-
Prototype of Soil nutrient monitoring system.
-

Block diagram of Soil fertility and crop friendliness detection and monitoring system using AI
-

Block diagram of suitable Crop Suggestion System
-

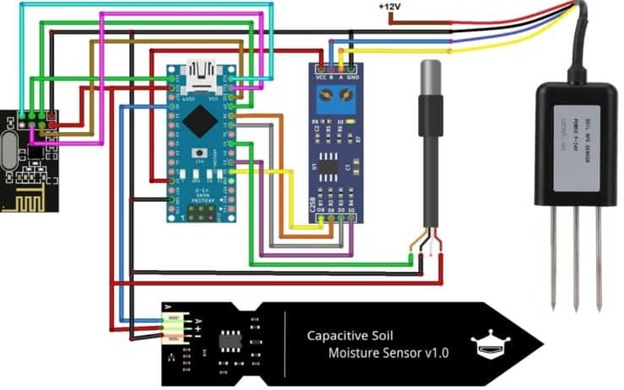
Prototype of IoT-Enabled Soil Nutrients Prediction, Crop Suggestion and Fertilizer Recommendation System using Machine Learning Approach




Soil is the base of agriculture. Soil provides nutrients that increase the growth of a crop. Some chemical and physical properties of soil, such as its moisture, temperature, soil nitrogen, phosphorus & potassium content heavily affect the yield of a crop. These properties can be sensed by the open-source hardware, and they can be used in the field.In this project, a soil Nutrient monitoring & analysis system is proposed in which the farmer will be able to monitor soil moisture, soil temperature, and soil nutrient content like Nitrogen, Phosphorus & Potassium. The farmer can monitor all these parameters wirelessly on a mobile phone or the PC System.To measure the Soil Moisture, we will use a Capacitive Soil Moisture Sensor. The temperature of the soil can be measured using the DS18B20 Waterproof Temperature Sensor. Similarly, in order to measure the Soil NPK(Nitrogen,Phosphorus,Potassium) values, we will use a Soil NPK Sensor. All these sensors can be easily interfaced with Arduino and the results are intimated to the user. Based on the result of the soil monitoring system, a dataset is framed and trained using a machine learning based algorithm. According to that information, we can predict the types of crops that can be cultivated based on the nutrient level of that particular soil. We can also predict the fertilizer to be used based on the amount of nutrients present in the soil. By this we can predict the nutrient level and use the proper fertilizer and promote to plant appropriate crops which in turn provide good yield for the farmers.
A. Soil Nutrients Prediction
In this system, Soil nutrient level (Especially Nitrogen,Phosphorus and Potassium) is measured and intimated via display devices. In addition to this,Soil moisture and temperature is also measured and provides us with information about the condition of the soil for cultivation. Here we use various sensors to do the aforementioned function. The soil NPK sensor is suitable for detecting the content of nitrogen, phosphorus, and potassium in the soil. It helps in determining the fertility of the soil. The sensor can be buried in the soil for a long time.The sensor doesn’t require any chemical reagent. The sensor has high measurement accuracy, fast response speed, and good interchangeability & can be used with any microcontroller. To read the NPK Data you need any Modbus Module like RS485/MAX485. The Modbus module is connected to Microcontroller & to Sensor. The sensor operates on 9-24V. The accuracy of the sensor is up to within 2%. The nitrogen, phosphorus & potassium measuring resolution is up to 1mg/kg (mg/l). To measure the Soil Moisture Level we need a Soil Moisture Sensor. For this application, a Capacitive type of Soil Moisture Sensor is preferred. We will use an analog capacitive soil moisture sensor that measures soil moisture levels by capacitive sensing. It means the capacitance is varied on the basis of water content present in the soil. The measured capacitance is converted into voltage level basically from 1.2V to 3.0V maximum. The advantage of Capacitive Soil Moisture Sensor is that they are made of a corrosion-resistant material giving it long service life.The Capacitive Soil Moisture Sensor v2.0 operates between 3.3V-5.5V DC voltage. The output is in Analog form up to 3V Maximum. We can convert the output voltage into the Percentage value. Then to measure the soil temperature DS18B20 waterproof temperature sensor is used.This is a pre-wired and waterproofed version of the DS18B20 sensor used to measure something far away, or in wet conditions. The Sensor can measure the temperature between -55 to 125°C (-67°F to +257°F). The cable is jacketed in PVC. These 1-wire digital temperature sensors are fairly precise, i.e ±0.5°C over much of the range. They work great with any microcontroller using a single digital pin.The sensor requires two libraries like Dallas Temperature Sensor Library & One-Wire Library. It also requires a 4.7k resistor, which is required as a pullup from the DATA to the VCC line when using the sensor. Soil samples for laboratory analysis were collected at a depth of 0–30 cm from different. Two research datasets were created having entirely different properties. The first dataset consists of 50 soil samples, which is called here as the Global soil dataset. Soils for this dataset were collected in different locations having a large texture and chemical content variation. The second dataset consists of 8 soil samples collected at a local farm that has been fertilized, which is called here as Local soil dataset. The research datasets are relatively small due to the wide variety of chemical combinations among the soil samples. Therefore, seven subsamples of each soil were randomly collected and measured. The final dataset corresponding to the Global soil dataset consists of 350 samples, and the dataset corresponding to the Local soil dataset consists of 56 samples. In order to perform machine learning validation, the dataset of sub-subsamples corresponding to the Global soil dataset was split into test and training sets. Four sub-samples corresponding to the same soil were used to create the training set, and three sub-samples were used to create the test set. This is a standard procedure when soils with known spectra and chemical properties are included in the training set to validate the method’s selectivity. Such a strategy allows the prediction of soil properties with higher accuracy.
