-
-
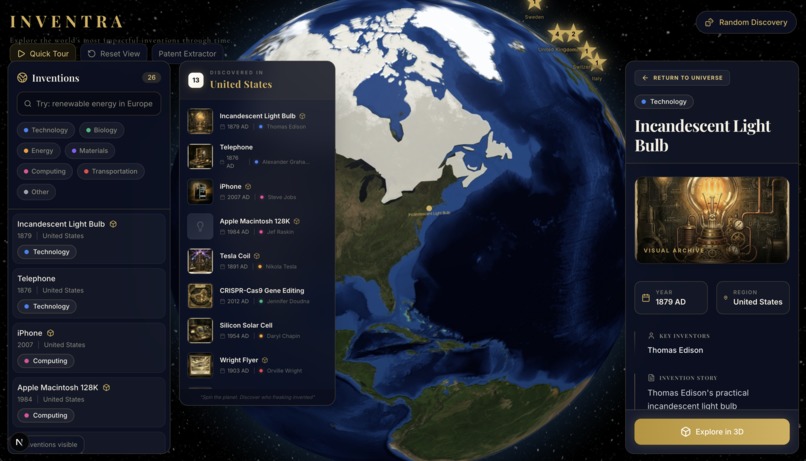
Discovery page - find innovations that inspire
-
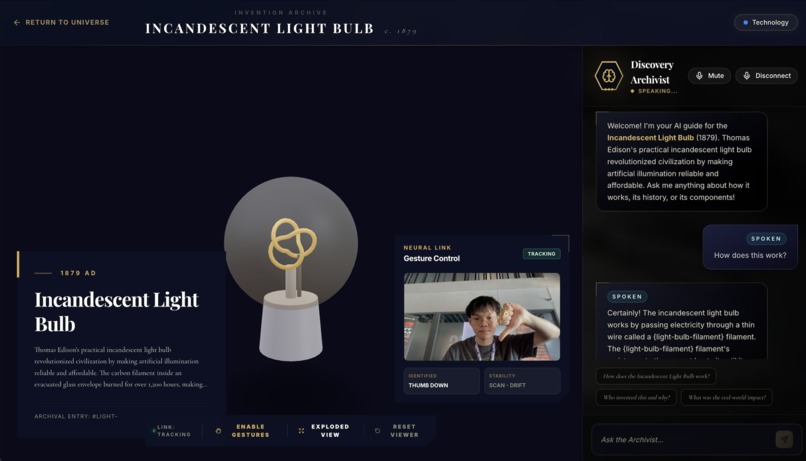
Learn page - patents turned reality, interact with innovations that changed the world
-
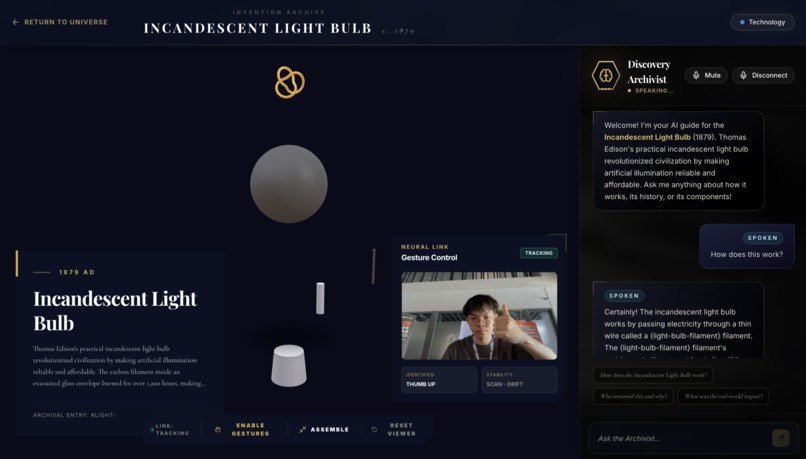
Engage and disassemble - learn through auditory and visual interactions
-
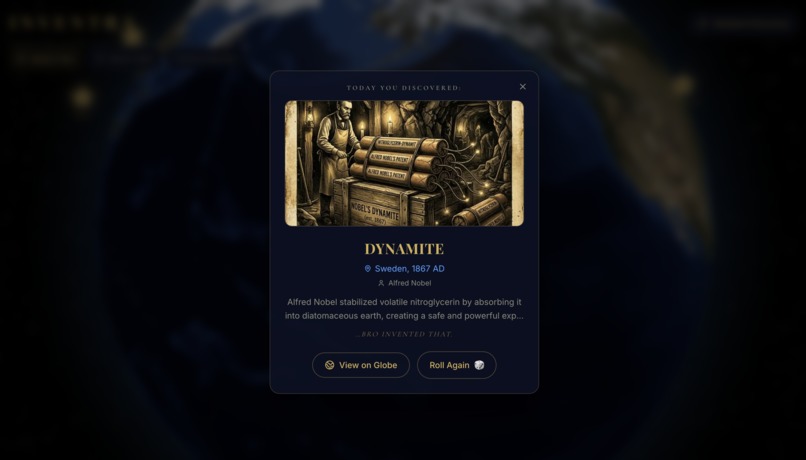
"Surprise me" in Discovery - best knowledge comes from the least expected place
