model that will analyze the video as a temporal unit rather than the frame-by-frame approach we have now. We also want to have continuous feedback rather than our current single feedback loop.






Log in or sign up for Devpost to join the conversation.