-
-
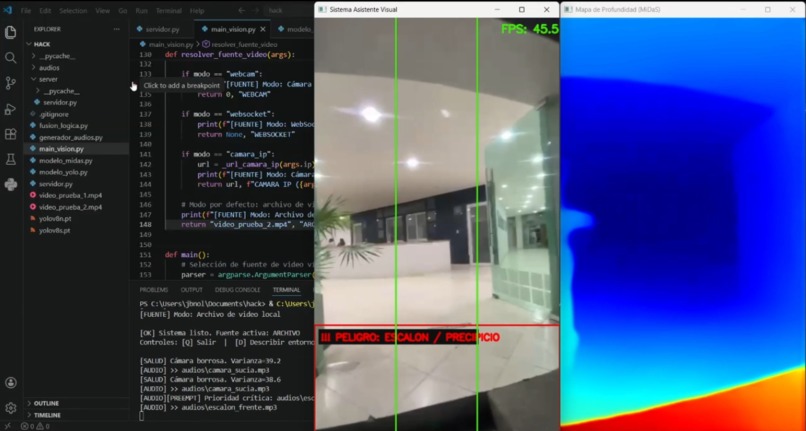
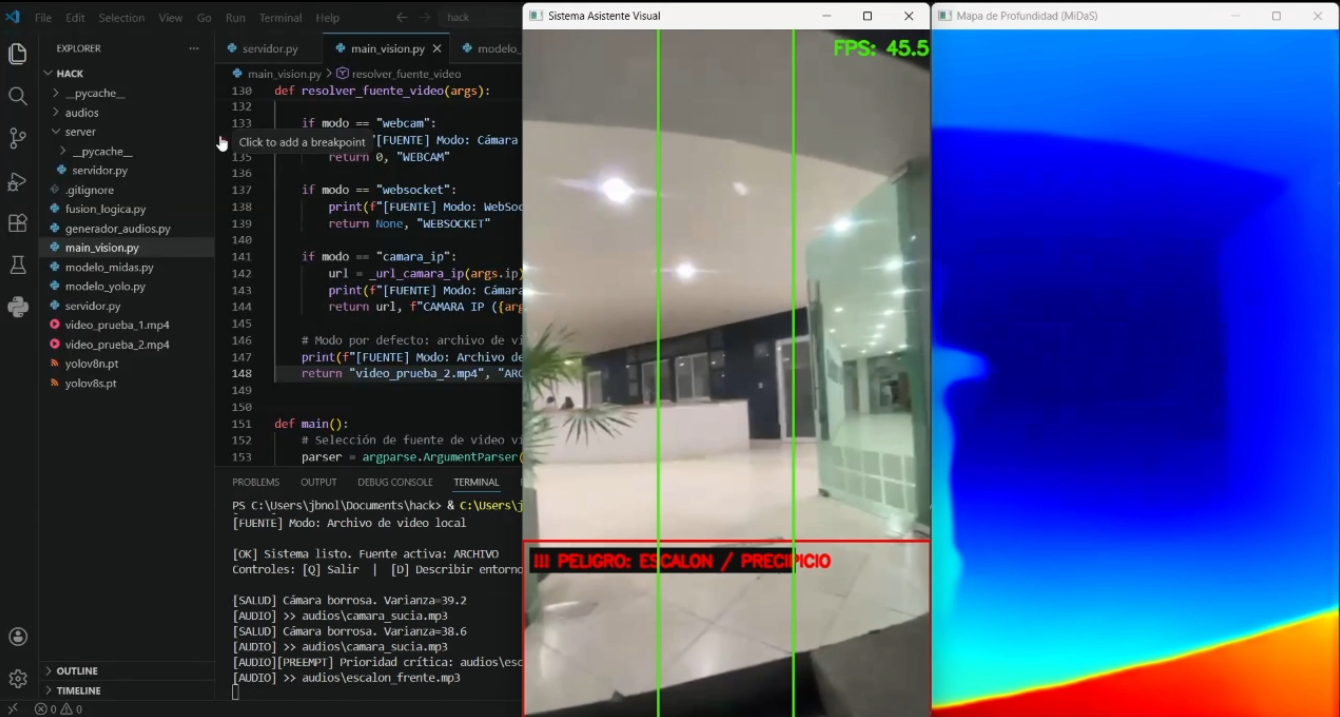
Test_desniveles
-
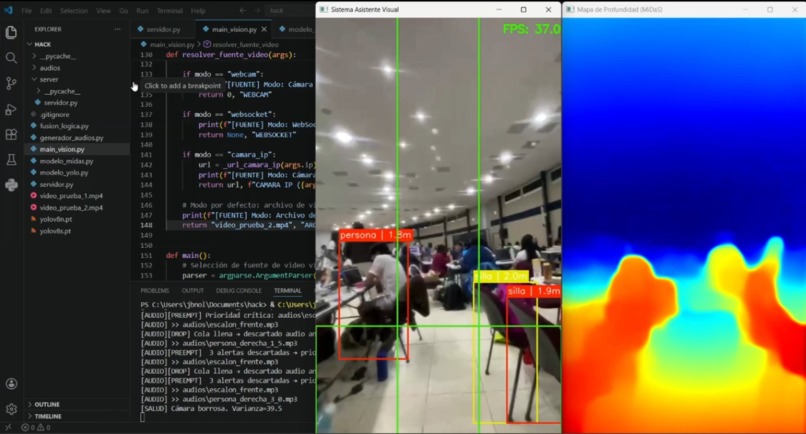
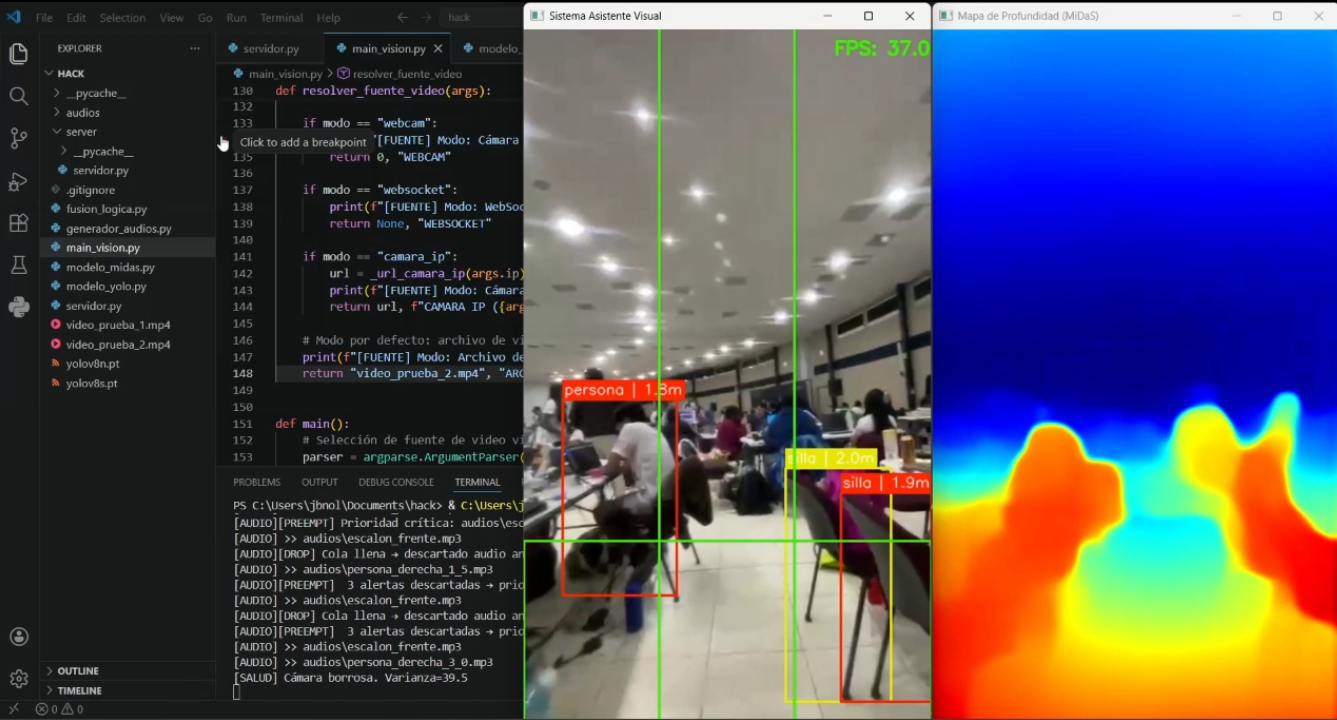
test_pasillos
Inspiration
En México, más de 11.01 millones de personas viven con alguna discapacidad visual. Las soluciones de navegación asistida que existen — bastón blanco, perro guía, apps de GPS — funcionan razonablemente bien en exteriores, pero fallan en espacios interiores: un lobby de hotel, un pasillo de universidad, una sala de espera en un aeropuerto. En interiores no hay señal GPS, los obstáculos son dinámicos (personas moviéndose, sillas fuera de lugar, puertas entreabiertas) y los desniveles como escalones o escaleras son invisibles para un sensor ultrasónico de bastón convencional.
