-
-

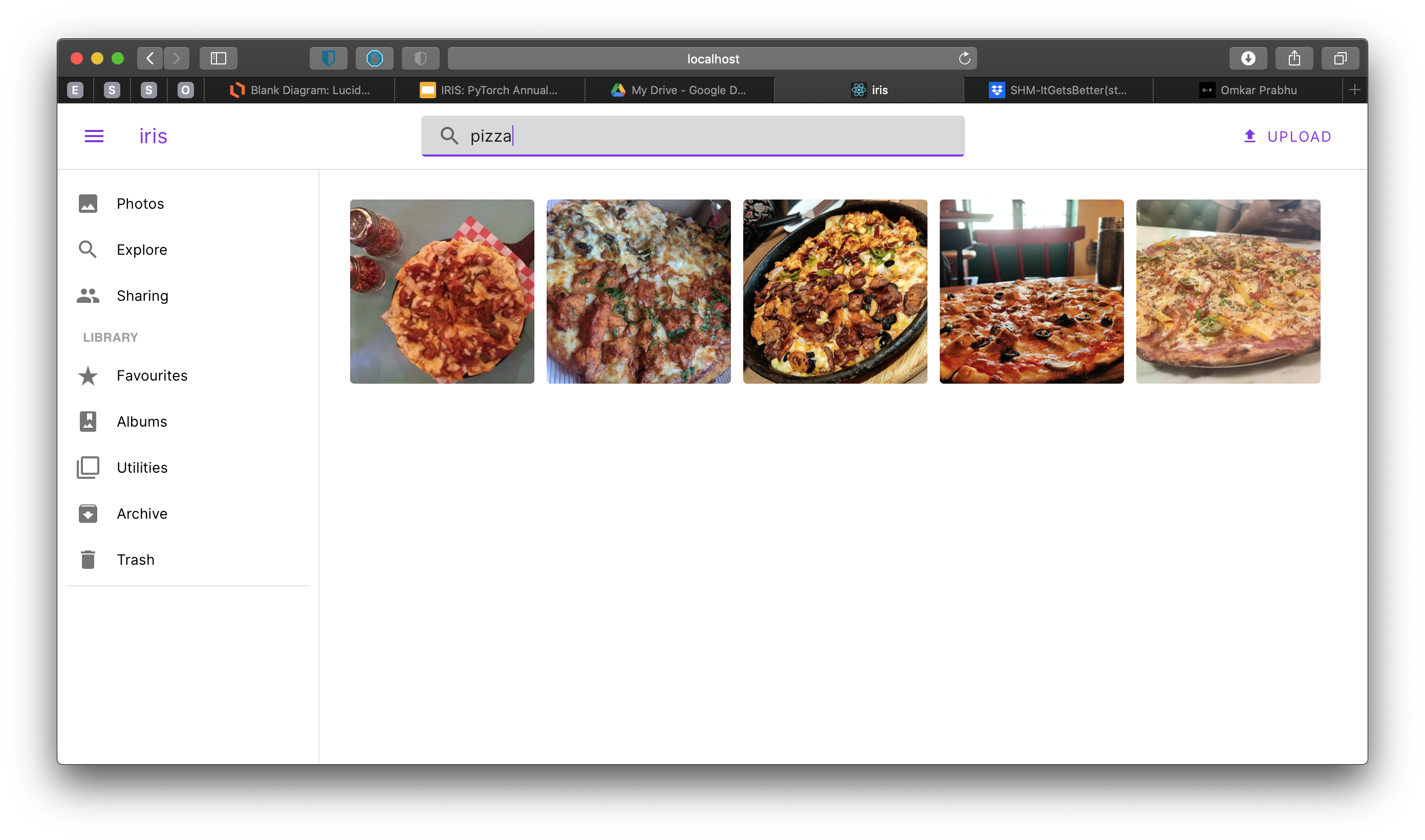
Intelligently Organized and Smart Search
-

Explore Powered by PyTorch

Inspiration
Since the release of TorchServe we were intimidated to experiment with it and try to push its limits. Recently, Google Photos ended its free storage and it kind of inspired us to build an open source version of it. We wanted to build a platform which people can host themselves and powered by PyTorch ecosystem. With some magic and endless optimizations, we are proud to release iris!
What it does
iris is an open source photos platform which is more of an alternative of Google Photos. With the scope of development being during the Hackathon duration, we tried implementing some of the core features like: Listing photos, Detecting Categories, Detecting and Classifying Faces from Photos, Detecting and Clustering by Location and Things in Photos. Currently, when you upload any image - iris will smartly extract all fields asynchronously and categorise your photo for smart search and listing.
| Search | Explore |
|---|---|
 |
 |
How we built it

