-
-
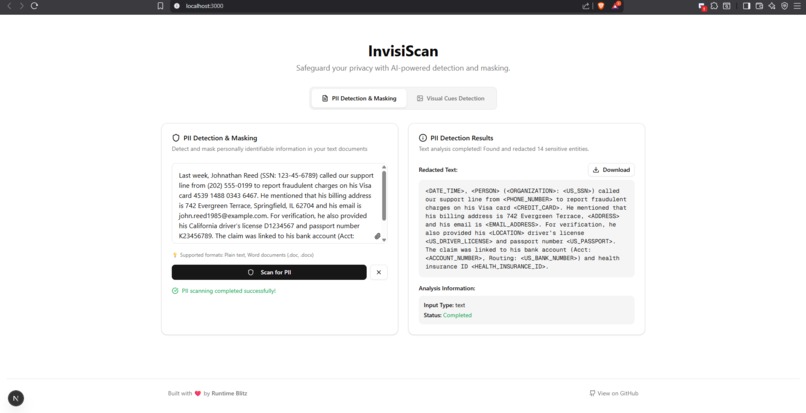
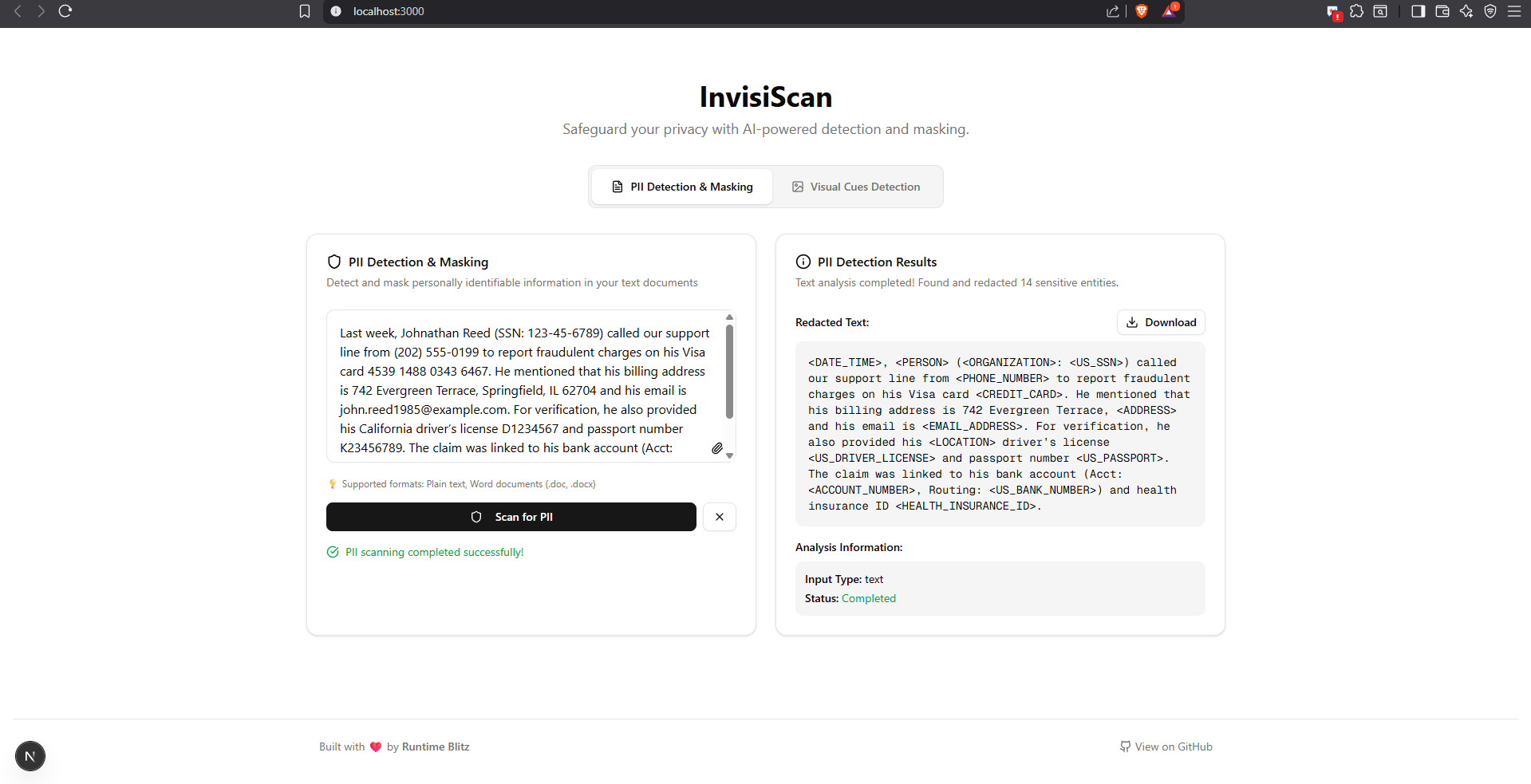
PII Detection
-
Upload Image For visual Cue analysis
-
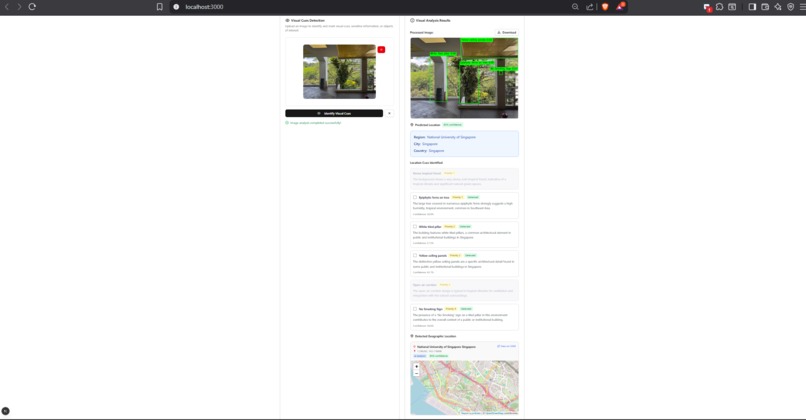
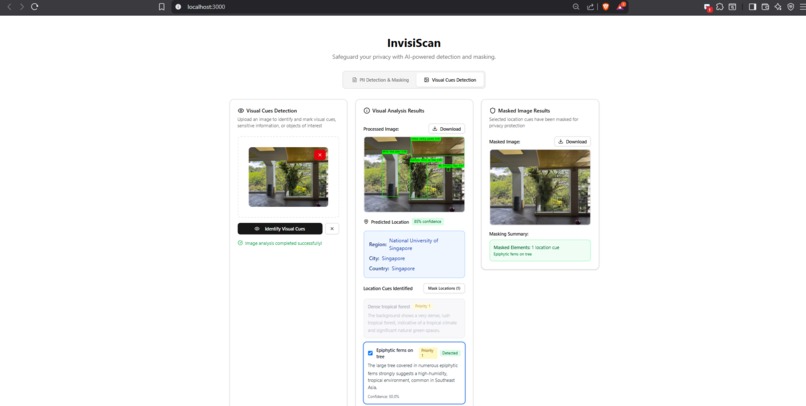
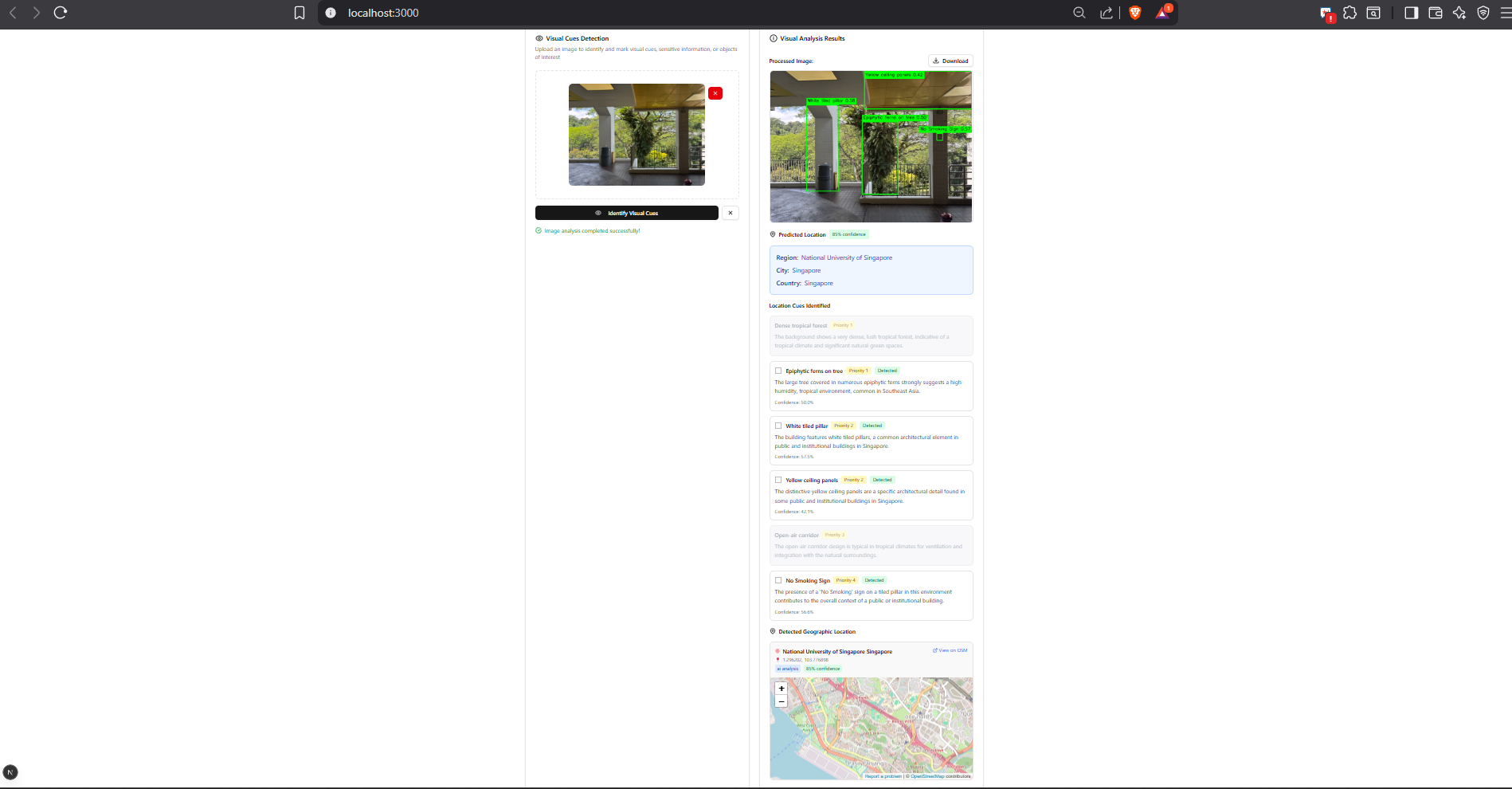
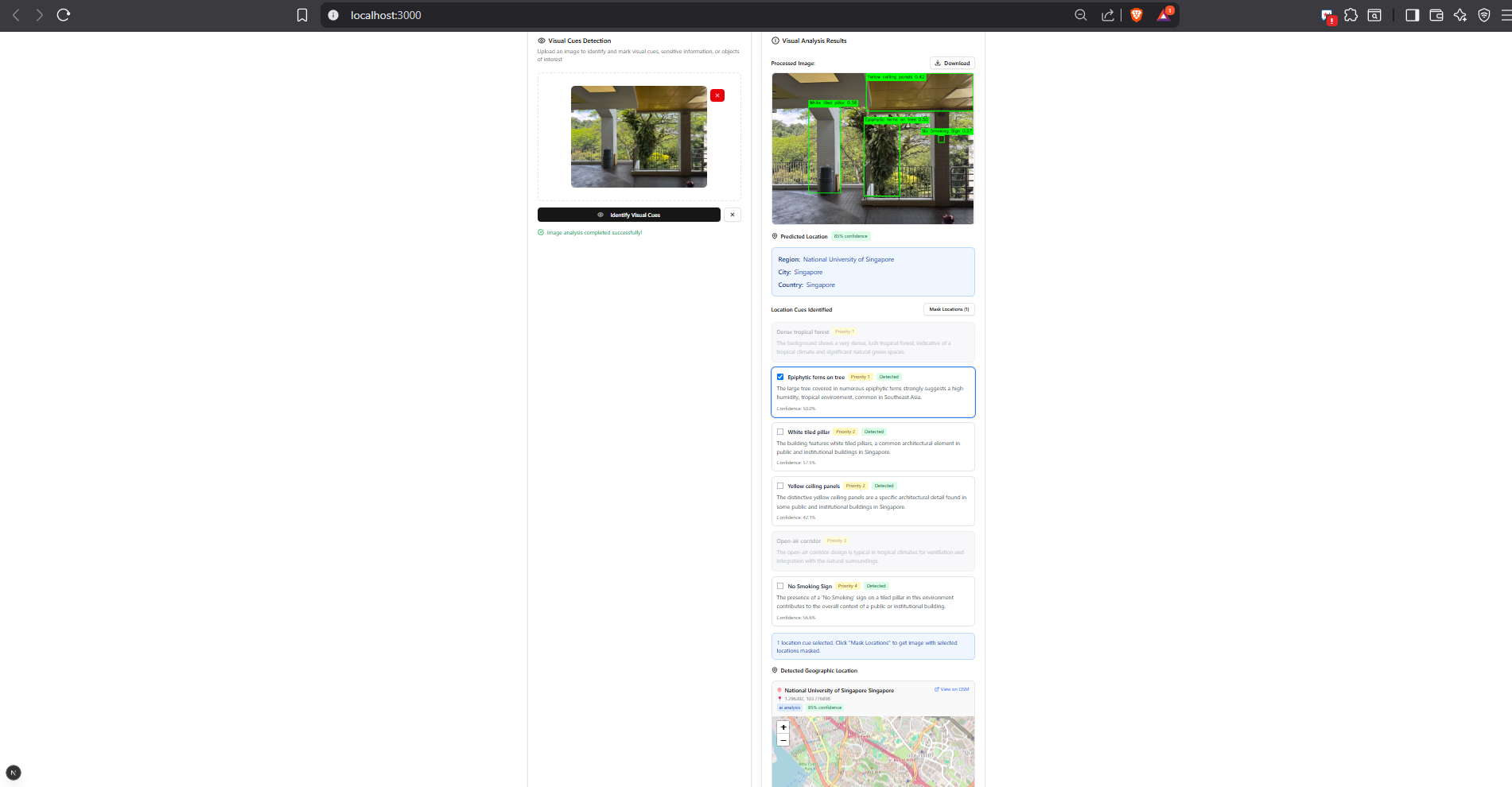
Visual Cue Analysis Result
-
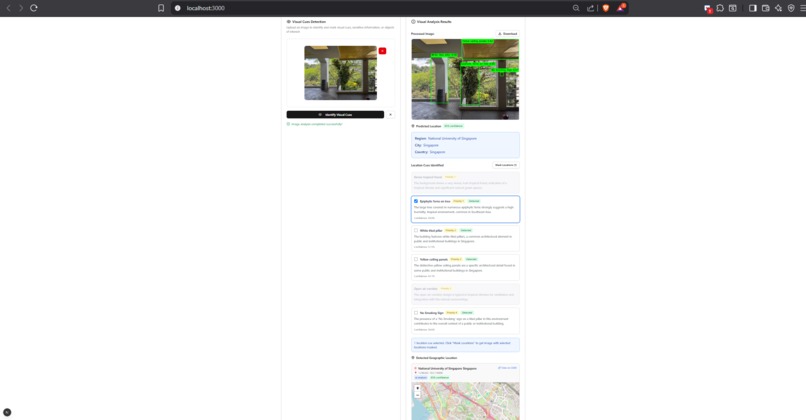
Selection of cues to mask
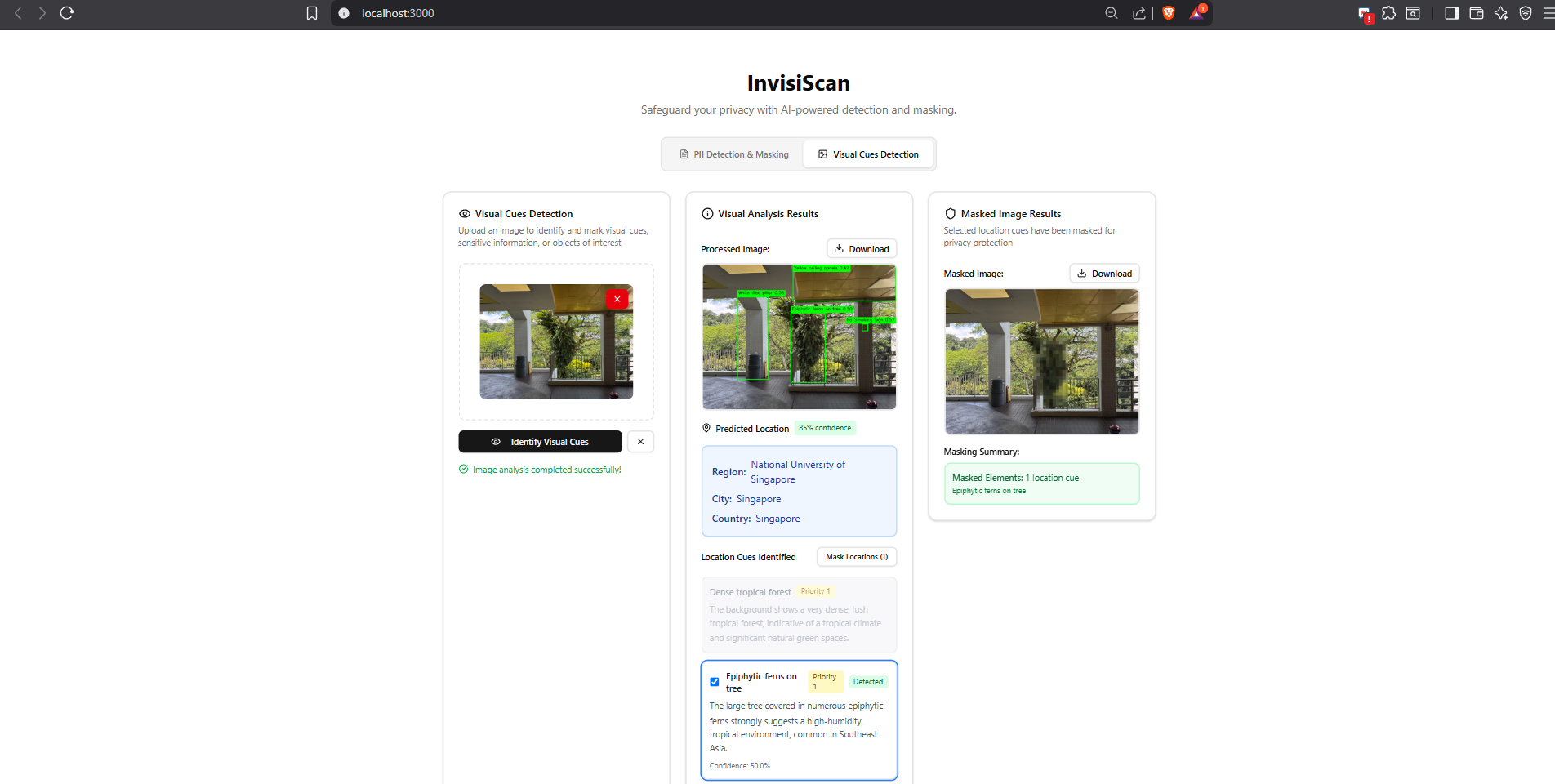
-
Masking Result
Inspiration
We were inspired by the realization of just how much sensitive information can leak from seemingly ordinary content. While reviewing the GenAI Location Privacy challenge in the TikTok