Las soluciones tecnológicas existentes se dividen en dos extremos: apps de descripción de escena como Seeing AI o Be My Eyes, que requieren internet y son reactivas — el usuario pregunta, el sistema responde — y sistemas de investigación que demandan infraestructura instalada o hardware especializado como sensores LiDAR o cámaras RGB-D. En el medio hay un espacio vacío: alertas de navegación proactivas, en tiempo real, completamente offline, sobre hardware que el usuario ya tiene. Ese es el espacio que ocupa IRIS.
Desde el inicio tomamos una decisión de diseño deliberada: IRIS está optimizado para espacios interiores controlados — hoteles, aeropuertos, museos, edificios corporativos. Esta restricción no es una limitación técnica, es una ventaja de producto. En un recinto cerrado, el operador del edificio puede instalar un servidor local dedicado, eliminar la laptop del stack por completo, garantizar una red WiFi privada estable y, en el futuro, pre-cargar un mapa del espacio para alertas contextuales específicas ("escaleras a 10 metros", "elevador a tu derecha"). El resultado es un sistema con latencia mínima, disponibilidad total offline y sin costo de hardware por usuario.
Nos preguntamos: ¿se puede construir un sistema de asistencia visual en tiempo real usando únicamente hardware que el usuario ya tiene — un teléfono y unos audífonos — sin depender de infraestructura especializada ni conexión a internet?
What it does
IRIS convierte un teléfono montado en el pecho del usuario en un sistema de detección de obstáculos con retroalimentación auditiva en español. El usuario camina normalmente; el teléfono transmite video en tiempo real y los audífonos le dicen qué hay a su alrededor: "¡Cuidado! Persona al frente a 0.5 metros", "Silla a tu izquierda a 1.5 metros", "Escalón al frente".
El sistema detecta 17 clases de obstáculos relevantes para navegación peatonal — personas, sillas, mesas, puertas, bicicletas, mochilas, maletas, entre otros — y estima su distancia y dirección (izquierda, frente, derecha). También detecta desniveles como escaleras o precipicios, y paredes cercanas que bloquean el paso.
Todo opera completamente offline: la laptop actúa como hotspot WiFi, el teléfono se conecta directamente a ella. No hay llamadas a API externas en ningún momento de la ejecución.
How we built it
La arquitectura tiene cuatro etapas conectadas en pipeline:
1. Captura y transmisión. Una app en el teléfono captura frames JPEG y los transmite
por WebSocket al servidor en la laptop (puerto 8081). El servidor decodifica cada frame
con OpenCV y lo deposita en una cola maxsize=1 con política de descarte: si la cola
está llena, se elimina el frame más antiguo para garantizar que siempre se procese el
más reciente.
2. Pipeline dual de visión por computadora. Dos modelos corren en paralelo sobre la misma GPU (NVIDIA RTX 3050, CUDA FP16):
- YOLOv8s clasifica y localiza obstáculos con bounding boxes. Se ejecuta en el hilo principal.
- MiDaS_small estima un mapa de profundidad monocular completo del frame. Corre en
un hilo de fondo (
MidasWorker) con su propia colamaxsize=1, de modo que la inferencia de MiDaS — más lenta que YOLO — nunca bloquea el loop principal.
Ambos modelos usan precisión FP16 en CUDA, reduciendo el consumo de VRAM a la mitad y acelerando la inferencia.
3. Fusión espacial. Para cada obstáculo detectado por YOLO, extraemos la región correspondiente del mapa de profundidad de MiDaS (la mediana del ROI del bounding box) y estimamos la distancia métrica con una heurística de constante focal calibrada:
$$d = \frac{K_{\text{focal}}}{\tilde{z}_{\text{median}} + \epsilon}$$
donde z_median es la profundidad normalizada (0–255) y K_focal es una constante calibrada empíricamente a 1 metro de distancia real.
El mapa de profundidad se estabiliza con suavizado temporal EMA (α = 0.6) y un Gaussian Blur espacial (5×5) para reducir el jitter causado por la renormalización
min-max frame a frame.
La detección de escaleras/desniveles analiza el 30% inferior del mapa de profundidad: si σ > 60 o la caída relativa entre la media superior e inferior del ROI excede 20, se emite alerta de peligro. Para suprimir falsos positivos causados por la unión visual pared-suelo, la detección de pared se ejecuta antes que la de escaleras: si hay pared al frente, se inhibe la alerta de escalón.
4. Sistema de audio. Más de 360 archivos MP3 fueron pre-generados antes del
hackathon con ElevenLabs (voz: Cristina Campos, modelo eleven_multilingual_v2,
acento mexicano). La nomenclatura sigue el patrón {clase}_{posición}_{distancia}.mp3
— por ejemplo, persona_frente_0_5.mp3. Esto elimina completamente la latencia de TTS
en runtime: reproducir un MP3 local no tiene latencia de red. Las alertas se gestionan
con un AudioWorker asíncrono que usa cola de prioridad con cooldowns diferenciados
(4s general, 2s para alertas críticas). Las alertas críticas (distancia <1 m o escalón)
vacían e interrumpen la cola actual.
