-
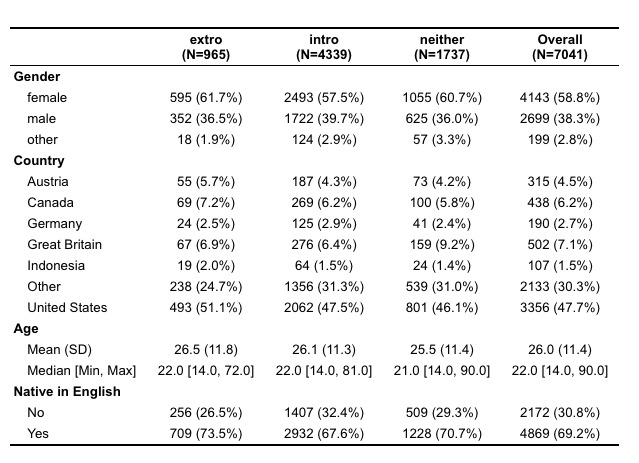
Initial observation of data
-
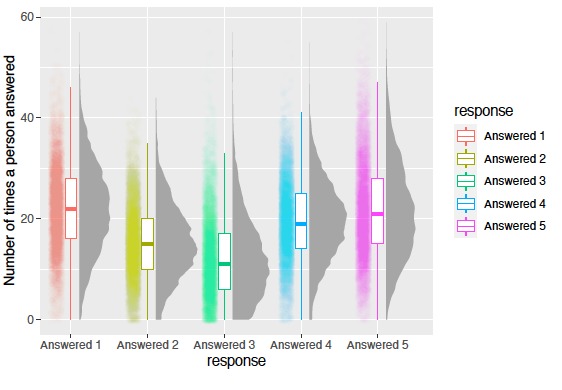
Distribution of results
-
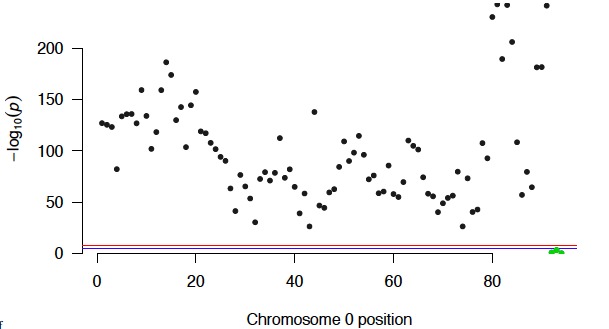
Manhattan plot for validity of questions
-
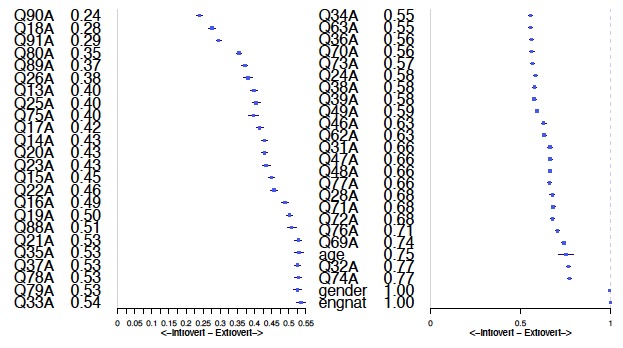
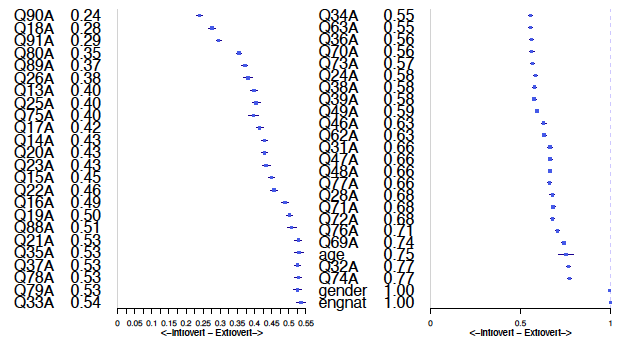
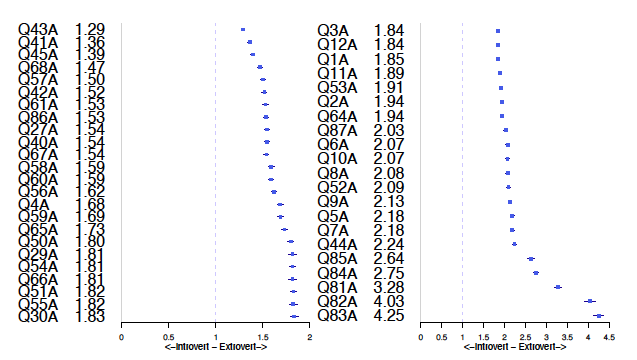
Odds ratios for each question -1
-
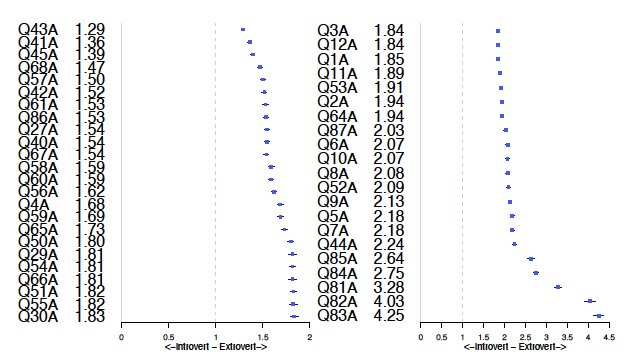
Odds ratios for each question -1
-
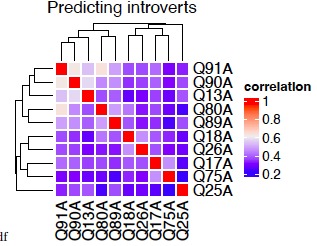
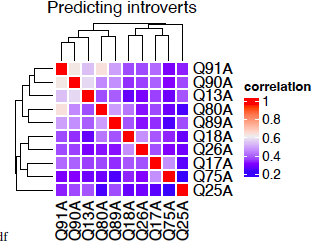
Main questions determining intro - Correlation
-