TechJam 2025 Information Document, we tested it ourselves: we snapped a photo near NUS and gave it to ChatGPT-5. The model’s prediction was eerily accurate. That experience made us realize how easily privacy could be compromised—whether through hidden location cues in photos or personal information in text. To raise awareness and give users control, we set out to build a tool that reveals and defuses these hidden risks.
What it does
InvisiScan lets users upload photos or text and automatically analyzes them for privacy risks.
- For images, it detects location-revealing cues (like road signs or landmarks), highlights risky regions, masks them, and scrubs EXIF metadata.
- For text, it identifies and redacts personally identifiable information (PII) such as names, addresses, or ID numbers.
The result: safer content that reduces the chance of unintended leaks while keeping everything else intact.
How we built it
We combined three layers:
- LLM Geo-Hypotheses — Gemini 2.5 Flash suggests likely location cues from the image.
- GroundingDINO Detection — Open-vocabulary object detection finds those cues in the image and returns bounding boxes.
- Privacy Transform — EXIF metadata is stripped and smart pixelation masks the highlighted cues.
For text, we built a hybrid PII pipeline combining spaCy NER with intelligent regex patterns to catch sensitive data.
We stitched it all together with FastAPI endpoints, Playwright helpers for data scraping, and Pydantic models for clean orchestration.
Challenges we ran into
- PII data was being misclassified, so we combined spaCy NER with regex for higher accuracy.
- LLM predictions for geo-location were sometimes unreliable, requiring tuning and filtering.
- GroundingDINO initially produced inaccurate bounding boxes, so we added box-size filtering and cue prioritization.
- Balancing hackathon development with heavy coursework made time management a constant challenge.
Accomplishments that we're proud of
- Built a working end-to-end pipeline in hackathon time that processes both photos and text.
- Achieved strong cue detection, with ~50% of LLM guesses falling within 100 km of the ground truth in early tests.
- Designed the system to be privacy-first, re-encoding images to strip EXIF and redacting PII by default.
- Pulled this off under intense academic schedules, showcasing teamwork and rapid problem-solving.
What we learned
- Privacy leaks extend beyond GPS tags—subtle visual cues and personal text data can be just as revealing.
- Open-vocabulary detection like GroundingDINO pairs really well with LLM-inferred phrases.
- PII detection benefits from hybrid methods rather than relying on a single model.
- Building for privacy means balancing accuracy with usability—protecting without over-masking.
What's next for InvisiScan
- Integrating SOTA SAM models for tighter, shape-aware masking.
- Adding inpainting models to naturally fill masked regions instead of pixelating them.
- Building an iterative loop to re-analyze masked photos/text and verify risk reduction.
- Integration with Google StreetView API for more accurate results.
Built With
- fastapi
- llms
- ner
- nextjs
- ocr
- pydanticai
- python
- react
- regex
- spacy
- transformers
- typescript


")






Log in or sign up for Devpost to join the conversation.