

Inspiration
video editing is gatekept. premiere and final cut look terrifying the second you open them. masking, keyframing, color grading, track mattes. the ideas people want to express are simple ("make the car red", "get rid of the guy in the background") but the tools demand years of muscle memory before those ideas land on screen.
teachers, nonprofits, kids with phones, filmmakers with motor disabilities who can't chain twelve clicks to mask a moving subject. they all have the idea. none have six months to learn premiere.
generative ai changes the input surface. point at the thing, say what's different. a sentence does what a timeline used to. that's iris.
accessibility isn't a bonus feature here, it's the whole thesis. one sentence replaces twelve clicks for the people who literally can't do twelve clicks.
How we built it
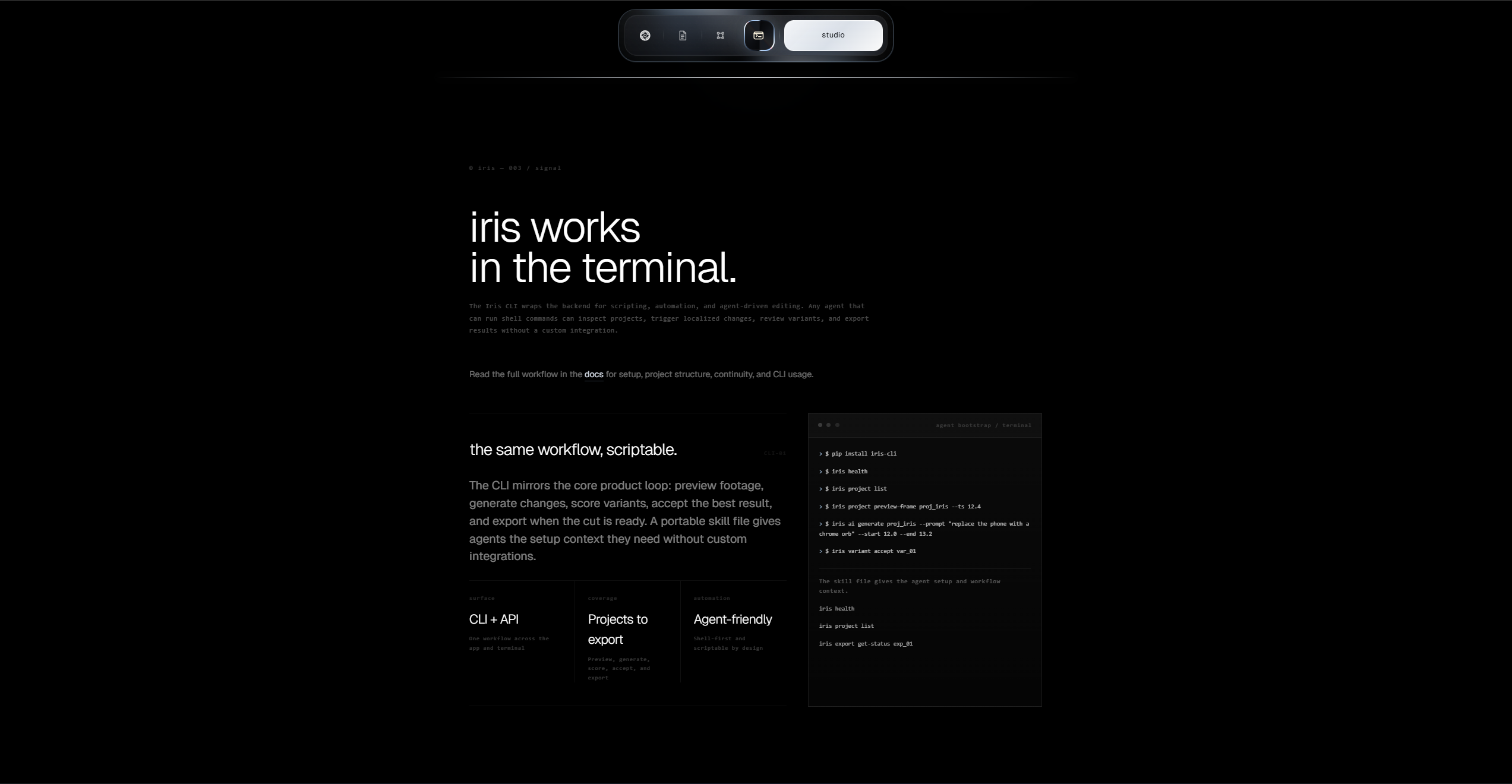
iris is three systems: a React editor that feels like premiere but thinks like an agent, a FastAPI backend that orchestrates multiple AI models into one coherent pipeline, and a CLI that lets any AI agent edit videos autonomously.
