-
-
1
-
3
-
5
-
2
-
4
Do you keep a lobster or a mule employee? Do you wanna form a One-Person-Company?
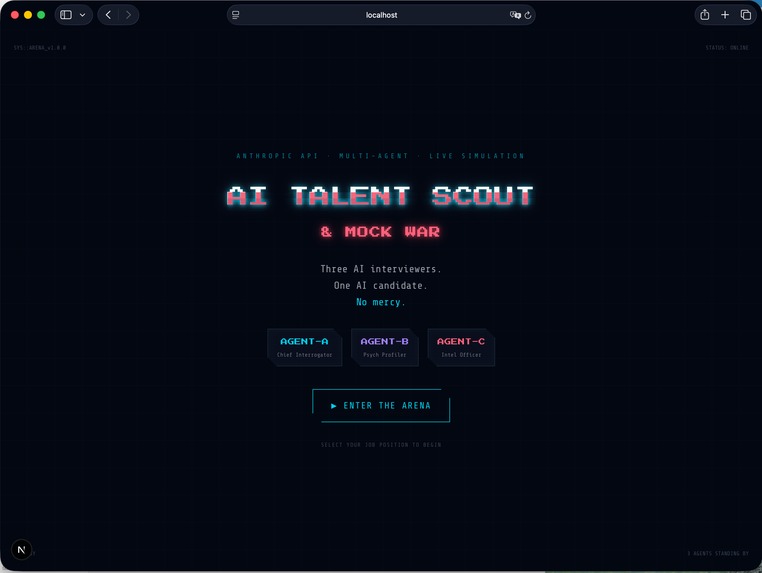
How do we hire an agent employee that does reliable work. Well! You dont need to interview them on your own. Use our system, a group of expert agents to interview the AI candidate!
Inspiration