B. Crop Suggestion System using Machine Learning Approach
The data relating to the soil nutrition are collected from soil testing historical data which provides general crop data. The major crops like wheat, rice, bajra, maize and jowar and minor crops like pulses, gram, jute, cotton, groundnut, barley, ragi, mustard, sugarcane, sesame, and sunflower are considered in the model. The important features of the dataset are of soil type Sandy, Silt, Clay and Loamy Soil, pH value of the Soil is a measure of the acidity and alkalinity in soils, NPK content of the soil which is nitrogen, phosphorus and potassium are the three nutrients used by plants, Permeability of the soil is the property to transmit water and air, the water content in the soil, average rainfall, temperature and previously harvested crop. All these parameters are really important to determine the best crop for current weather, market demand and availability of market infrastructure, expected profit and risk. Data preprocessing is a data mining approach that entails converting raw data into a format that can be understood. Because the original dataset may have a large number of missing values, all of them should be eliminated at first. Missing values are represented by a dot in the dataset, and their existence can degrade the overall value of the data as well as impair performance. As a result, we replace these numbers with the mean values to fix this problem. The second step is to create the class labels. Because we're utilizing supervised learning, there should be a class label for each entry in the dataset, which is produced during the preprocessing phase. Regression Analysis is a predictive modeling technique that examines the relationship between a dependent or target variable and an independent or predictor variable. It covers linear, multiple linear, and non-linear regression models, among others. Simple linear regression is the most used model. Polynomial regression is a type of regression method in which the link between the independent variable x and the dependent variable y is described as an nth degree polynomial in x. polynomial regression fits a nonlinear relationship between the value of x and the associated conditional mean of y, denoted by E(y |x). Despite the fact that polynomial regression fits a nonlinear model to the data, as a statistical estimation problem it is linear in the sense that in the unknown parameters inferred from the data, the regression function E(y |x) is linear. As a result, polynomial regression is regarded as a subset of multiple linear regressions. The predicted value of y may be modeled as an nth degree polynomial in general, producing the generic polynomial regression model. C. Fertilizer Recommendation System using Machine Learning Approach Soil nutrients can directly affect the growth of a crop and its production. Improvement of fertilizer recommendation based on production domains is important to supply the right amount of fertilizer for sustainable crop production and efficient balance between ecological and economic benefits. Plant diseases can also be caused due to insufficient levels of soil nutrients. Also applying an excessive amount of soil fertilizer may also result in adverse crop development. As the wet season to dry season, there will be changes in the content of soil nutrients. Using machine learning algorithms, by training a model we can predict suitable soil fertilizers for the land. An observation was made that by using fertilizer with the recommended dose which is calculated based on soil test values, farmers can harvest approximately 8–21% maximum yield of various types of crops as compared to farmer’s usual practice. Our project aims to find a suitable fertilizer for the given crop based on the parameters such as moisture, temperature, and nitrogen, potassium, and phosphorus levels. Based on the given fertilizer recommendation, the farmer will also be provided with a suitable fertilizer to be used, which helps the farmers to get more yield. To Predict the particular fertilizer to be used , we use input parameters like N,P,K temperature, humidity,moisture and soil type and also crop to be grown. Fertilizer prediction process begins with the loading of the external fertilizers datasets. Once the dataset is read then pre-processing will be done by various stages as discussed in the Data Pre-processing section. After the data pre-processing, train the models using SVM, Random Forest classifier into training dataset. For a prediction of the fertilizers, we consider various factors such as temperature, humidity, soil PH and predicted crop to be grown. Those are the input parameter for a system that can be entered by manually or taken from the sensors. Predicted crop and input parameter values will be appended in a list.
Built With
- database
- iot
- machine-learning

Log in or sign up for Devpost to join the conversation.