-
-

how it's going, augmented reality enabled invisible city explorer (hackathon release)
-

how it all begun, lost skateboard down the hooole
-
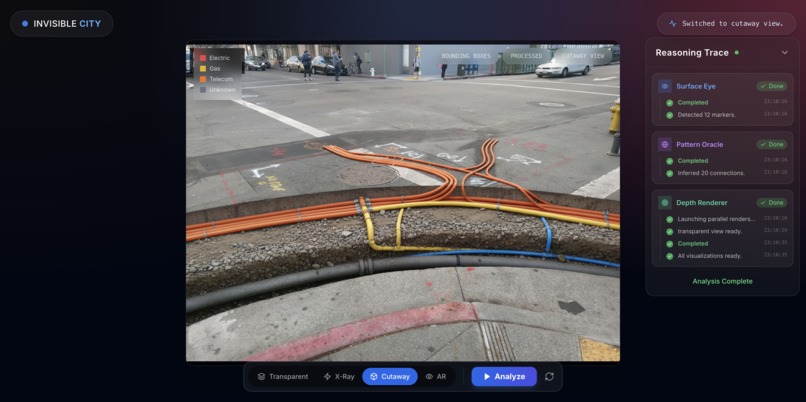
Static analysis (aka Non-live) mode (old release)
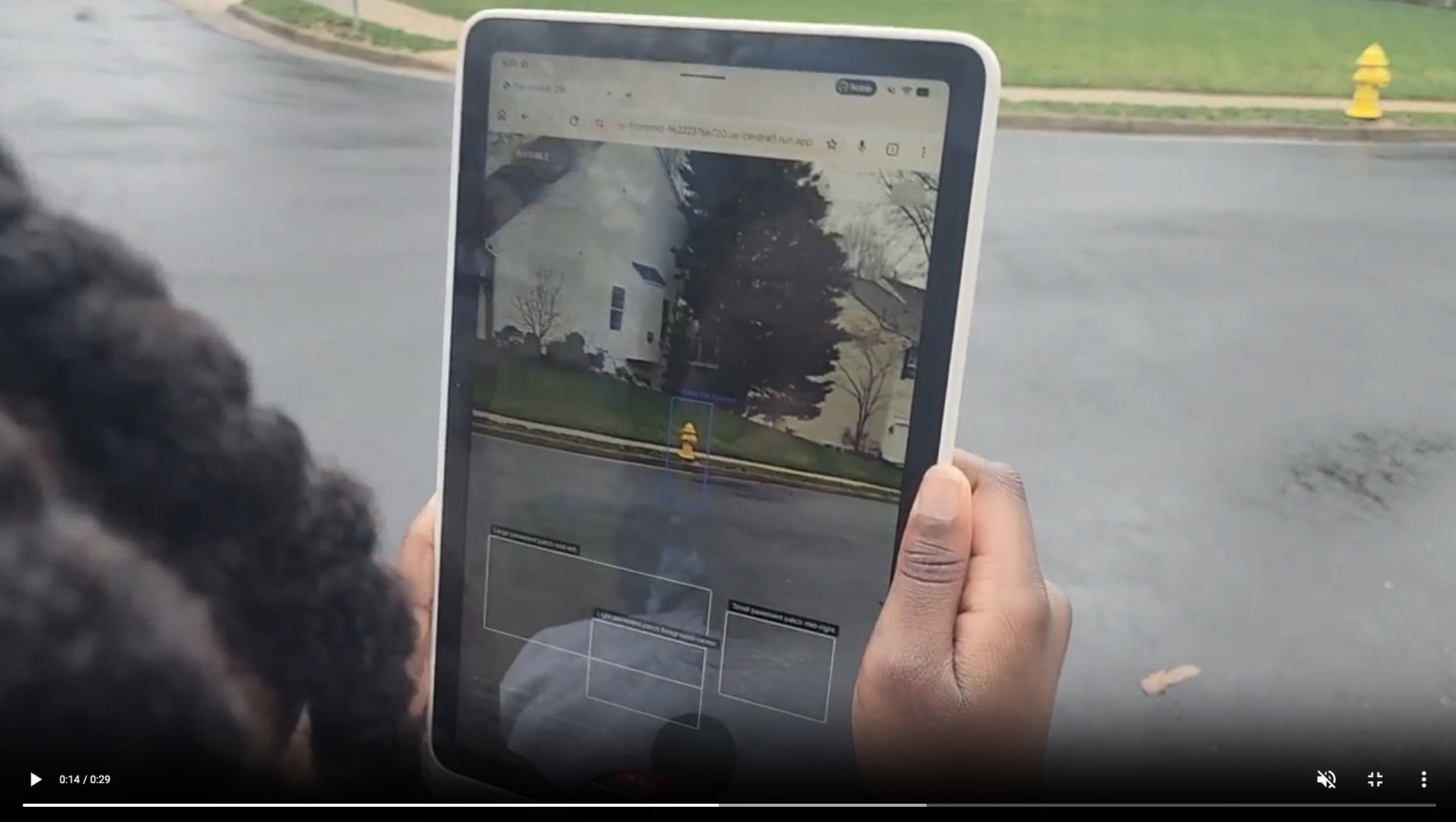

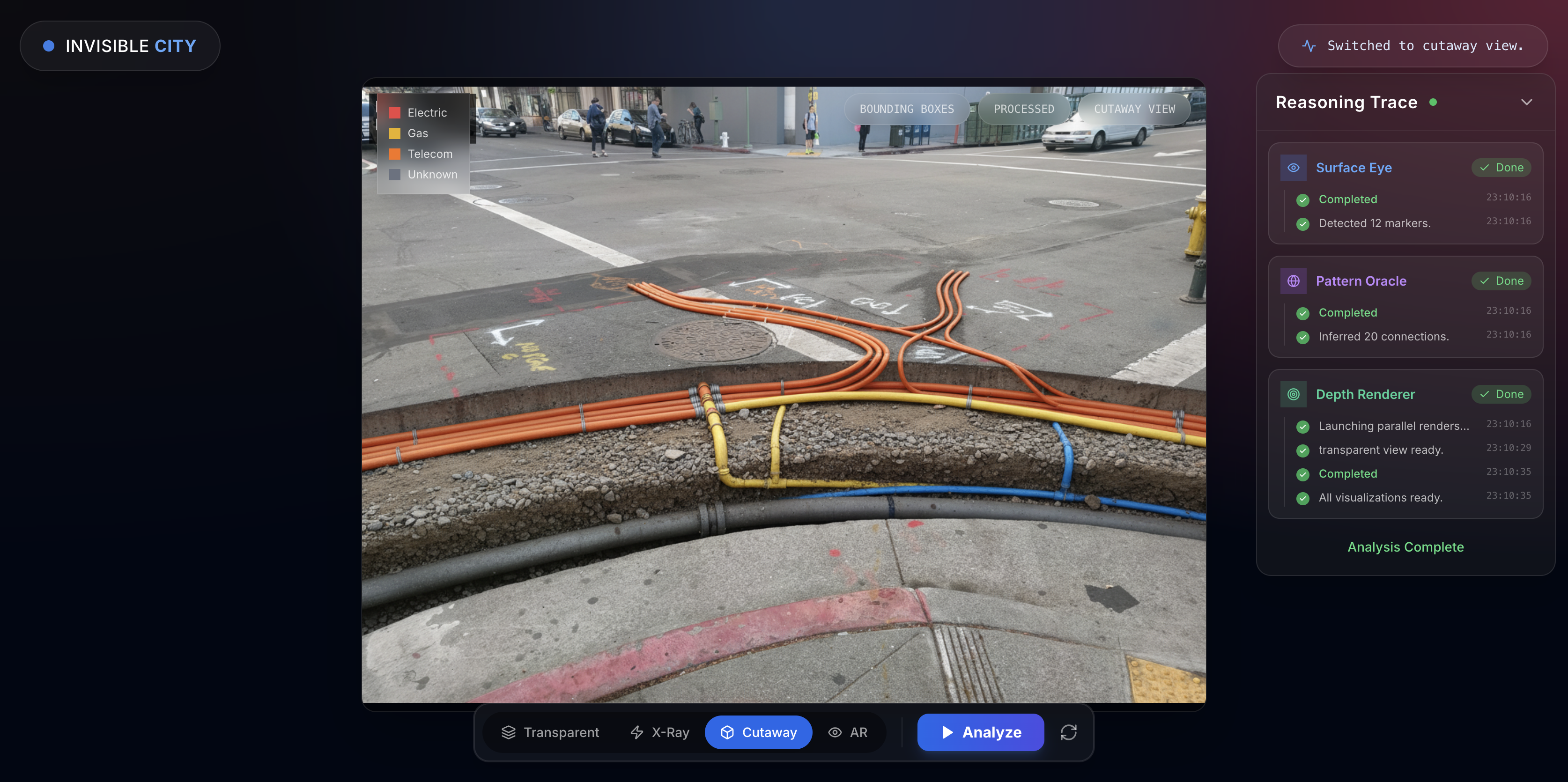
My daughter's skateboard disappeared down a storm drain last summer. I lifted a 60-pound manhole cover and climbed into the dark while she supervised from above. After the rescue, she became obsessed with what's underneath streets. The questions escalated until she delivered her million-dollar pitch with complete sincerity: "big brain idea dad...we should invent an X-ray machine for streets so we can find lost things."
She was onto something. Every street is covered in clues, fire hydrants signaling water mains, manhole covers marking sewer access, spray-painted lines following the APWA color code (red for electric, yellow for gas, blue for water). Utility workers read these signals instinctively. I wanted to see if collaborating AI agents could learn to read them too.
The result is The Invisible City — a system where three specialized agents detect, reason about, and visualize hidden underground infrastructure from ordinary street scenes. The flagship mode, The City Whisperer, streams live mobile camera video to Gemini and narrates the invisible city beneath your feet in real-time. It's the X-ray machine my daughter imagined — except it talks.