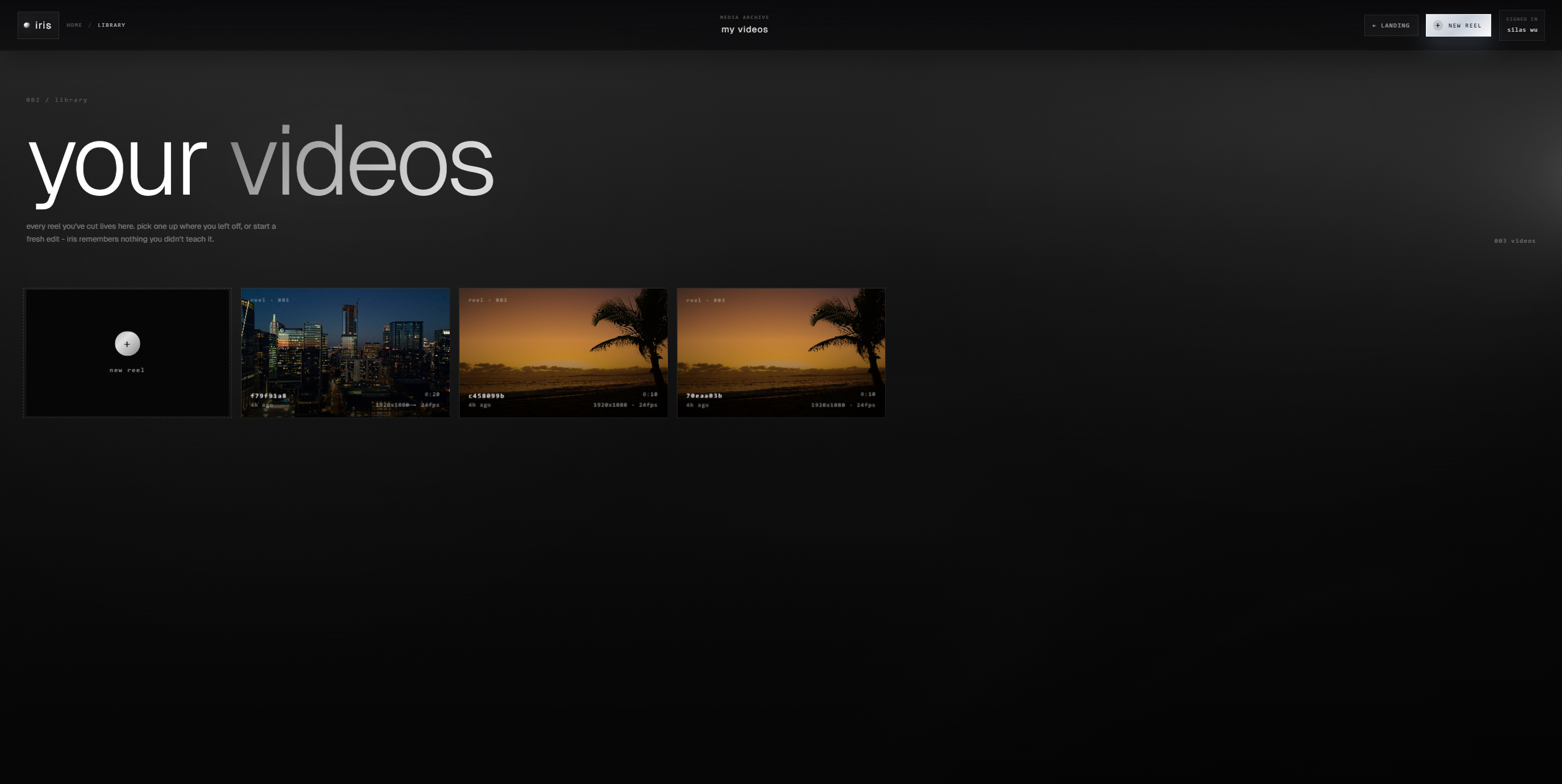
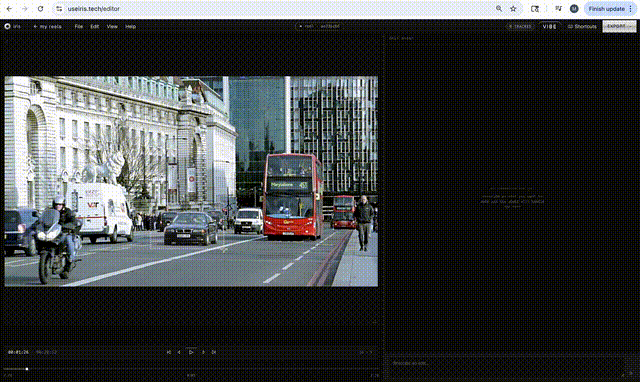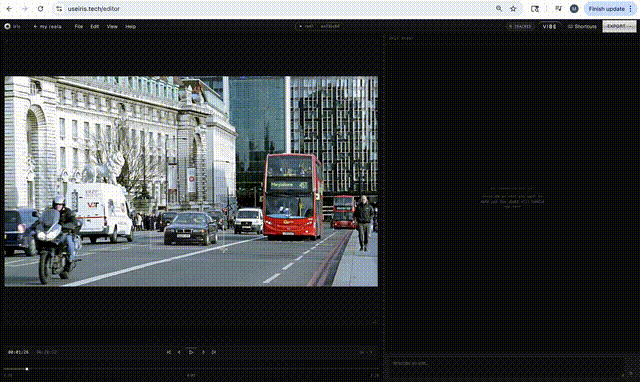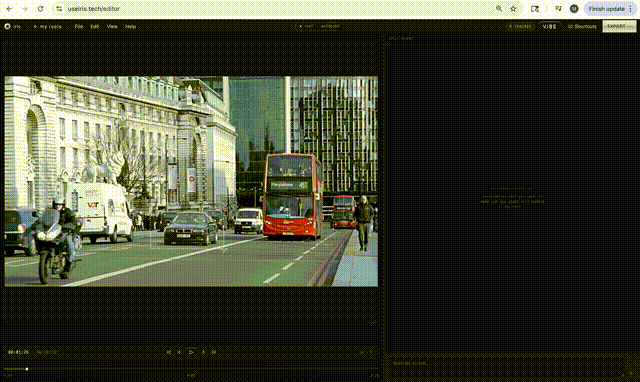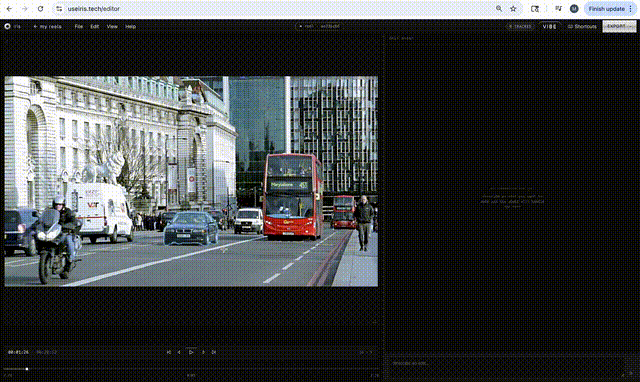
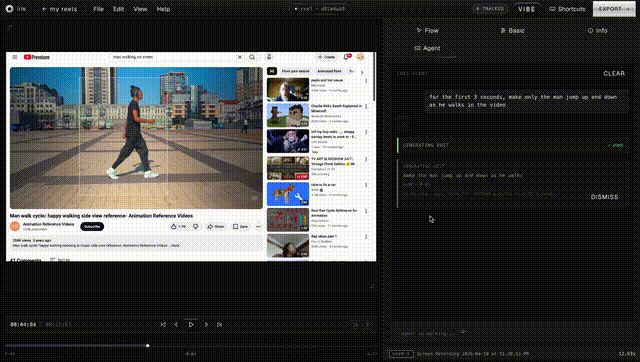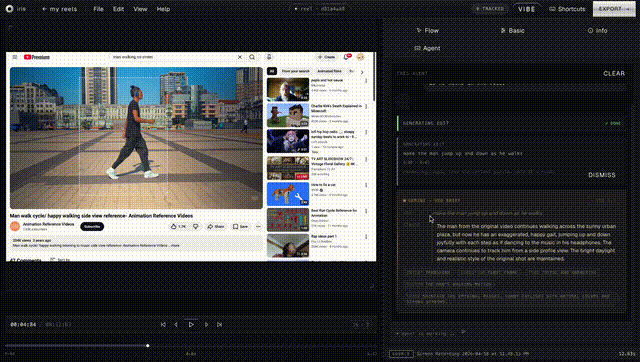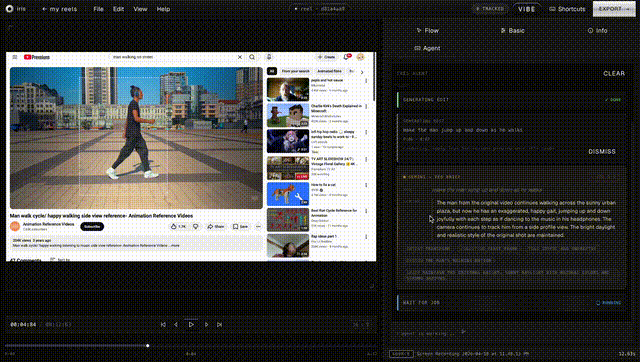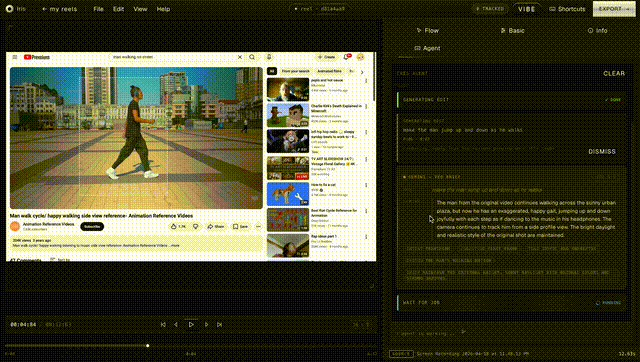
the editor. React 19 + TypeScript + Vite. two modes, because "AI editor" and "pro editor" are different jobs. vibe mode is a 60/40 split: video on the left, agent chat on the right. you describe what you want and the agent handles analysis, region identification, variant generation, and side by side comparison. pro mode is a full NLE with timeline, inspector, library shelf, and continuity dashboard for when you want granular control. same tool, different cognitive loads.
the backend. FastAPI with every endpoint the editing lifecycle needs. Gemini 2.5 Flash is the brain of the entire pipeline. every decision about what the user means, what region to segment, what to generate, and how to score the result starts with a Gemini call. SAM2 handles pixel perfect masks. Veo 3.1 generates video. all of them are downstream of a Gemini decision. the system produces multiple variants and scores them on visual coherence, prompt adherence, and temporal consistency. when you accept a variant, entity tracking finds every other appearance of that subject across the video and propagates the edit. change a jacket color at second 3, it changes everywhere the person appears.
the agent layer. Gemini function calling with 20 tools streamed over SSE. the agent can preview frames, split and trim the timeline, color grade segments, score quality, remix variants, and batch generate in parallel. conversations persist in Postgres so you can pick up where you left off. we also shipped a CLI and a portable SKILL.md file so any AI agent (Claude Code, Codex, OpenClaw) can read the skill and start editing videos through bash.
