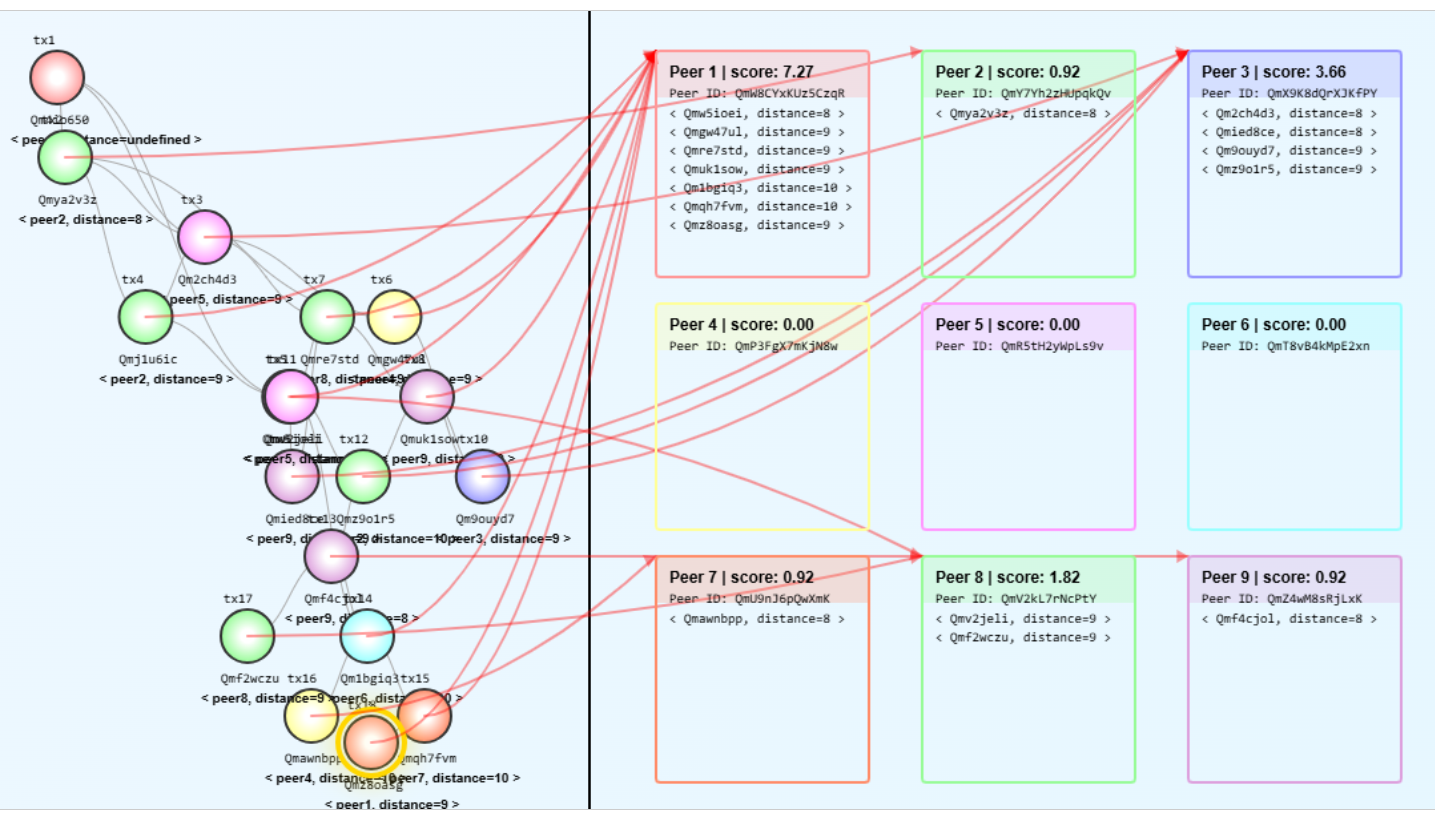
The goal of this is an edge focused MLOPS framework, that uses libp2p and IPFS (Interplanetary file system) for networking and networked file system, and allows peers in the network to share with each other what file hashes they have in their repository, what AI models they provides inference for, and what model and data metadata it has received from others. Files added to the IPFS daemon “bucket” are indexed with an embedding model, and a knowledge graph is generated about the data, which then can be queried by the language model.