Building with ADK: From Functions to Agents
The foundation is Google's Agent Development Kit. Each of the three agents — Surface Eye (vision), Pattern Oracle (reasoning), Depth Renderer (visualization) — is an ADK agent with its own tools, typed schemas, and system instruction. ADK gave me two things that raw SDK calls couldn't: a clean tool abstraction layer through FunctionTool that wraps async Python functions with Pydantic-validated inputs and outputs, and agent lifecycle management that handles retries, context passing, and structured output parsing.
Surface Eye, for example, wraps a Gemini 2.5 Flash vision call that returns structured JSON — bounding boxes in a 0–1000 coordinate grid with marker types, utility classifications, confidence scores, and reasoning explanations. The structured output isn't just for display; it's the API contract that downstream agents depend on. Pattern Oracle consumes Surface Eye's typed SurfaceMarker objects and runs deterministic nearest-neighbor chaining to infer underground network topology — no LLM calls on the hot path, just domain logic operating on typed data. Depth Renderer takes both upstream outputs and generates "see-through" visualizations using Gemini 3.1 Flash Image Preview, with deterministic compositing as automatic fallback.
The deliberate split between LLM-driven and deterministic stages was a key architectural decision. Surface Eye and Depth Renderer need Gemini's multimodal capabilities. Pattern Oracle doesn't, it needs reliable, repeatable inference. ADK let me mix both approaches within the same orchestration pipeline without forcing everything through an LLM.
A2A Protocol: From Monolith to Discoverable Agents
The original version was a monolith, three agent classes called sequentially in a single process. It worked, but it didn't demonstrate the kind of agent interoperability that matters at scale.
Replacing custom agent servers with ADK's A2aAgentExecutor was the inflection point. Each agent now auto-serves an A2A discovery card at /.well-known/agent.json, describing its capabilities, input/output schemas, and endpoint. The orchestrator uses RemoteA2aAgent to discover and invoke agents through the A2A protocol, wired together with SequentialAgent for the detection → reasoning → visualization pipeline.
This matters beyond the demo. A2A means Surface Eye could be replaced with a different vision agent , one using YOLO instead of Gemini, or one specialized for aerial imagery — without changing Pattern Oracle or Depth Renderer. The protocol decouples the pipeline stages. In practice, I built three execution modes behind the same API contract: Vertex AI Agent Engine (production hosting), distributed A2A via RemoteA2aAgent (the protocol-native path), and direct function calls (default fallback). The backend switches between them via environment variables. Same endpoints, same typed responses, different orchestration plumbing.
