-
-
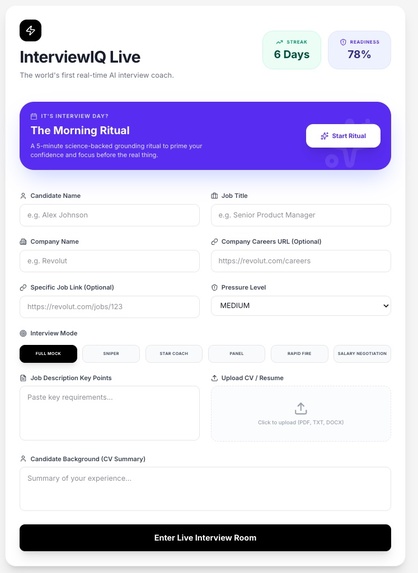
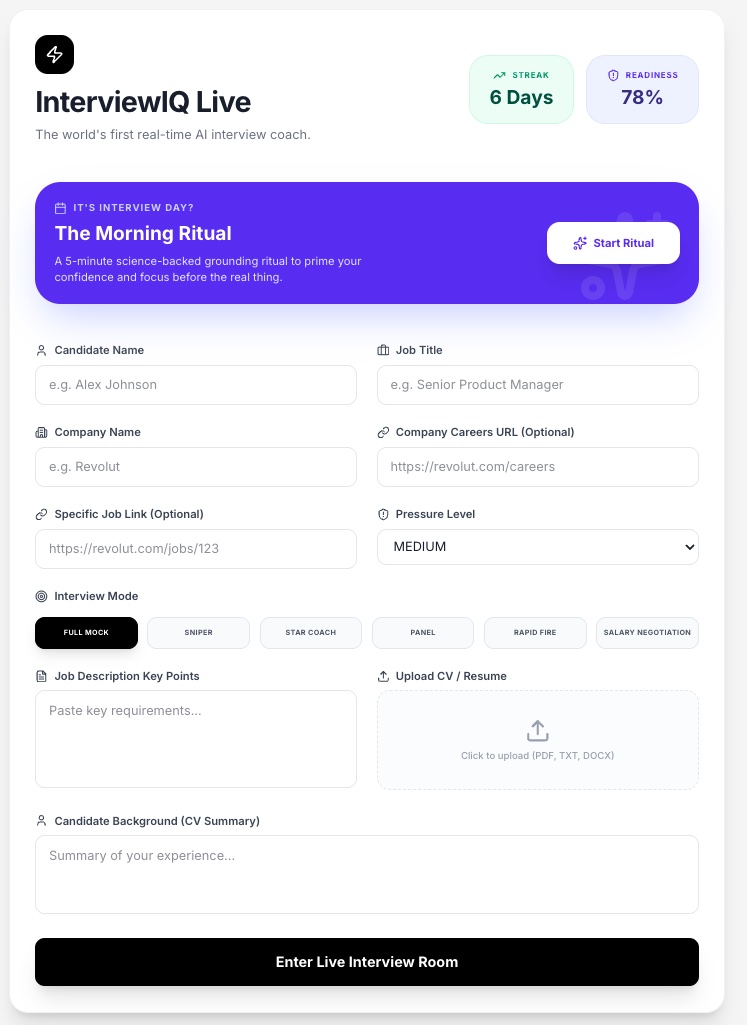
InterviewIQ - setup screen choose your interview mode, upload your CV, paste the JD, and enter the live AI coaching room in seconds.