All the services are containerised and are available as Docker images.
Worker:
Worker is the HEART of the iris. Its a Python microservice which contains 4 components:
- Metadata: It extracts all the information about the photo for processing like Height, Width, Camera details, Location co-ordinates, etc.
- People: It calls TorchServe FaceNet API to get detected faces from the photos and then performs clustering to group new faces with existing faces in all photos.
- Things: It calls TorchServe API to get categories and classes of images classified by image classification model ResNet152 and object detection model MaskRCNN. Based on the classes iris's 26 categories for a photo are decided.
- Places: It does reverse geo-coding from the co-ordinates and works on identifying the location name for a photo.
ML:
ML is the BRAIN of iris. Its a TorchServe microservice which contains 3 models with customised handlers.
- FaceNet: We made use of pretrained model from timesler/facenet-pytorch for face detection and Inception pretrained on vggface for getting the image embeddings. It returns in response:
{ "data": "<byte data of the face detected>", "embedding": "<image embedding data>" } - ResNet152: We are using torchvision/resnet152 for image classification based on the ImageNet categories.
- MaskRCNN: We are using torchvision/maskrcnn for object detection based on the COCO categories.
Both the above models return response:
{ "content_categories": [<>], "classes": [<>] }Currently, ML service returns following 26 Categories for an image:
'ANIMALS', 'FOOD', 'GARDENS', 'SPORT', 'PEOPLE', 'TRAVEL', 'WEDDINGS', 'LANDSCAPES', 'SCREENSHOTS', 'WHITEBOARDS', 'BIRTHDAYS', 'NIGHT', 'FLOWERS', 'SELFIES', 'CITYSCAPES', 'ARTS', 'CRAFTS', 'HOLIDAYS', 'FASHION', 'LANDMARKS', 'PERFORMANCES', 'RECEIPTS', 'DOCUMENTS', 'HOUSES', 'PETS', 'UTILITY',
Frontend:
We wanted to build a Single Page Application which can be smooth in loading the large list of images, uploading and working with virtualisation to give performance. Hence, we choose React.js and built the frontend using it. We choose Material React Framework for designing the website with its components.
API:
We had a good experience working with Facebook's GraphQL in past and knew its strength. We implemented a GraphQL API Server in Golang with its connectivity to MongoDB for database storage. API Server also connects to SeaweedFS which is a CDN Server for our images and RabbitMQ for communication with other services via message broker.
GraphQL API Server handles the File upload, Search, Listing all photos at Home as well as Explore Sections.
Challenges we ran into
The hackathon has been a unique journey personally for us, given our full time jobs.
Apart from that, these are some specific challenges we ran into:
- Handling asynchronous and continuous stream of the file uploads was trickier as well. As we wanted it to be as real time as possible we did not go with CRON jobs for processing the images. Instead it was a challenging problem of micro services to solve. Thats why we brought in the RabbitMQ as message broker and pushed all the information about the uploaded files to the worker. This made it asynchronous but yet ensured its near real time processing for all the photos.
- Worker components were the most fun and challenging out of all to work on. Given the complexity of the processing - it was very hard to perform reverse geo-coding at first - then we solved it using: Open Street Maps Nominatim. Secondly, things detection was the toughest as it can lead to incorrect results, we needed to set up filters for identifying classes and categories as well. At last, for the people detection and recognition, we just spent last few weeks on identifying the clustering for the faces in the photos. We finally decided to choose Spotify Annoy and experimented with lot of distances for the clustering. However, not being 100% accurate, it still works like a charm.
- Building and spinning a GraphQL server which can host images uploaded by the user was one of the first in line while developing this project. We tried and experimented with several techniques to store the uploaded file in disk, but it proved to be incorrect. Thats we ended up using SeaweedFS which a popular open source CDN server. Once it was up, we could upload as many photos as we want without worrying about the disk space for the API Server.
Accomplishments that we're proud of
Team
We were chasing a fun engineering & machine learning problem and being able to solve it by delivering a working solution is a moment of pride for us. We have learnt so much in last few months, which we couldn't even in a year. While working on the project, we were so involved that we used to get so many feature ideas and we had to spend time in prioritising them. While during this pandemic, without the great communication, prioritization, and scheduling we couldn't have achieved this and we are super proud of this!
Omkar
Having successfully carved all of the core components of the project in a relatively short period of time, this has to be my most memorable and proud moment of 2021! I am super proud of designing this architecture which competes with several existing open source solutions. Having delivered the Worker & ML which does the magic by solving several ML and Engineering problems, those 2 are definitely my favourite pieces of the software I have developed in recent times.
Akshay
Building the front-end in such a short period of time, which was supported by great back-end services. It was a great experience working on the iris front-end. I got to learn many things along the way like page optimization, handling file uploads, etc. I am really proud of what we have accomplished, this is one of the best projects I've worked on in 2021.
What we learned
Omkar learned:
- PyTorch Model Deployment with TorchServe
- Customized models and handlers
- Container scaling for TorchServe and metrics
- Python Multithreading for building microservices
Akshay learned:
- Uploading files with GraphQL
- Optimizing page to load large list of images
- Working with containerized environment
What's next for iris
- We are planning to continue this project and ship out of scope hackathon features like Albums, Sharing, Image Filters, Editing image metadata.
- We will be opening up for funding and financial backing from VCs to continue this project and support those who want to use it.







Log in or sign up for Devpost to join the conversation.