I also added resilience at the A2A layer, circuit breaker (5 failures triggers 30 seconds of open state), exponential backoff retry across agent calls, and a2a_compat.py to isolate the A2A SDK v0.3/v1.0 migration path so the codebase doesn't break when the protocol evolves.
Gemini Live API: The Moment It Became Real
Static analysis is a technical demonstration. Real-time narration is an experience. The Gemini Live API is what turned The Invisible City from a portfolio project into something that feels genuinely magical.
The City Whisperer captures mobile camera frames at 1fps, sends them as base64 JPEG over a WebSocket to a FastAPI backend, which bridges them to Gemini 2.5 Flash Native Audio Preview using ADK's runner.run_live() with LiveRequestQueue. I happened to fascilitate a Build with AI workshop for Google Cloud team in early march and was further inspired since what I shipped\ follows the Way Back Home Level 4 codelab pattern, and for good reason. The LiveRequestQueue handles bidirectional streaming lifecycle, audio chunking, and the interleaving of video input with audio output in a way that's painful to manage with the raw genai SDK. The browser plays back 24kHz PCM audio chunks through an AudioContext that must be created inside a user gesture handler to satisfy autoplay policies.
The hardest problem wasn't the streaming, it was getting Surface Eye's bounding boxes to align with the live camera feed. Gemini analyzes a square center-cropped JPEG, but the camera displays in native aspect ratio. CSS percentage positioning drifts because percentages reference the container, not the rendered image. The fix: compute the exact rendered camera crop rect (accounting for letterboxing and scaling) and position overlays in absolute pixels relative to that rect. We wrote fitted-media.ts to measure the actual DOM element and Playwright E2E tests that verify alignment within 2 pixels.
The other major challenge: native audio Gemini models have unreliable function calling (~1 in 20 success rate, tracked in GitHub issue #843). The ideal architecture has Gemini calling Surface Eye directly during narration. The working architecture runs Surface Eye as a parallel backend timer task every 15 seconds, completely independent of the narration model. It's not elegant, but it's reliable, and the code is structured so the timer can be removed when upstream tool calling improves.
One subtle bug cost hours: sending an initial send_content text prompt when the Live session starts caused Gemini to narrate its entire system instruction verbatim. The fix was counterintuitive, don't send any text at all. Let video frames trigger narration naturally.
What I'm Proud Of
Pointing your phone at a street and hearing Gemini describe the water main under the manhole cover feels like the thing my daughter imagined. Three agents genuinely collaborate, Surface Eye's detections feed Pattern Oracle's reasoning, which feeds Depth Renderer's visualization, each with typed data contracts and distinct responsibilities. All visualizations follow the APWA Uniform Color Code, grounding the project in real infrastructure engineering. And the system degrades gracefully at every layer: if AI generation fails, deterministic compositing takes over; if tool calling fails, backend timers compensate; if a single detection parse fails, the other markers still render.
The codebase is ~9,700 lines across 69 files, backed by 115 automated tests (including golden baseline regression against 8 real street images), deployed as 2 containers on Cloud Run with automated deployment scripts in the repo.
What's Next
The City Whisperer is 2D bounding boxes on a camera feed. The real vision, my daughter's vision, and my obsession with augmented reality is seeing through the sidewalk. WebXR via ARCore and perhaps some day AndroidXR spatial anchors would make infrastructure overlays persistent in 3D space as you walk. Voice interaction would let you ask "what's under this manhole?" and get a spoken answer while looking at it. And when Google resolves the native audio tool calling reliability issue, the narration model can invoke Surface Eye directly, enabling truly real-time detection synchronized with speech instead of the 15-second timer workaround.
The invisible city has always been there. Now it's starting to whisper back.
Built With
- a2a
- adk
- gemini-live-api
- google-cloud-build
- google-cloud-run
- vertex-ai-engine


Log in or sign up for Devpost to join the conversation.