-
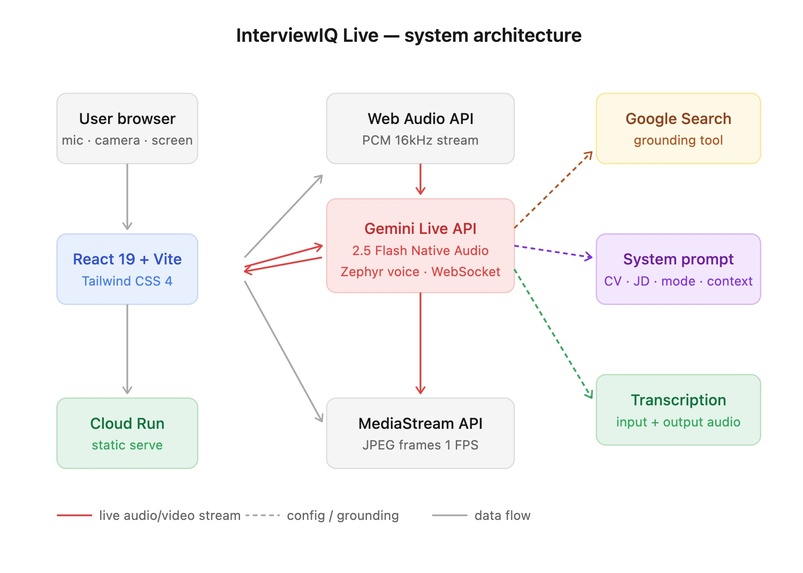
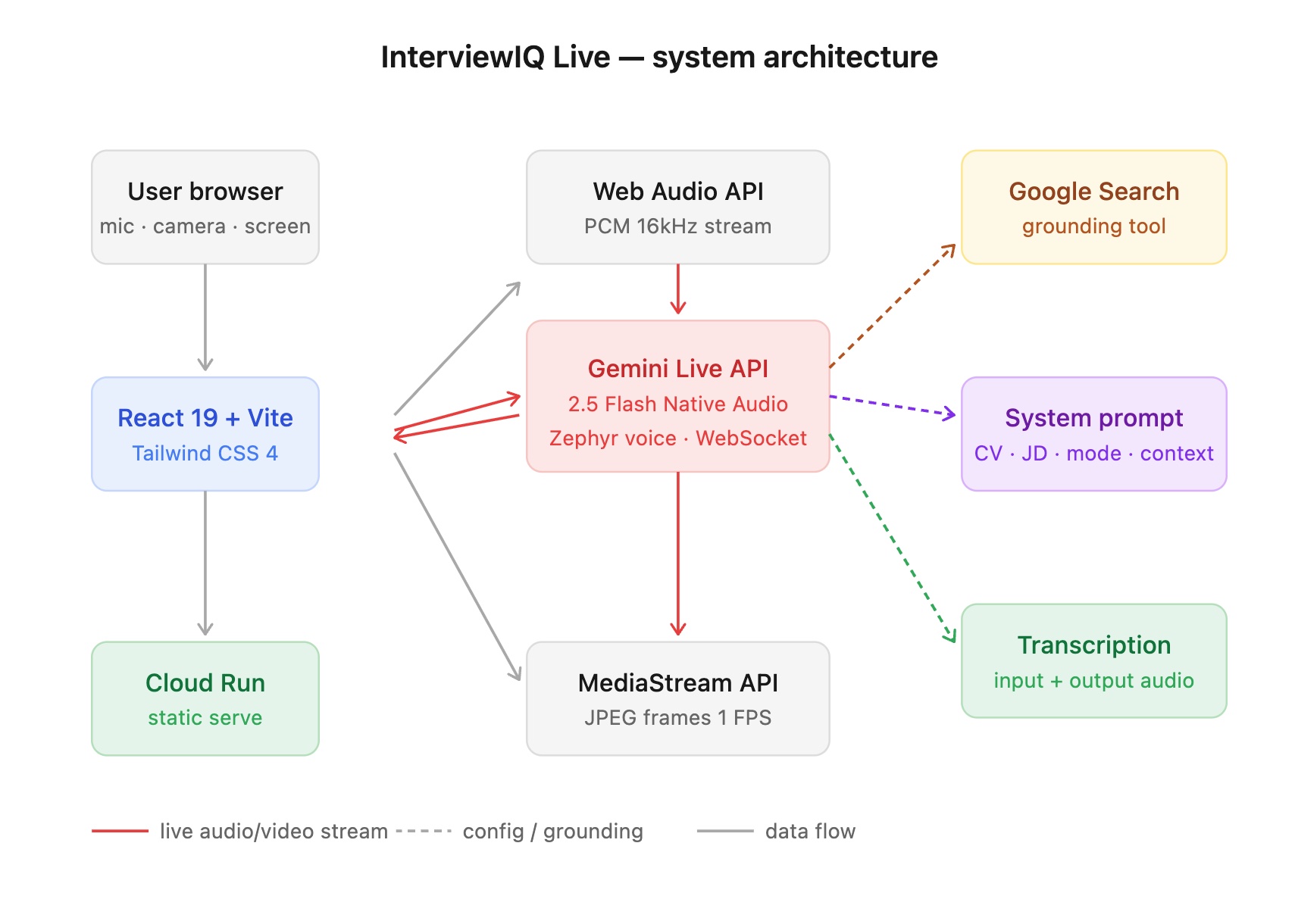
Architecture diagram
Inspiration
Every year, over 200 million people globally go through job interviews. Most of them fail — not because they weren't qualified, but because they never practiced out loud. Not once.
The tools that exist today are broken in a fundamental way. Mock interview apps give you text questions and text feedback. YouTube videos show you what good answers look like — but never coach your answers. Career coaches cost £200+ per session and aren't available at 11pm the night before your interview.
The result? Candidates walk into the most important conversations of their careers having never actually spoken their answers out loud under real pressure.