-
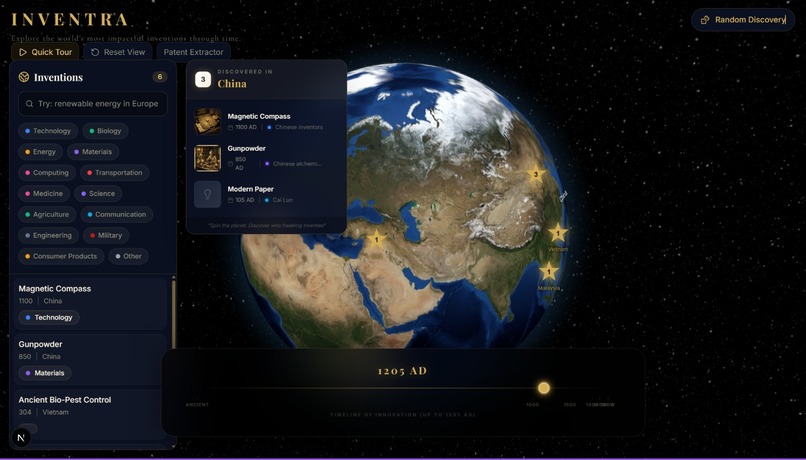
Timeline view on Discovery shows the inventions from different eras
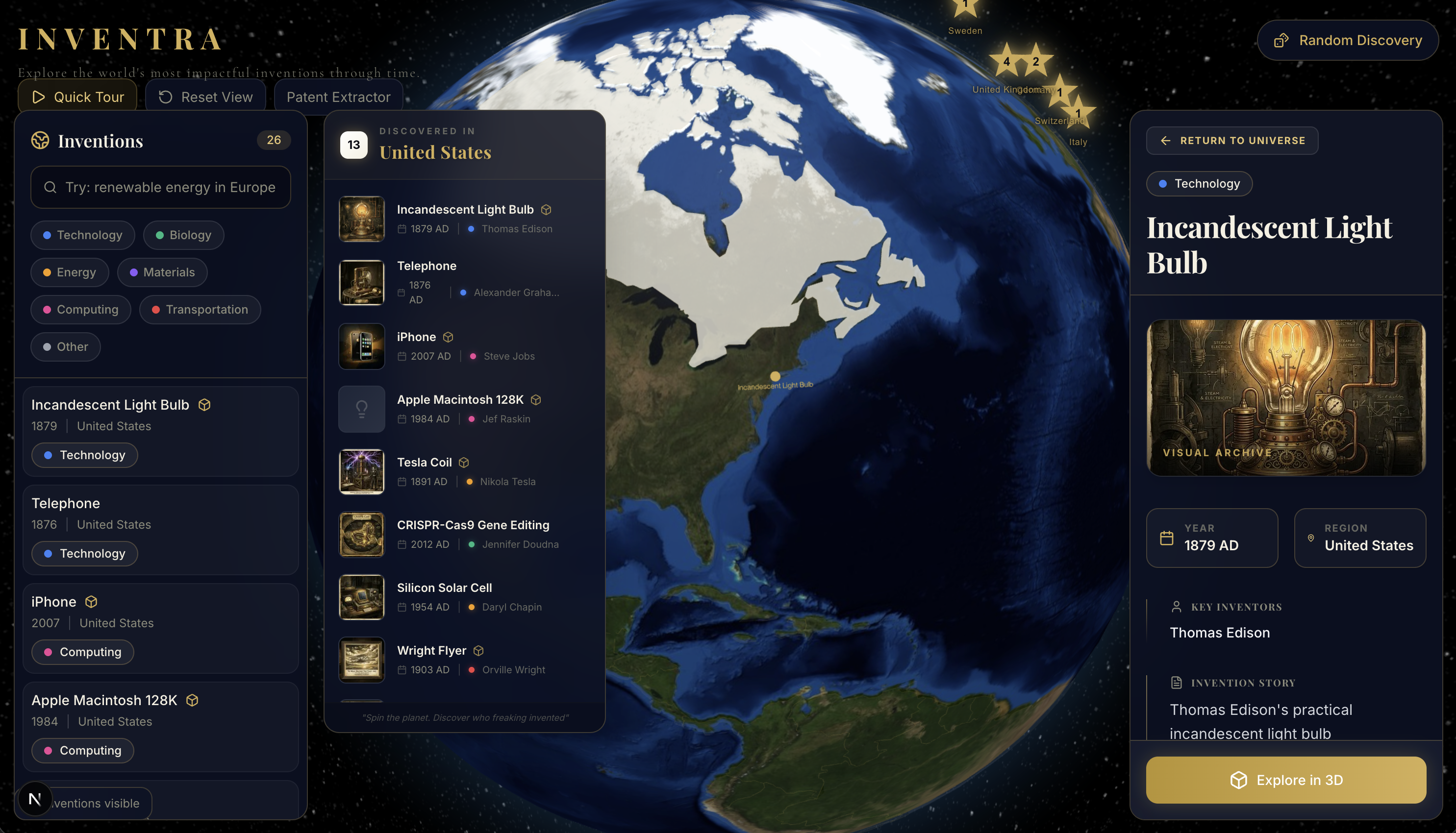


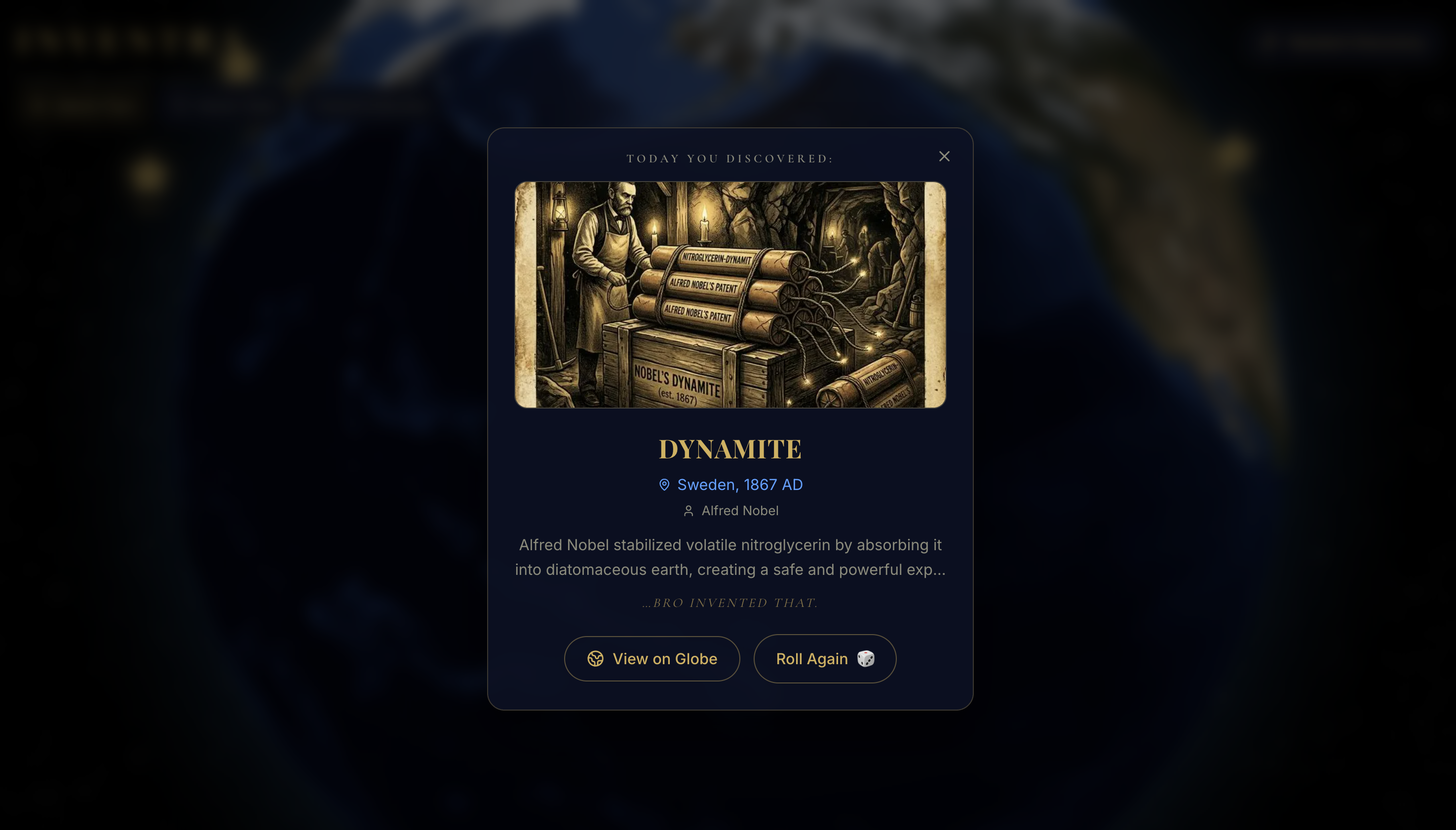
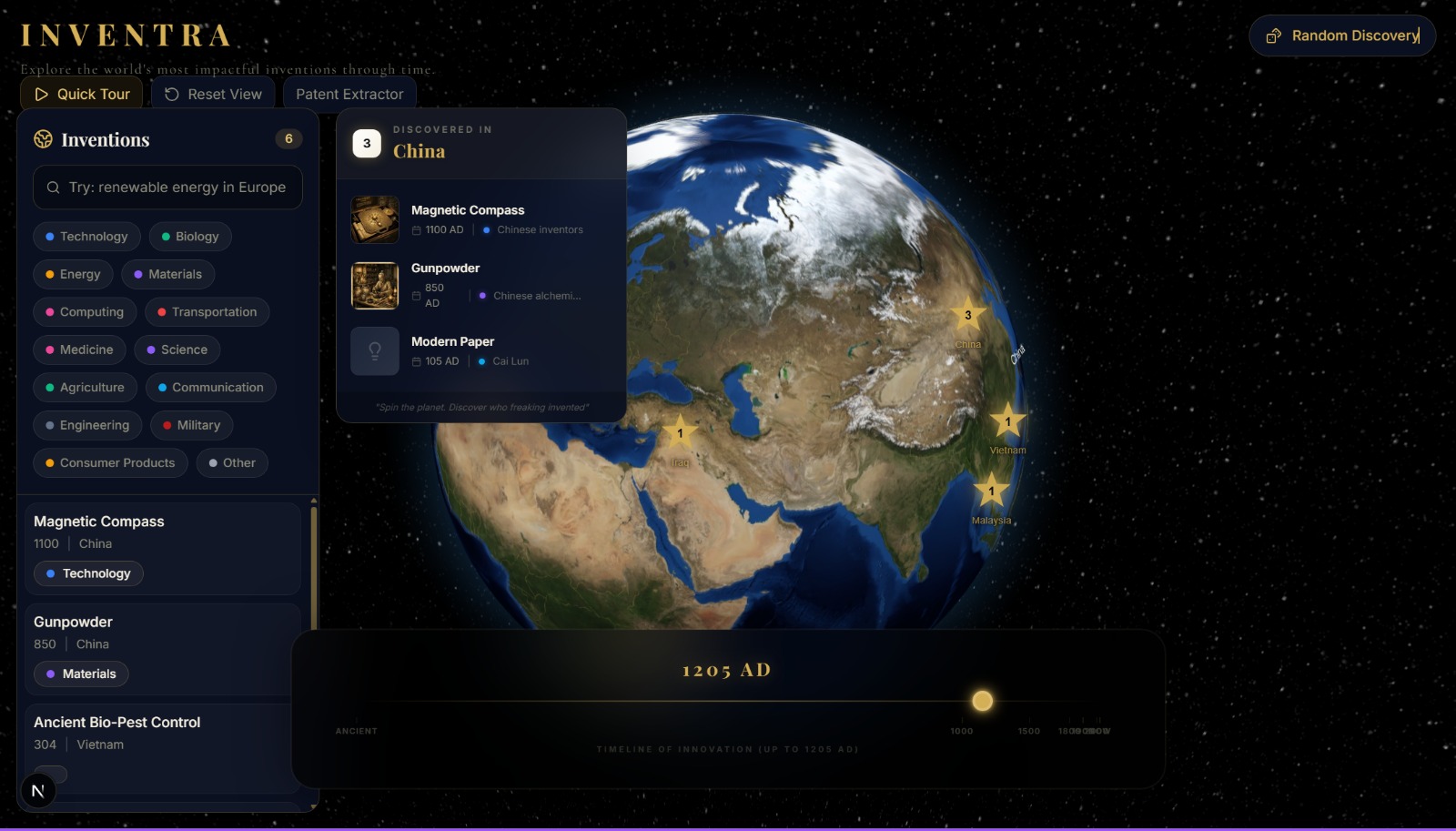
Inspiration
Understanding how cool but complex inventions, especially machineries, are hard. We want to learn how they work, 100% from the original patent and from the inventor's own voice, without have to wait for someone to create this youtube explainer video which might not always meet our expectations. We also wanted it to be interactive, like you're directly speaking to the inventor himself. He could walk you through the invention and animate specific components to help you better visualize. Understanding how complex inventions and machinery actually work is genuinely hard. We wanted to learn directly from the source — the original patent — delivered in the inventor's own voice, without waiting for a YouTube explainer that may never come (or never quite hits the mark). We also wanted it to be interactive: like speaking to the inventor himself, who walks you through the creation, animates specific components to help you visualize, and answers your questions in real time.