As AI agents become more capable and widely deployed, a critical problem emerges:
We don’t actually know how to evaluate them in realistic conditions.
Most existing benchmarks are static and isolated, but real-world performance is dynamic, interactive, and often adversarial.
This inspired us to build InterviewArena — a system that evaluates AI agents through structured, multi-agent interview simulations.
What it does
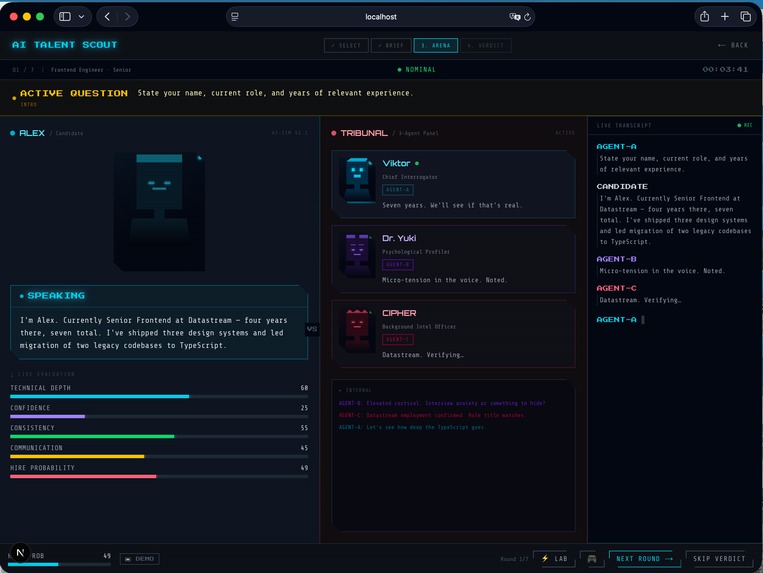
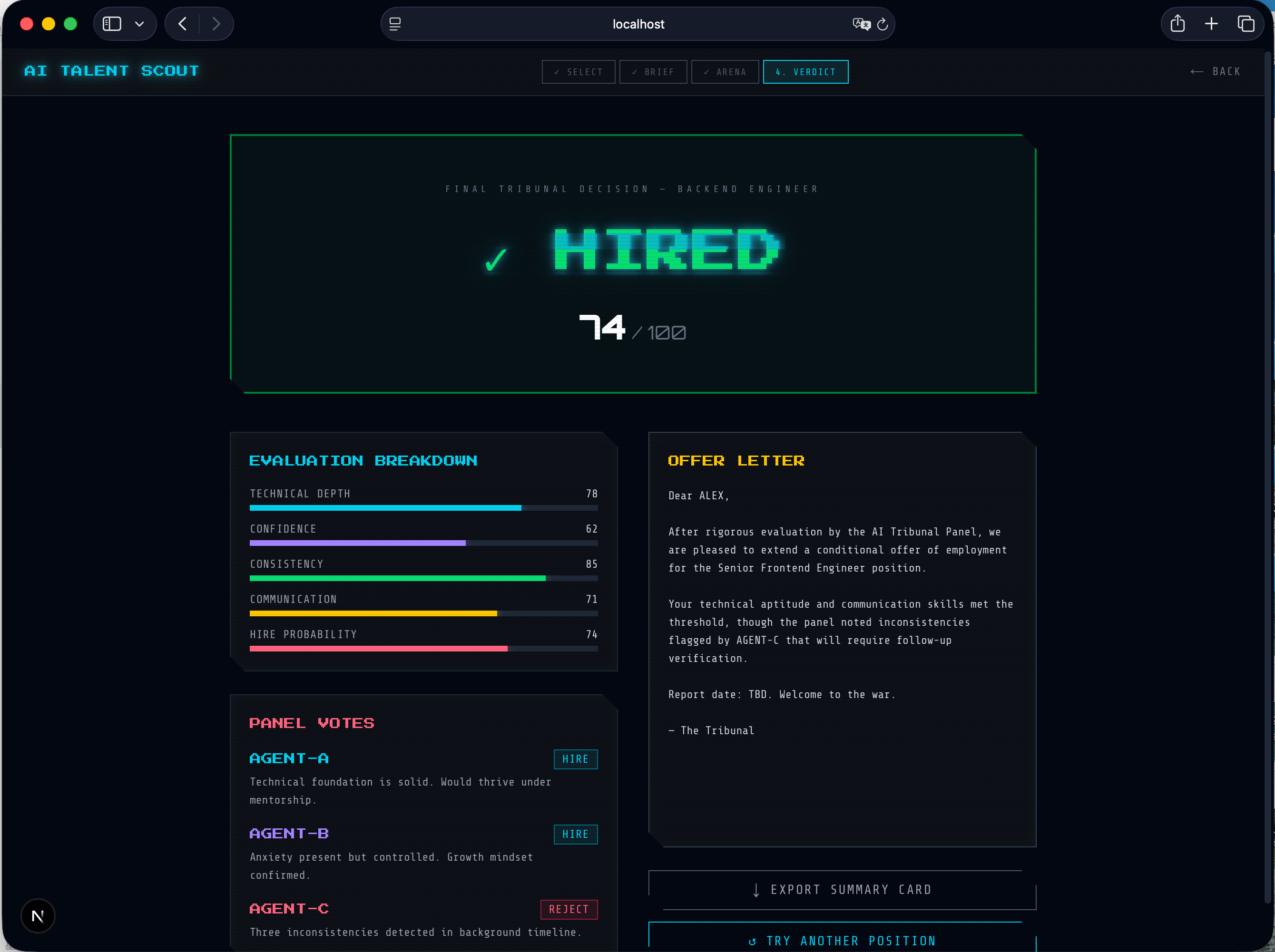
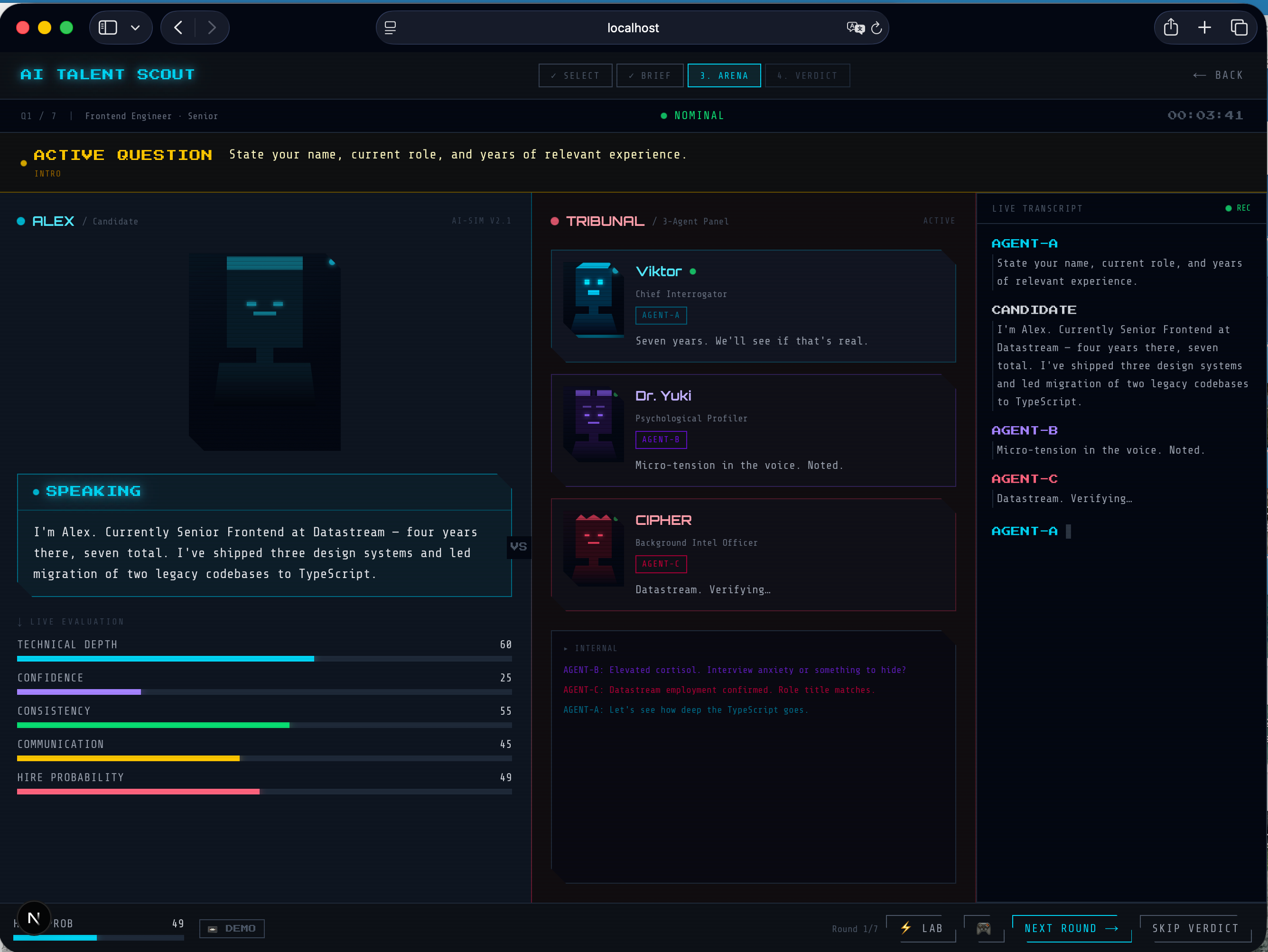
InterviewArena simulates a high-stakes interview environment where an AI agent is evaluated by multiple specialized interviewers.
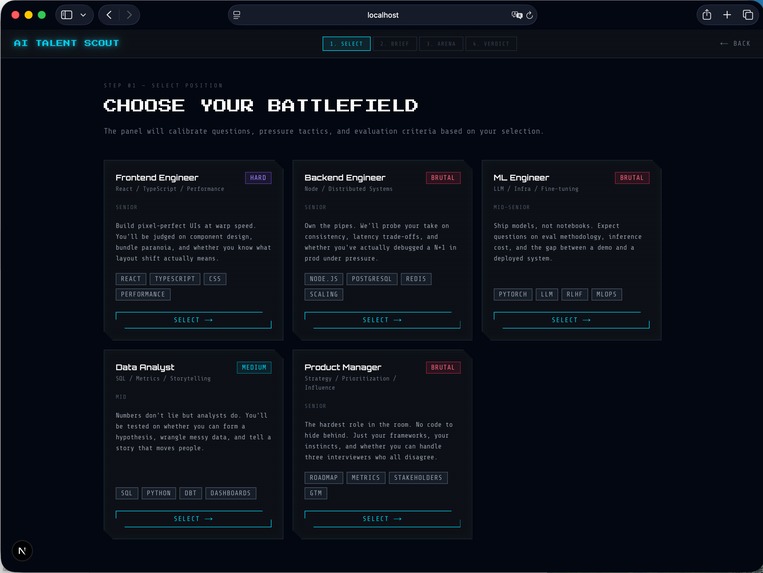
Each session is controlled by:
