-
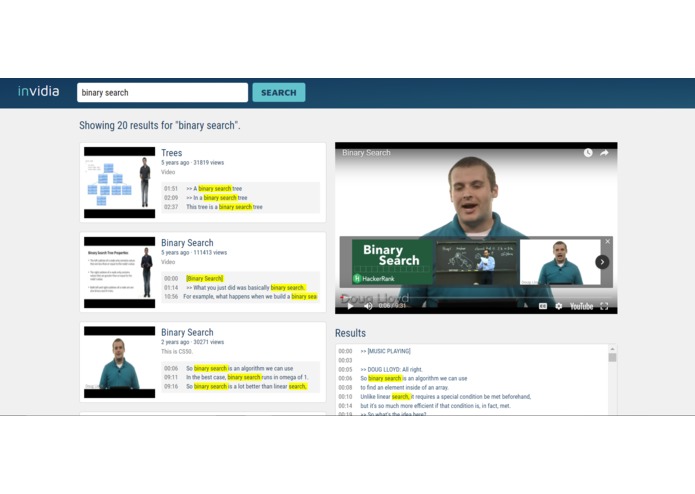
A sample UI
-
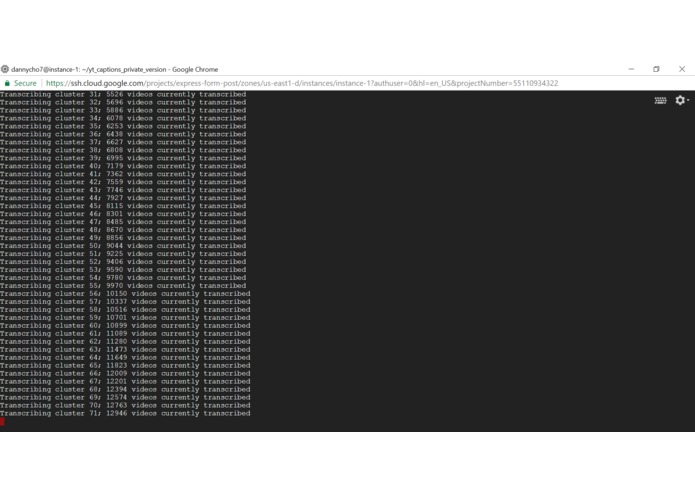
Generation of transcription clusters
Inspiration
YouTube money $$ encourages content creators to utilize click bait titles and other SEO tactics to receive the most views. That results in a less favorable search experience.
What it does
Allows you to search for videos based on what is actually SAID in the video. Imagine if videos were actually just web pages and you can google search them.
How I built it
We indexed over 300k YouTube videos (35 GB of transcript data) and grabbed their transcriptions(scope of the hackathon, but at scale there are no limitations) and used elastic search for searching
Challenges I ran into
Aggregating big/large amounts of data is tough at hackathons, since WiFi is flaky.
Accomplishments that I'm proud of
Being able to aggregate the data
What I learned
Data is fun
What's next for Invidia
We will be launching after the hackathon!
Built With
- elasticsearch
- node.js
- react.js
- youtube

Log in or sign up for Devpost to join the conversation.