Challenges we ran into
MiDaS bloqueando el loop principal. En las primeras pruebas, la inferencia de MiDaS
(~80 ms por frame) se ejecutaba de forma síncrona en el loop principal. Esto reducía
los FPS del sistema a menos de la mitad. La solución fue mover MiDaS a un hilo de fondo
(MidasWorker) con una cola de entrada maxsize=1 que siempre descarta frames viejos.
El loop principal envía el frame y lee el último resultado disponible sin bloquear. El
resultado es que YOLO corre a su velocidad nativa mientras MiDaS se actualiza en
background.
Falsos positivos de escaleras en uniones pared-suelo. El borde inferior de una pared cercana genera un gradiente brusco de profundidad en el ROI inferior que dispara exactamente las mismas métricas que un escalón real (σ > 60, caída relativa alta). La solución fue ejecutar la detección de pared antes que la de escaleras: si se detecta una superficie plana con alta profundidad media y baja desviación estándar en la zona frontal (indicando pared), se suprime la alerta de escalón.
Estabilidad WiFi en entorno de hackathon. Con decenas de equipos en la misma red, la transmisión WebSocket era inestable. Configuramos la laptop como hotspot WiFi directo (sin pasar por el router del evento), creando una red dedicada teléfono–laptop sin competencia de ancho de banda.
Accomplishments that we're proud of
- El pipeline completo corre en tiempo real con latencia punta a punta suficiente para navegación peatonal, sobre una GPU de consumo (RTX 3050, 4 GB VRAM).
- La arquitectura de threading no bloqueante permite que YOLO y MiDaS cooperen sin que el modelo más lento degrade al más rápido.
- El sistema de audio tiene latencia de reproducción despreciable gracias a la estrategia de pre-generación con ElevenLabs — cero llamadas de red en runtime.
- Integramos ElevenLabs como infraestructura de voz, generando 360+ frases con calidad profesional en español mexicano antes del evento.
- El demo funcional se construyó en aproximadamente 16 horas de código real, desde cero, por un equipo de cinco personas.
What we learned
La profundidad de MiDaS es relativa, no métrica. La salida normalizada (0–255) cambia de escala entre frames dependiendo de qué haya en la escena. Esto significa que la constante focal K_focal debe recalibrarse por entorno. Lo mitigamos con suavizado EMA temporal, pero la solución real requiere un sensor de profundidad calibrado o un modelo que produzca profundidad métrica absoluta.
Threading no bloqueante como patrón de diseño. Descubrimos que el cuello de botella
no era la velocidad bruta de los modelos sino cómo se secuenciaban. Mover MiDaS a un
worker con cola maxsize=1 y política de descarte fue la decisión arquitectónica más
impactante del proyecto — más que cualquier optimización de modelo.
Pre-generación vs. TTS en tiempo real. Evaluamos usar ElevenLabs en runtime, pero la latencia de API (~500 ms mínimo) era inaceptable para alertas de navegación. La pre-generación de 360+ archivos con nomenclatura determinista nos dio calidad de voz profesional con latencia de reproducción local. El tradeoff: no podemos generar frases dinámicas arbitrarias, solo combinaciones previstas de clase × posición × distancia.
Si pudiéramos volver atrás, habríamos invertido más tiempo en calibración cuantitativa de distancia con mediciones reales en lugar de depender de una sola constante focal ajustada a ojo.
What's next for IRIS
El siguiente paso es validar IRIS con usuarios reales con discapacidad visual — algo que no pudimos hacer durante el hackathon y que reconocemos como la brecha más importante del proyecto actual.
A nivel de producto, vemos IRIS como una solución B2B para operadores de espacios interiores: hoteles, aeropuertos, museos, oficinas corporativas que necesitan cumplir regulaciones de accesibilidad (CONADIS en México, ADA en Estados Unidos) sin instalar hardware especializado. La propuesta de valor es clara: desplegable sobre el teléfono que el usuario ya tiene, con un servidor local por recinto, completamente offline, sin costo de hardware por usuario.
En el roadmap técnico:
- Pruebas con usuarios con discapacidad visual en entornos controlados.
- Pre-carga de mapa del recinto para alertas contextuales por ubicación ("escaleras en 10 metros", "elevador a tu derecha").
- App móvil companion que integre captura y procesamiento en el mismo dispositivo, eliminando la laptop del stack.
- Migración a profundidad métrica (Depth Anything v2) para eliminar la dependencia de calibración manual.
- Validación regulatoria bajo estándares CONADIS y ADA para certificar el sistema como infraestructura de accesibilidad reconocida.




Log in or sign up for Devpost to join the conversation.