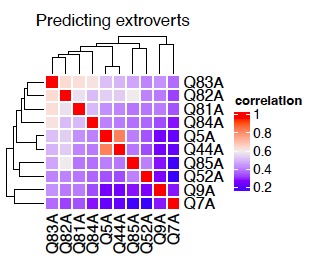
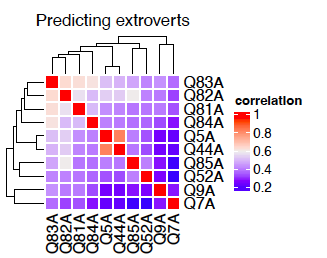
Main questions determining extro - Correlation
-
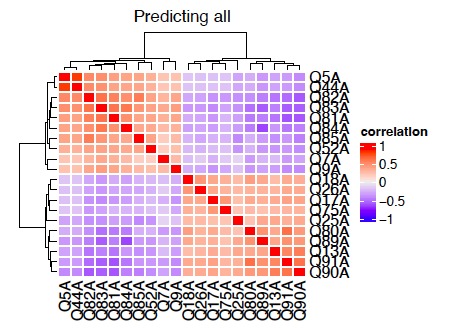
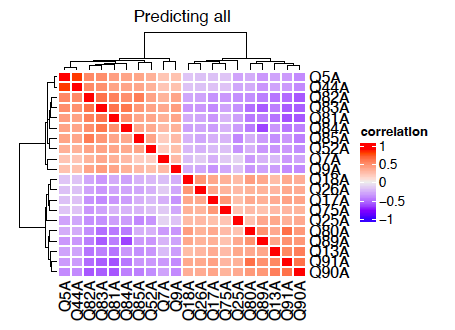
Main questions - Correlation
-
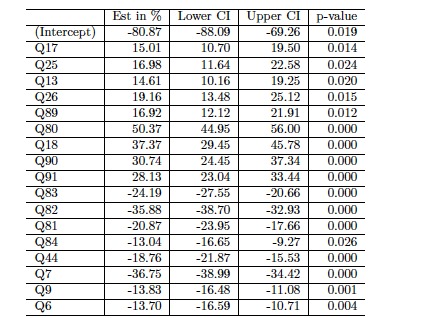
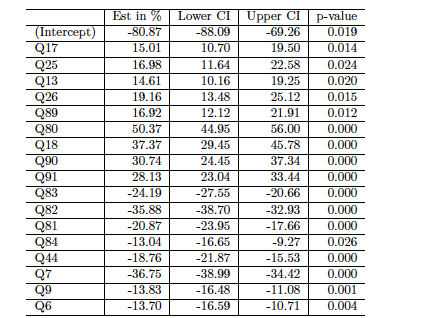
Results for final model
-

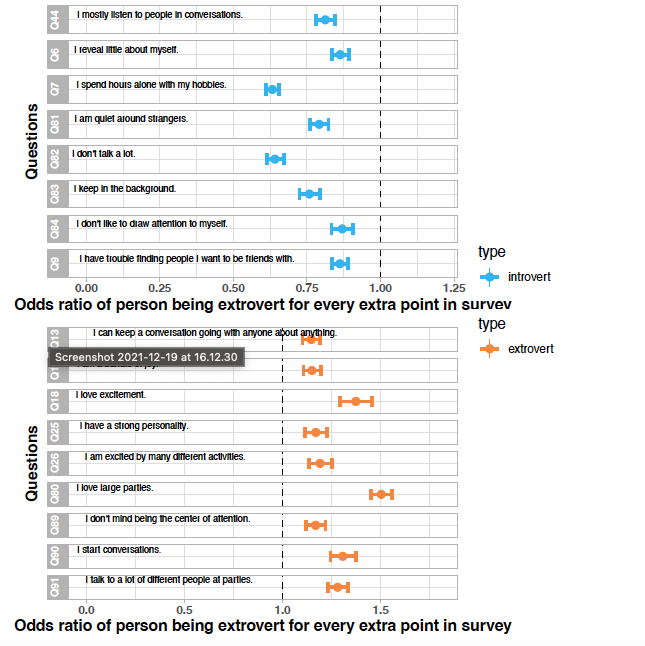
Odds ratio looking at the final model
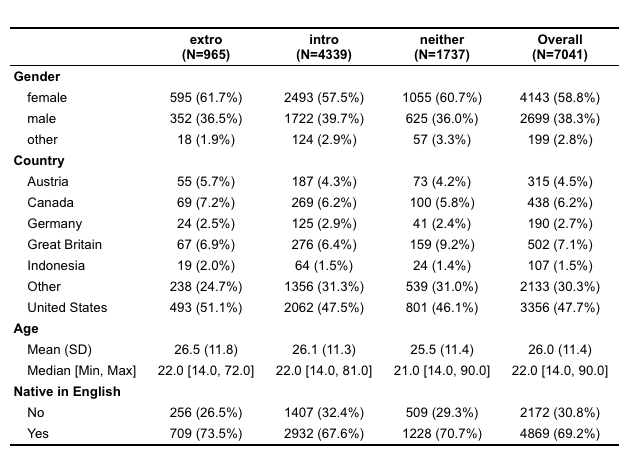
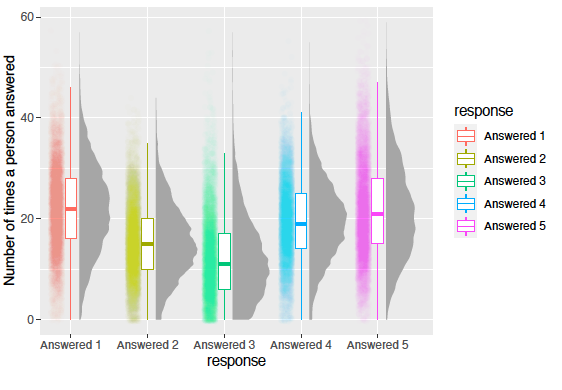
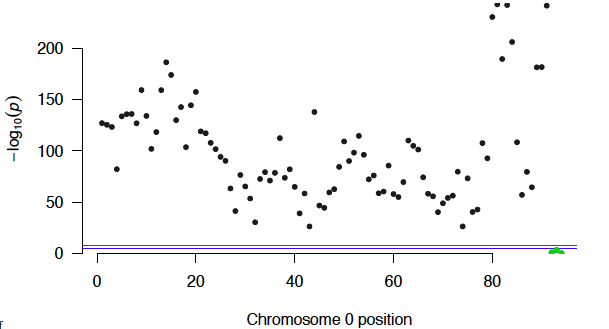
See pfd on github for the full project breakdown
Inspiration
The dataset has been a great fun to play with bringing with itself quite a lot of challenges as well as interesting ways to interrogate it.
What it does
Investigate the key variables and hopefully provide a clear overview of dataset and predictor model
How we built it
R markdown all the way
Challenges we ran into
Adapting plots and trying to shape the dataset into a malleable fashion, taking in to account there are 100 key variables .
Accomplishments that we're proud of
Techniques developed and the short time of production

Log in or sign up for Devpost to join the conversation.