
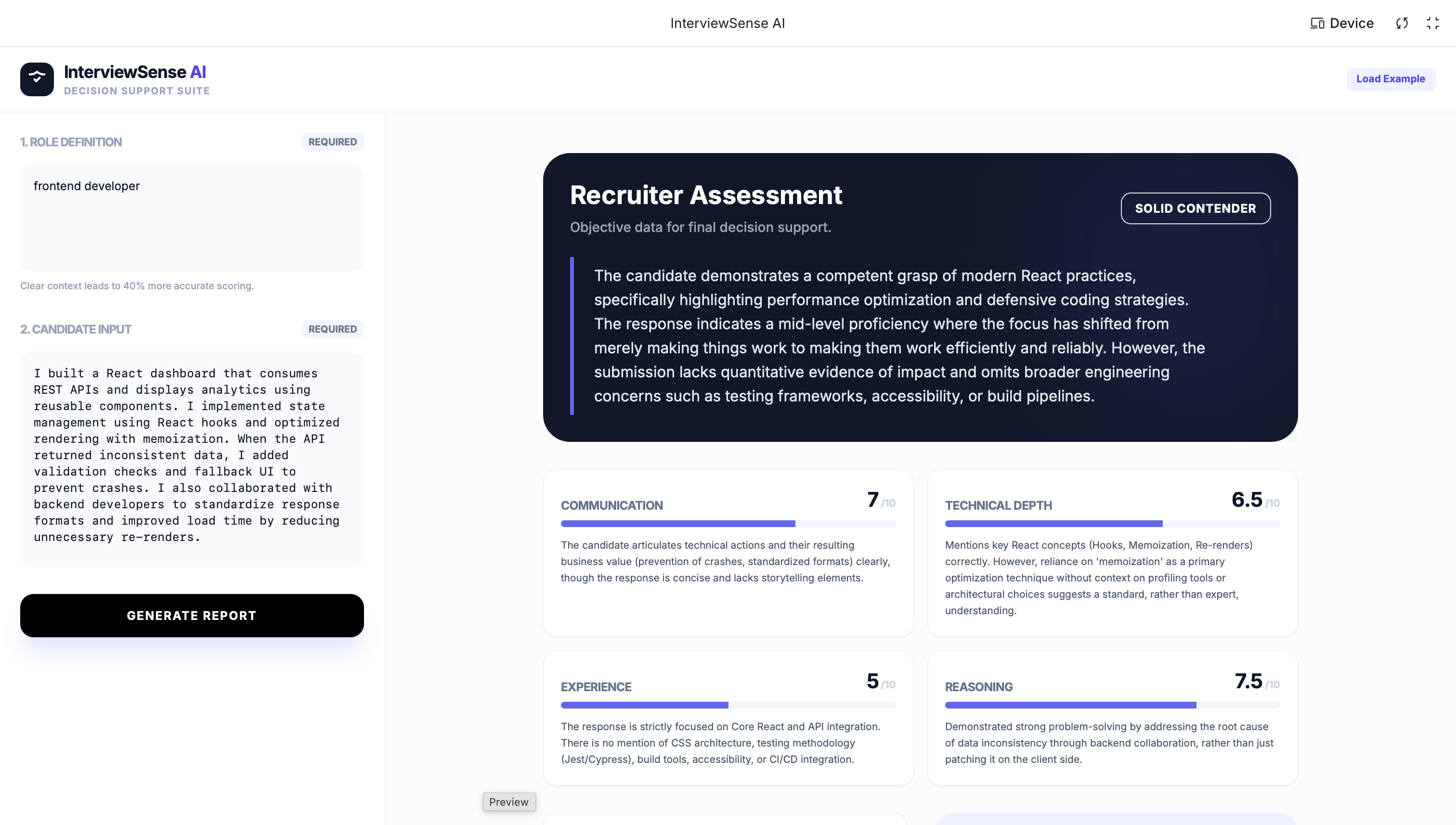
The Problem Recruiters review hundreds of written interview answers and resumes during the initial screening stage. The difficult part is not reading them, but evaluating them consistently. Candidates often use confident wording and buzzwords that appear impressive but lack real technical understanding. At the same time, good candidates sometimes undersell their work and get filtered out early. This leads to subjective decisions, inconsistent screening, and significant time spent analyzing responses manually. The Idea We built InterviewSense AI, a recruiter decision-support assistant that converts a candidate’s written response into a structured hiring evaluation. Instead of summarizing text, the system analyzes how the candidate thinks — whether they explain reasoning, provide evidence, and demonstrate real understanding. The goal is not to replace recruiters, but to help them make faster and fairer decisions.
How It Works
The recruiter provides: Role definition Candidate written answer or resume text Using the Gemini reasoning model, the system evaluates the response and produces: Role understanding Communication clarity score Technical clarity score Confidence level Strengths and weaknesses Risk factors and red flags Hiring signal AI-generated follow-up interview questions The structured format allows recruiters to compare candidates objectively instead of relying on intuition.
What Makes It Different Most AI tools summarize resumes. InterviewSense AI performs judgment-style evaluation.
The model detects:
vague claims like “improved performance” missing metrics buzzword-only answers real problem-solving explanations This simulates how experienced recruiters read between the lines. How We Built It The project was built using Google AI Studio with the Gemini 3 reasoning model. We designed a structured prompt that forces the model to behave like a recruiter and produce consistent evaluation categories rather than free-form text.
The interface allows users to paste responses and instantly receive an explainable assessment.
Challenges We Faced The main challenge was preventing the model from giving generic praise. Initially, outputs were descriptive but not evaluative. We solved this by:
forcing structured output format restricting assumptions requiring evidence for every score This significantly improved reliability and realism of the feedback. What We Learned We learned that large language models are most powerful not as chatbots, but as decision-support systems. By constraining outputs and defining evaluation criteria, AI can simulate expert reasoning instead of just generating text. Future Improvements Candidate comparison dashboard Bias detection indicators Integration with ATS platforms Interview preparation mode for students
Built With
- gemini-3
- google-ai-studio
- prompt-engineering
- structured-reasoning-after-this

Log in or sign up for Devpost to join the conversation.