-
-
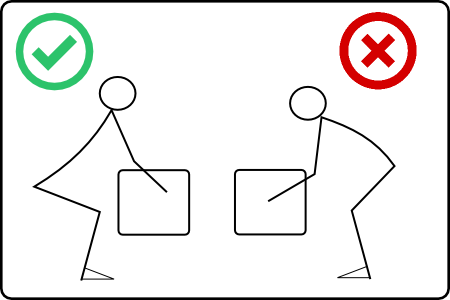
Back injuries can result from improper form such as rounding the back and not squatting low enough.
-
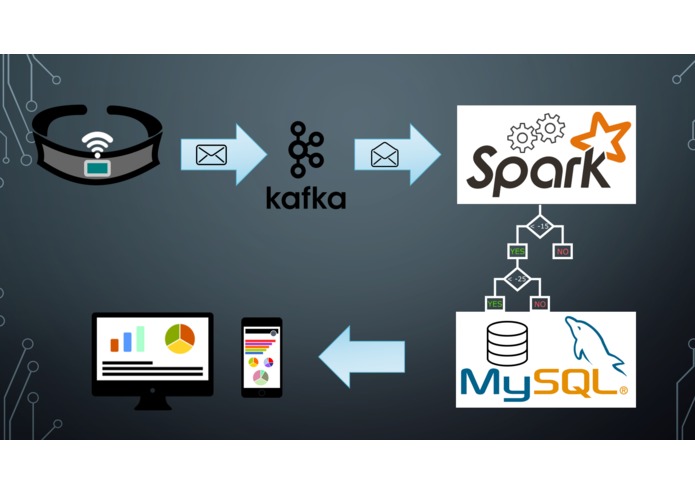
Device readings are sent to the cloud where they are categorized using a machine learning algorithm, and then finally surfaced in reporting.
-

The back brace device prototype!
-
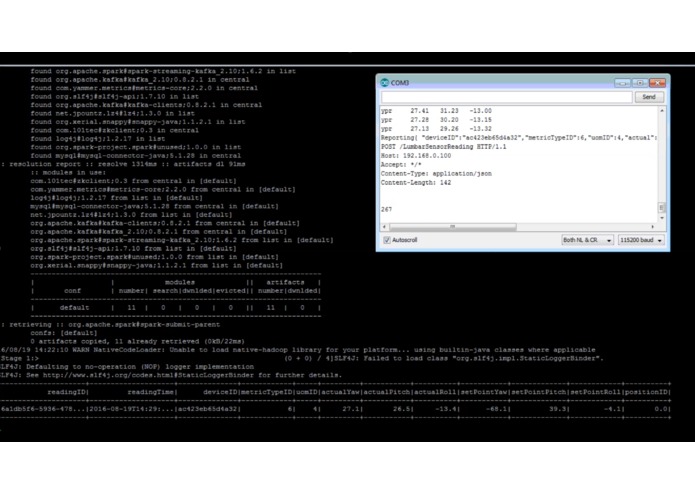
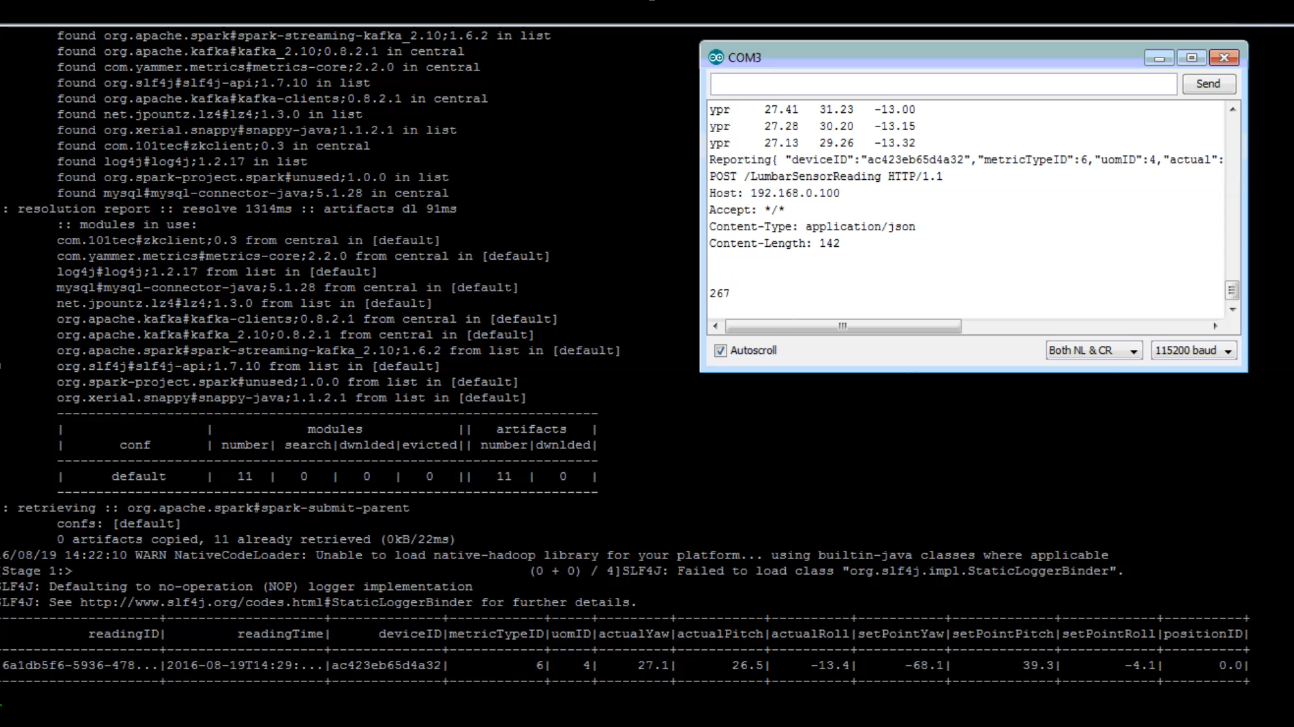
Readings from the Arduino are posted to a REST Web API via WiFi. Spark Streaming then goes into action classifying the posture.
-
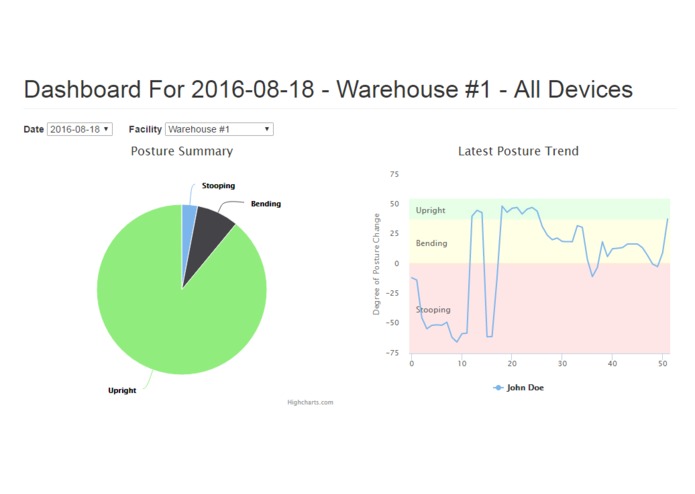
