
Table 37
Inspiration
Navigating the job market and preparing for interviews can be an incredibly tedious process. Endlessly searching for role-specific questions tailored to different company cultures and constantly asking friends to run mock interviews with me just wasn't scaling. At the same time, I’ve been fascinated by the recent leaps in AI voice agents. I wanted to see if I could build a tool that actually felt like a real, conversational interviewer—something that could not only speak to me in real-time but also provide the objective, structured feedback I needed to improve.
What it does
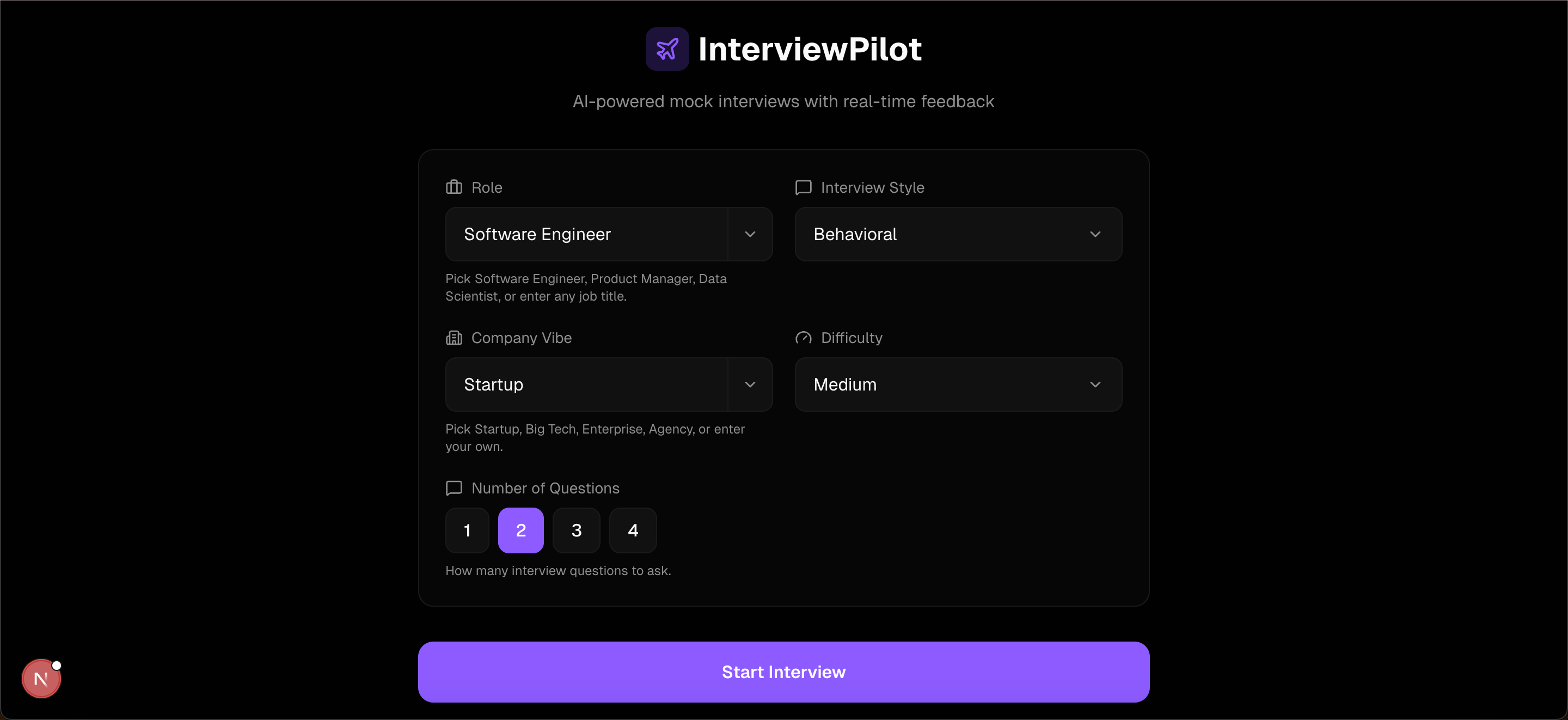
InterviewPilot is an AI-powered mock interview coach that runs entirely in the browser. You configure your target role (whether that's a Product Manager, Data Scientist, or any custom title), company vibe (e.g., Startup, Big Tech, Enterprise), interview style, and difficulty level.