The moment we discovered the Gemini Live API — with its ability to hear your voice in real time, see your CV, detect emotion, and respond conversationally with natural interruptions — we knew this was the technology that could finally make interview practice feel like the real thing.
"85% of candidates fail interviews they were qualified for — not because of knowledge gaps, but because they never practiced speaking under pressure."
We built InterviewIQ to fix that. For everyone.
What it does
InterviewIQ is a voice-first AI interview coach powered by Gemini Live API. It covers the complete candidate journey — from CV upload to signed offer — across 7 distinct modes:
- 🎤 Live Voice Interview with real-time interruption handling
- 👁️ Vision Mode — CV & JD gap analysis before the session begins
- 😰 Emotion & Stress Detection from vocal patterns
- 🔍 Live Grounding — real company intelligence via Google Search
- 🎭 Panel Mode — three distinct AI personas (Alex, Jordan, Sam)
- ☀️ Morning Ritual — 5-minute pre-interview confidence warmup
- 💰 Salary Negotiation Simulator with Morgan the AI recruiter
How we built it
InterviewIQ runs on a WebSocket-first architecture enabling real-time bidirectional audio streaming.
| Layer | Technology |
|---|---|
| AI Model | Gemini 2.5 Flash Native Audio (Live API) |
| Frontend | React 19 + Vite + Tailwind CSS 4 |
| Voice | Zephyr prebuilt voice |
| Vision | Webcam + screen share at 1 FPS |
| Hosting | Google Cloud Run |
Every session runs through three phases:
- SESSION_INIT — Load CV + JD, run gap analysis, execute Google Search grounding for company intel, build personalised system prompt
- LIVE_SESSION — Open Gemini Live WebSocket, stream audio bidirectionally, monitor for rambling triggers, apply interruption taxonomy across 5 interruption types
- POST_SESSION — Score answers, extract highlights, generate next session recommendations
Challenges we ran into
Real-Time Interruption Handling — Making interruptions feel natural required building a full 5-type taxonomy (self-correction, clarifying question, panic signal, addition, genuine disagreement) with distinct response paths for each. Getting this to feel human rather than robotic took significant iteration.
Anti-Hallucination in a Live Grounded Context — When the agent researches a company in real time, there is real risk of confidently stating incorrect facts. Enforcing the grounding protocol reliably required explicit override rules at the system prompt level.
Multi-Persona Voice Differentiation — Making Alex, Jordan, and Sam sound genuinely distinct required building vocal fingerprints — sentence length, signature phrases, challenge style, and dynamic relationships between the three personas, not just with the candidate.
Emotion Detection Without Biometrics — Without biometric data, emotion had to be inferred entirely from speech patterns — pace, filler words, trailing sentences, self-corrections, and silence duration.
Accomplishments that we're proud of
🏆 Panel Mode — When Jordan cuts across Alex mid-session and Sam responds with a single "And?" to a weak answer, it feels like a real panel. That moment made us realise what multimodal AI can actually do.
🎯 The Gap Analysis Briefing — Watching the agent read a CV and JD simultaneously, identify real gaps, and deliver a 90-second strategic briefing before a single question is asked.
💪 The Morning Ritual — A guided 5-stage confidence warmup that ends with a send-off, not a scorecard. The most human moment in the product.
⚡ Zero-Latency Interruption — The agent stops mid-sentence, identifies why the candidate interrupted, and responds appropriately — in real time.
What we learned
Agent design is behaviour design, not prompt design. The happy path is easy. The interruptions, the silences, the rambling answers, the emotional moments — that is where an agent either feels human or reveals itself as a chatbot.
Multimodal is multiplicative, not additive. Vision + voice together creates experiences that neither modality can achieve alone.
Grounding is the difference between a demo and a product. An agent that makes up company facts is actively harmful to a candidate preparing for a real interview.
The real problem is human, not technical. People don't fail interviews because they don't know the answers. They fail because they've never said the answers out loud, under pressure, to someone who pushes back.
What's next for InterviewIQ
- 📱 Mobile App — Practice on the commute to the real interview
- 🧠 Interview Intelligence — Aggregate patterns across sessions to surface what answers actually correlate with job offers
- 🏢 Company-Specific Training Packs — Partner with employers to train candidates for their specific interview process
- 🎓 University & Bootcamp Partnerships — Default interview prep tool for every career service department
- 🔗 Platform Integrations — Embed directly into LinkedIn and Indeed so candidates practice the moment they apply
- 🌍 Multilingual Support — Extend to candidates interviewing in their second language
Built With
- gemini2.5flashnativeaudio
- google-genai-sdk
- googlecloudbuild
- googlecloudrun
- googlegeminiliveapi
- mediastreamapi
- node.js
- react
- tailwindcss
- typescript
- vite
- webaudioapi
- websocket
Log in or sign up for Devpost to join the conversation.