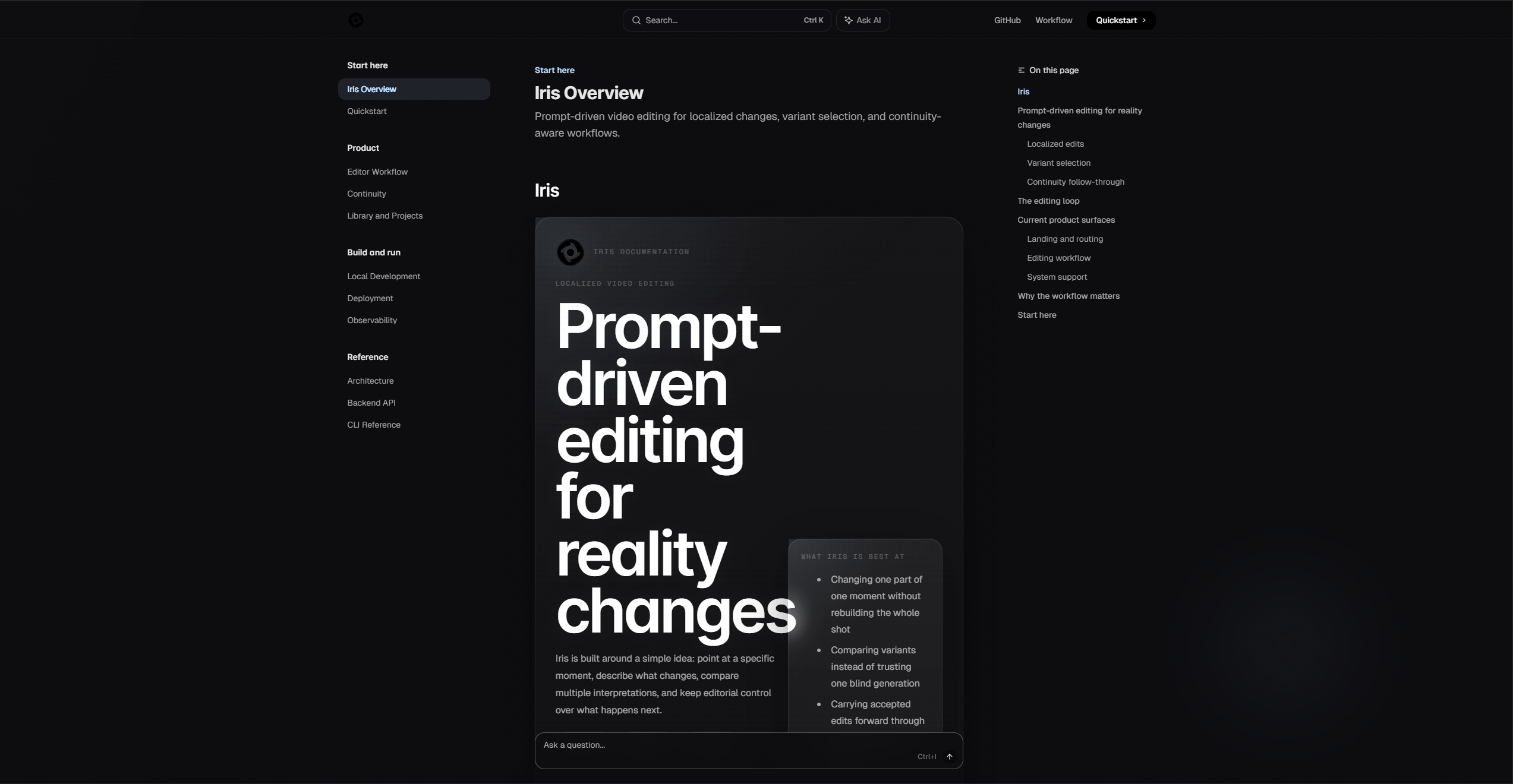
infrastructure is all Vultr. Docker Compose running frontend, backend, and Postgres on a VPS. Vultr Object Storage for media. Vultr Cloud GPU worker for SAM2 segmentation. one cloud, no glue code between providers. GitHub Actions runs typecheck and 104 tests on every push, then auto deploys. we even built an auto docs agent that reads code diffs and updates our Mintlify docs at docs.useiris.tech.