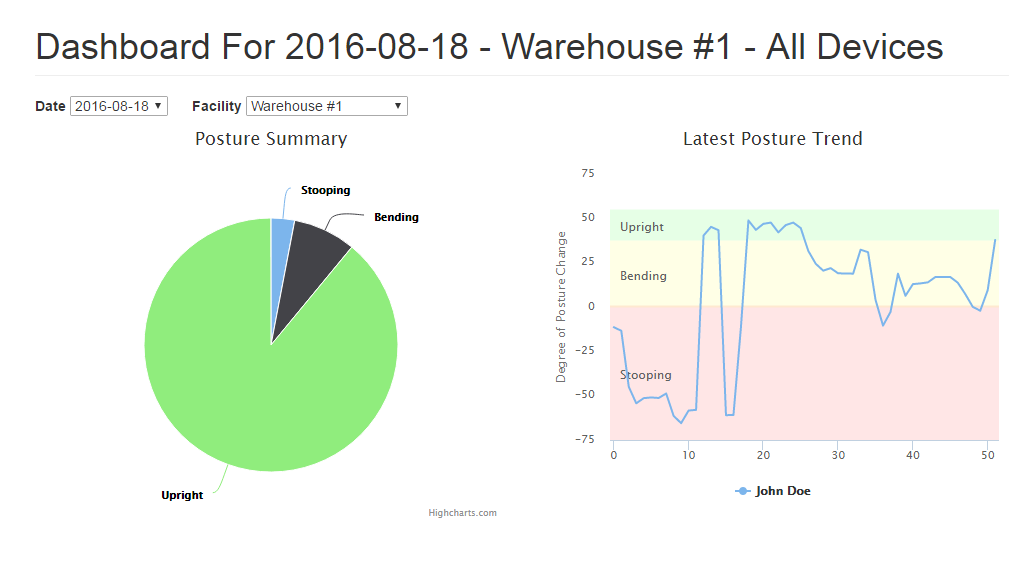
Check out the demo dashboard at http://sandbox.mycontraption.com/iotbb

Inspiration
Every year back injuries cost American companies billions of dollars in worker's comp claims, lost productivity, and insurance premium increases. According to the U.S. Bureau of Labor Statistics, back injuries are the number one cause of injuries incurred at work and impacts over 1 million workers every year. Many of these injuries are caused by improper lifting techniques such as stooping or bending to pick up objects or repeating certain movements, especially those that involve twisting or rotating the spine while lifting.