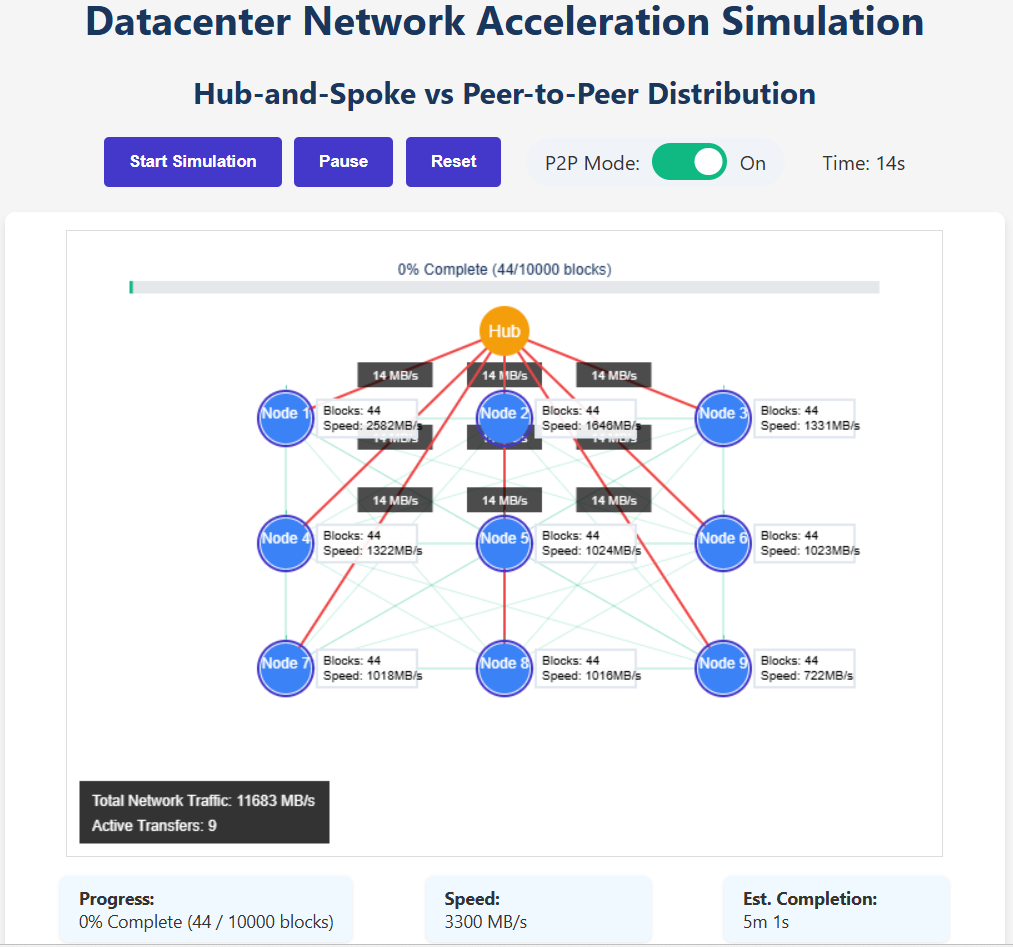
Peers can join multiple pubsub (publish/subscribe) queues, and when a request is made from a member of its peer group, batched inference can be used to keep the queue low, and meanwhile optimizing the compute efficiency of edge compute nodes, by both reducing the amount of network traffic needed to download models multiple times, but also by using the hardware resources more efficiently, and being able to share results from peer to peer reduces the network load in a “hub and spoke” network topology, when the peers are topologically closer neighbors than the data center.
We believe by pushing as much of the compute to the edge, we can achieve overall lower latency times compared to datacenter compute, if there are sufficient compute nodes running at the edge, which can be made more easily amenable once the webNN (web neural network) standards are approved. This will allow the browser itself to request machine learning compute from the operating system, and from inside of a web browser or electron app. To perform inference, a IPFS content id (CID) points to code and data that can be retrieved via IPFS, and then packaged into a wasm (web assembly) container, to then be executed either at the edge or by another trusted peer, we also have a three.js animated avatar that can provide an interface between the user and the language modeling tasks.
Built With
- filecoin
- ipfs
- libp2p
- nodjs
- python

Log in or sign up for Devpost to join the conversation.