What it does
Inventra turns any patent into a grounded, interactive documentary. Upload a patent PDF and get a dedicated learning experience: a voiced AI expert walks you through the invention, its history, its mechanics, and the mind behind it. Ask questions by voice or text and watch the 3D model respond - specific parts highlight and animate as the explanation unfolds. Bonus: hand gesture controls let you rotate, explode, and assemble the 3D model with your bare hands.
How we built it
- Framework: Next.js (App Router), React, Tailwind CSS
- 3D: React Three Fiber + drei + Three.js — procedural primitives and fal.ai Trellis 2–generated GLB meshes
- AI & Voice: OpenRouter for chat and reasoning; Agora CAE + RTC for live voice sessions; ElevenLabs for Agora-managed TTS
- Patent pipeline: TinyFish for patent information extraction; OpenRouter vision to identify figures and components; fal.ai Nano Banana for image generation; fal.ai Trellis 2 for image-to-3D mesh generation
- Gestures: MediaPipe Tasks Vision (runs locally in the browser)
- Storage: Vercel Blob for patent workspace caching
- Dev tools: Codex, Trae, Exa for fast and accurate research during development
Challenges we ran into
Far greater complexity and integration difficulty of the 3D model generation pipeline. The workflow breaks not because of error but due to terrible outputs from automated runs. We've used primitive threeJS geometries as fallback. Super tough time working with agora because theres no straightforward way use agora's framework for tool calls required by our application. We had to write custom code to address the gap.
Accomplishments that we're proud of
- End-to-end patent → 3D pipeline in 36 hours: Upload a real patent PDF and get an auto-reviewed component library with realistic images, assembly context, and Trellis 2 GLB meshes.
- Circumvented Agora's tool-call gap. Built custom infrastructure to make a voice AI agent that can trigger real-time 3D animations mid-speech.
- Synchronized AI voice + 3D animation: The learning studio delivers lessons where an AI teacher's voice and 3D model animations are tightly coupled, creating an experience that feels like a real instructor pointing at a physical model.
- Multi-sponsor integration: fal.ai, ElevenLabs, OpenRouter, Agora — all working together in a coherent product.
- Robust offline fallback: Every AI-powered feature degrades gracefully — search falls back to keyword heuristics, chat gives a baseline response — so the demo never breaks without API keys.
What we learned
- Vision models are surprisingly capable on patent drawings — despite the low quality of many patent figures, Gemini's vision could reliably identify component labels, assembly relationships, and figure types with a well-crafted prompt.
- Multi-modal orchestration requires careful state management — coordinating voice, 3D state, AI responses, and quiz state across a single session taught us to be disciplined about a single source of truth per concern (audio controller owns timing, 3D controller owns mesh state, etc.).
What's next for Invertra
- Better models, better meshes. Upgrading the pipeline with stronger LLMs and text-to-3D capabilities to reduce the fragility we fought during the hackathon.
- Spatial intelligence for the teacher agent. Right now the agent infers which tool to call from context. We want it to genuinely understand the 3D object — its geometry, its parts, their relationships. We're exploring GaussianVLM as a path toward that.
Built With
- agora
- cesium
- elevenlabs
- fal.ai
- nanobanana
- nextjs
- openrouter
- three.js
- tinyfish
- vercel



Log in or sign up for Devpost to join the conversation.