Challenges we ran into
temporal consistency is the hardest problem in AI video editing. when you regenerate a 3 second clip, it has to match the lighting, color, and motion of the frames before and after. early versions had visible seams where generated footage met original footage. color jumps, jitter, artifacts at the boundaries. we built a multi dimensional scoring system (visual coherence, temporal consistency, edge quality, flicker detection) and a remix API so the agent can iteratively refine variants until the seams disappear.
the agent and the timeline were two separate worlds. the agent could talk and call tools, but the video player didn't update when edits landed. we built a bridge (useAgentEdlBridge) that watches for completed tool calls and rehydrates the timeline from the backend, so when the agent accepts a variant, the preview updates live.
Veo rate limits. video generation is expensive and heavily rate limited. we couldn't just fire unlimited requests during dev. we built a stub mode (USE_AI_STUBS=true) that returns deterministic placeholder responses so the full UI workflow could be built and tested without burning quota. real and stub paths share the same interface, so switching is one env var.
making the agent actually useful. early versions were a fancy text box. the agent could talk but couldn't see what the user was looking at. we piped the current playhead position, bounding box, and identified entity into every message as context, so the agent knows "the user is at second 3.5, looking at a red sedan at coordinates (0.2, 0.3, 0.4, 0.3)."
Accomplishments that we're proud of
the editing loop works for people who've never touched a timeline. upload a video, say "make the car blue," a few seconds later you're comparing three AI generated versions and clicking the one you like. that loop removes every skill requirement that kept video editing locked behind professional software. the people we built this for (teachers, kids, anyone who can't navigate a twelve click workflow) can actually use it on day one.
continuity propagation. change a subject in one shot and iris finds every other appearance across the video and applies the same edit. this is the thing that takes hours in premiere (manual masking and tracking on every clip) and takes one click in iris.