Once configured, you jump into a live, voice-to-voice conversation with a Gemini AI interviewer. While you speak, the app simultaneously tracks your eye contact via your webcam and counts your filler words from a live transcript. When the session wraps up, you receive a deterministic, structured grading report with a confidence score, actionable strengths, and areas to improve—complete with on-demand "deep dive" practice drills for any identified weaknesses.
How I built it
The core innovation of InterviewPilot is its dual-channel architecture, designed to eliminate latency while maintaining strict data structures:
- Live Interview (Browser ↔ Gemini): To achieve a truly real-time conversational feel, the live voice session bypasses my backend entirely. The Next.js frontend opens a WebSocket directly to the Gemini Live API (
gemini-2.5-flash-native-audio-preview). I capture microphone audio, resample it to 16kHz, encode it as base64 PCM, and stream it to the model, while simultaneously decoding and queuing the model's audio chunks for gapless playback via the Web Audio API. - Structured Analysis (Browser ↔ FastAPI): For planning the interview, grading the performance, and generating deep dives, the frontend makes REST calls to a FastAPI Python backend. This backend uses
gemini-2.5-flash-litewith structured JSON output enforced by Pydantic schemas, guaranteeing that the UI always receives exactly the data shapes it expects.
For the live presence tracking, I integrated @mediapipe/tasks-vision. It downloads a lightweight WASM model to the browser and runs a throttled inference loop (every 200ms) on a 478-point face mesh to calculate head pitch, yaw, and an eye contact score.
The math for the eye contact score is calculated client-side by measuring the offset of the iris center relative to the eye bounding box:
$$\text{eyeContact} = \text{clamp}(1 - \text{avgOffset} \times 2, 0, 1)$$
Challenges I ran into
Managing the raw audio pipelines natively in the browser was the biggest hurdle. Converting Web Audio API float samples to 16-bit signed PCM, handling the linear decimation down to 16kHz for Gemini, and then reversing the process to schedule seamless playback without popping or audio gaps required a lot of trial and error.
Additionally, managing the Gemini Live API's tool calling over a native-audio stream was tricky. I had to build a specific systemInstruction script to force the model to call an end_interview() function when it was done, and implement a fallback transcript-parsing heuristic just in case the tool call dropped.
Accomplishments that I'm proud of
I am incredibly proud of achieving a genuinely real-time, voice-to-voice feel. By cutting out the backend proxy for the audio stream, the conversation flows naturally. I'm also proud of successfully integrating heavy WASM-based face tracking running concurrently with a live WebSocket audio stream without dropping frames or ruining the user experience.
What I learned
This project was a massive deep dive into the Web Audio API—specifically working with ScriptProcessorNode and AudioBufferSourceNode. I also learned how to effectively manage highly complex, multi-modal asynchronous states in React 19, coordinating a live WebSocket, a webcam feed, and UI transitions simultaneously.
What's next for InterviewPilot
Right now, the filler word counting and WPM calculations are done client-side, and the backend SpeechService is a stub. The immediate next step is to build out the server-side NLP analysis from the full transcript to generate highly accurate, per-question speech breakdowns. After that, I plan to add a database persistence layer so users can track their longitudinal improvement and compare scores across different interview attempts.
How we built it
Challenges we ran into
Accomplishments that we're proud of
What we learned
What's next for InterviewPilot
Built With
- and
- api
- api)
- audio
- css
- fastapi
- gemini
- live
- mediapipe
- next.js
- pydantic
- python
- react
- structured
- tailwind
- typescript
- uvicorn
- web
- websockets
- zod

Log in or sign up for Devpost to join the conversation.