What it does
The IoT Back Brace is a device that helps identify - and report - activities that could potentially cause back injuries such as stooping, bending, and twisting. This is accomplished by continually monitoring the posture of a person... with an embedded microcontroller, gyroscope, and accelerometer. Although it is impossible to have perfect posture all of the time this device allows you to track the number of movements that are classified as potentially harmful. The back brace has an embedded Microcontroller outfitted with an Accelerometer/Gyroscope that continuously measures the posture of the person wearing it. Any activities that cause stooping or bending results in a reading being sent to a web API that then logs the reading through some back-end processing using the Apache Spark ecosystem (Spark Streaming, Spark SQL, and Spark Machine Learning).
How I built it
The Brace Device
The device (currently in prototype) can be attached to any existing back brace/belt and is made with the following components:
- Arduino Nano Microcontroller
- GY-521 Accelerometer/Gyroscope IMU
- ESP8266 Serial WiFi Module
The Back-End
- Web API: Python Flask script
- Message Handling: Apache Kafka Message Broker
- Processing, Classification, and Database actions: Apache Spark
- Database: MySQL
Reporting Dasbhoard
- PHP and MySQL are utilized for the data layer.
- AngularJS and HighCharts are used for the single-page dashboard.
The Process
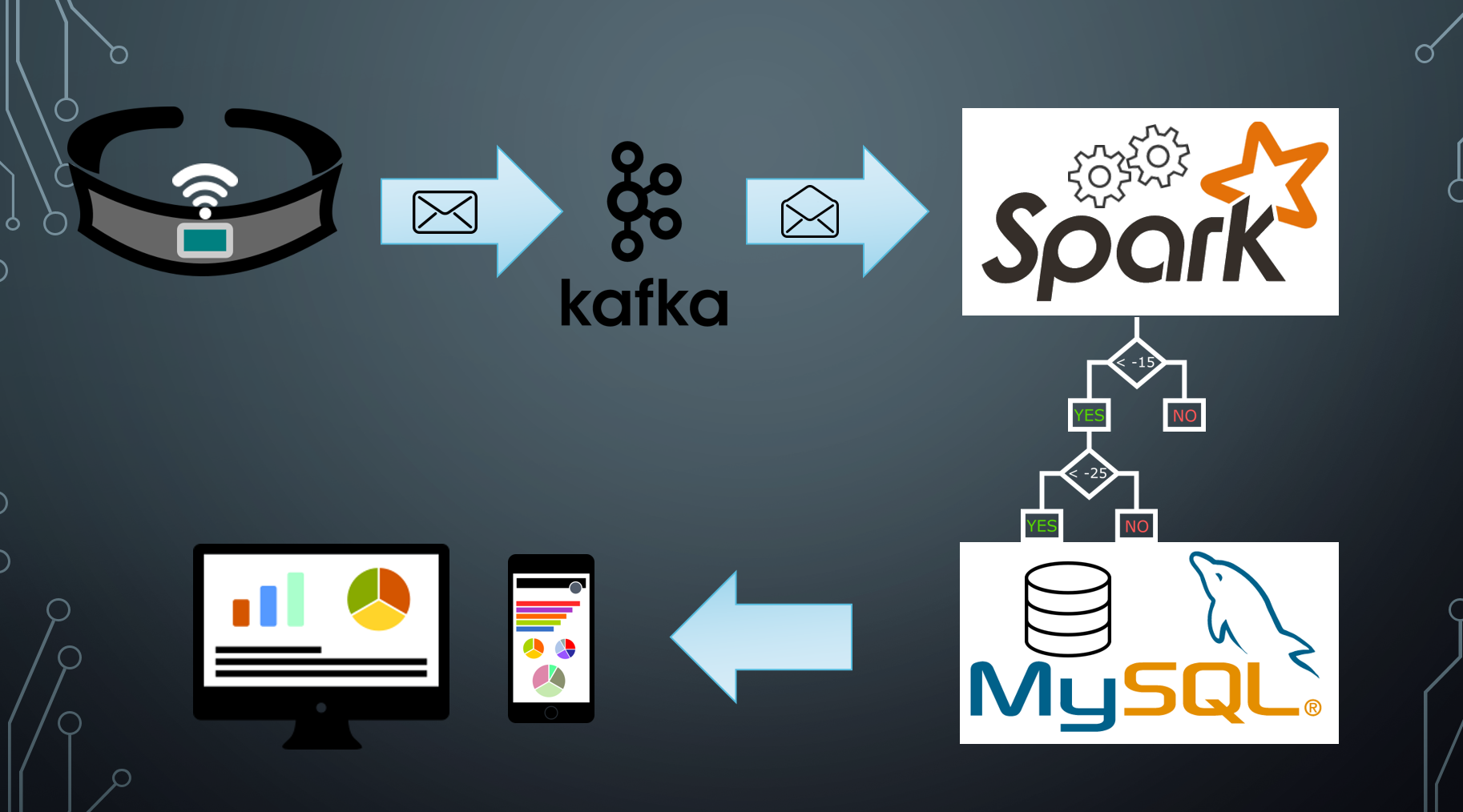
The process of reporting these metrics combines a wide range of open source technologies from the small Arduino microcontroller to Big Data and Machine Learning engines like Apache Spark.