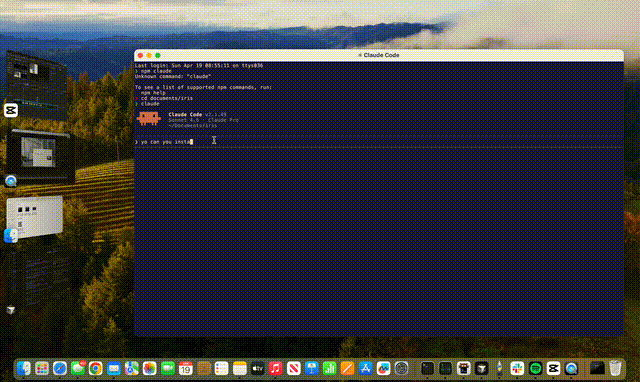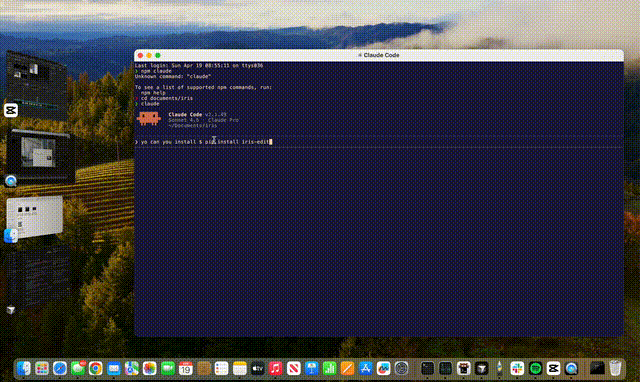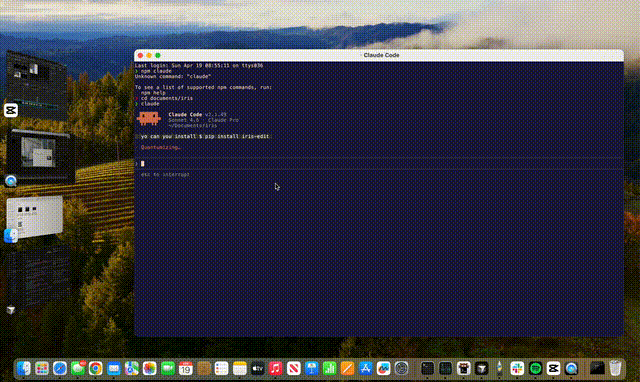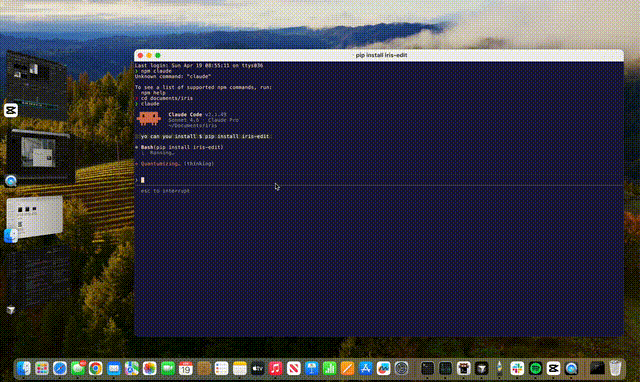
fully autonomous video editing. our SKILL.md teaches any AI agent how to drive the iris CLI. we tested it with Claude Code: tell it "make this video look cinematic" and it runs iris analyze, reads the scene breakdown, identifies edit opportunities, runs iris generate with tailored prompts, scores the results, and accepts the best variants. no human in the loop.
What we learned
orchestration is the product. Gemini, Veo, SAM2, ElevenLabs are all incredible individually, but none of them is the thing. the thing is the pipeline that takes a human sentence and coordinates vision, segmentation, generation, scoring, and timeline surgery into one smooth edit. and the pipeline is only as strong as the tools you give the agent. our first version had 5 tools and the agent could barely do anything. expanding to 20 tools (preview, split, trim, grade, score, remix, batch, snapshot, revert) turned it from "generate and pray" into something that iterates like a human editor.
the last mile of AI products is UX. we could've stopped at "API that generates video variants" and called it done. the gap between a demo and a product is: can the user preview before committing, undo when it's wrong, compare options side by side, color grade after generation. every one of those required real editing infrastructure on top of the AI.
What's next for iris
voice first editing. Deepgram transcription plus ElevenLabs responses so you can have a full spoken conversation with the agent while scrubbing footage. "go back to that shot of the car... yeah, make it red... actually a little darker, more burgundy."
longer form editing. right now segments cap at 2 to 5 seconds for generation quality. as models improve we want full scene length edits and multi shot narrative restructuring.
Built With
- docker
- elevenlabs-api
- fastapi
- ffmpeg
- framer-motion
- github-actions
- google-gemini-api
- google-veo-api
- gsap
- httpx
- meta-sam2
- mintlify
- postgresql
- python
- react
- sqlalchemy
- supabase
- tailwind-css
- three.js
- typer
- typescript
- vite
- vultr-cloud
- vultr-object-storage




Log in or sign up for Devpost to join the conversation.