As the posture of the person wearing the brace changes, an event is triggered, and a message containing the device readings is sent to the cloud where it is logged and categorized using a machine learning algorithm, and then finally those measurements are aggregated and surfaced in reporting.
The Process Amplified!
Although this process seems very simple on the surface, in order for it to be successful on an enterprise scale there needs to be some key technologies at play. Imagine a company with multiple locations - and dozens of braces - all reporting simultaneous events. The back-end processing for this deployment would require low-latency response time as well as "near-real-time" reporting for management. This back-end engine would also require easy scaling as they grow or expand the program.
So in order to ensure packets are not lost we have employed the use of a Kafka Messaging cluster. Each message containing the reading values is sent to the Kafka cluster through a REST API. This message is held in queue until the processing engine is ready to receive it. The processing engine in this case is provided by Apache Spark Streaming. With Spark Streaming, messages are opened and processed in a near continuous manner. The great thing about Spark is the processing is distributed amongst multiple nodes so if more speed is required the environment can easily be scaled to fit the requirements.
Classification on the Fly using Machine Learning
Apache Spark also provides an excellent machine learning library. In this case we are using a Random Forest classification model which is essentially an ensemble of decision trees that avoid over-fitting by averaging the results. The model is trained by sending known postures and their corresponding device readings. Through this training, thresholds are determined and a model is developed to translate posture measurements (which are numeric values to positions (such as “Stooping”, “Bending”, or “Upright”).
Key Files in the Process (All can be found on GitHub)
| Directory | File Name | Description |
|---|---|---|
| data_collection | ProcessSensorReadings.py | Creates a Spark Streaming job that reads messages from Kafka, then either treats as training data or actual data. Then writes the data to MySQL database. |
| web_api | WebServiceToKafka.py | REST service that listens for POST requests and creates a Kafka message. |
| Testing | KafkaProducerTest.py | Creates random readings and sends in JSON format to Kafka. Use this to test the data collection process |
Note: Look for the corresponding Jupyter Notebooks for these files for better explanation and a walk-through of the logic employed in this project.
Challenges I ran into
Since Spark is a distributed environment and operates on RDD's or distributed datasets, I often found myself trying to do tasks that would result in an error. And the error messages were often very long and sometimes hard to interpret. However, as I hacked away at the problem areas, I discovered that the root cause was usually my lack of understanding of what I was working with... Was it an RDD, a Pipelined RDD, a DataFrame, or even a Row within the DataFrame? Once I was able to work that out - And with the help of some good examples online - I was able to break through those sticking points.
Additionally, with the limited memory capacity of the Arduino, I had a very difficult time integrating the readings into String variables. If the string exceeded a certain size threshold it would silently just not use it. Since the http protocol is dependent upon specific strings, if any portion of the string got truncated the whole post would fail. This was very hard to debug.
What I learned
This build was my first exposure to Apache Spark and Machine Learning for that matter. I am absolutely excited by how many features that Spark has to offer. I was floored by how easy it was to stream data, use SQL-like expressions, and create machine learning models and apply those models to real data - All on the fly!
What's next for IOT Back Brace
This project is still in its infancy and it is needing some good code review/suggestions for improvement.


Log in or sign up for Devpost to join the conversation.