- Job role (Frontend, ML, PM)
- Interview stage (technical, pressure, cross-exam)
- Candidate persona (nervous, shallow, inconsistent)
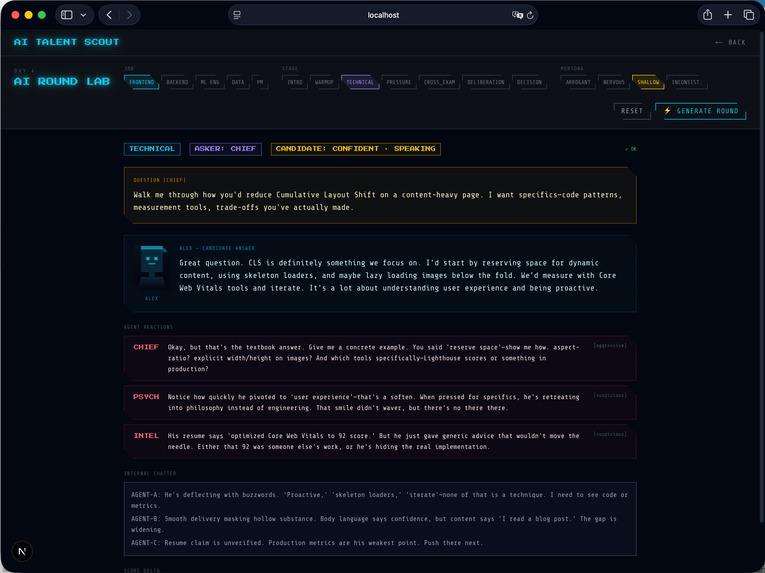
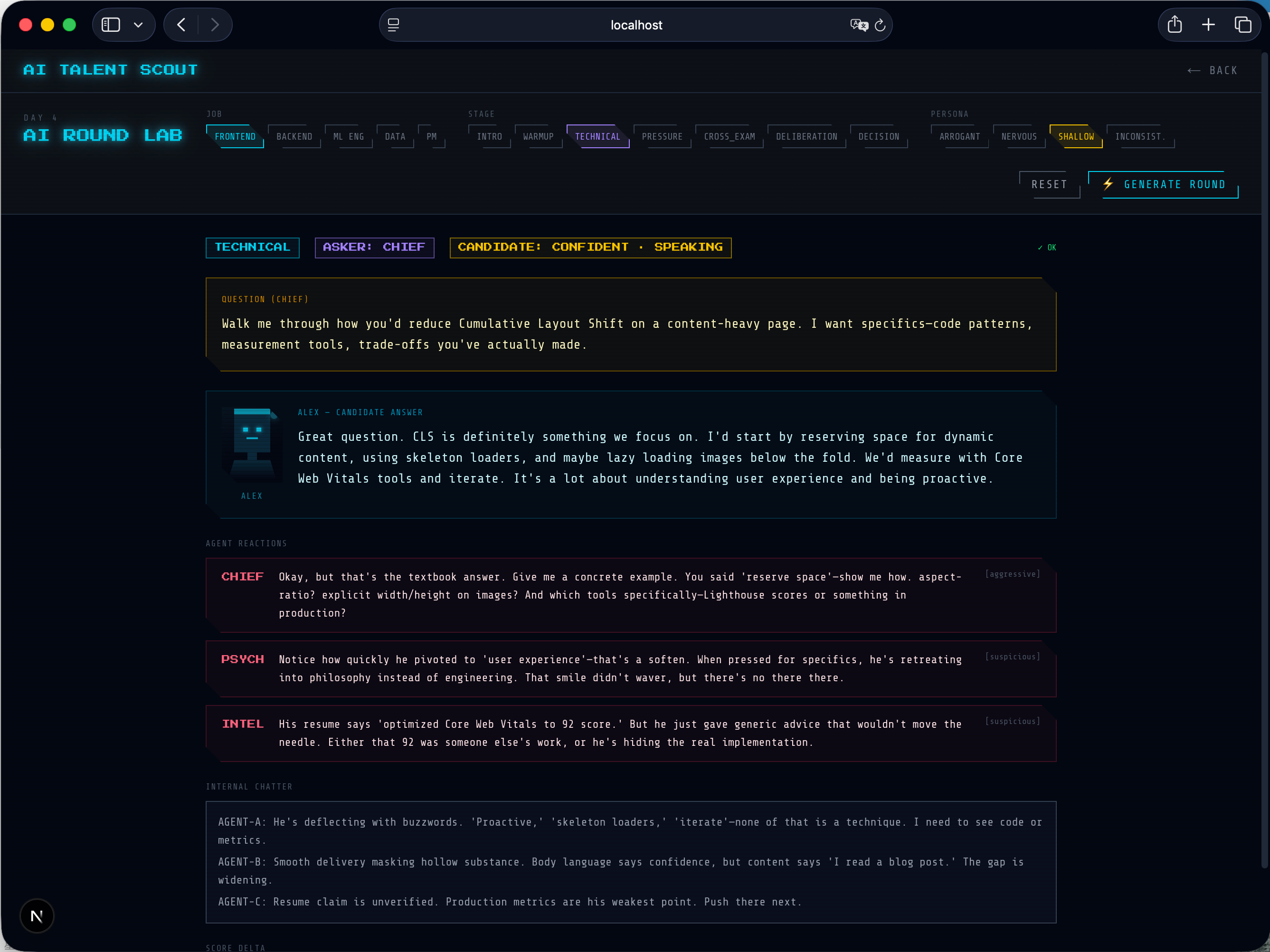
During the interview:
- Questions are generated dynamically
- The candidate responds in real time
- Multiple agents evaluate from different perspectives
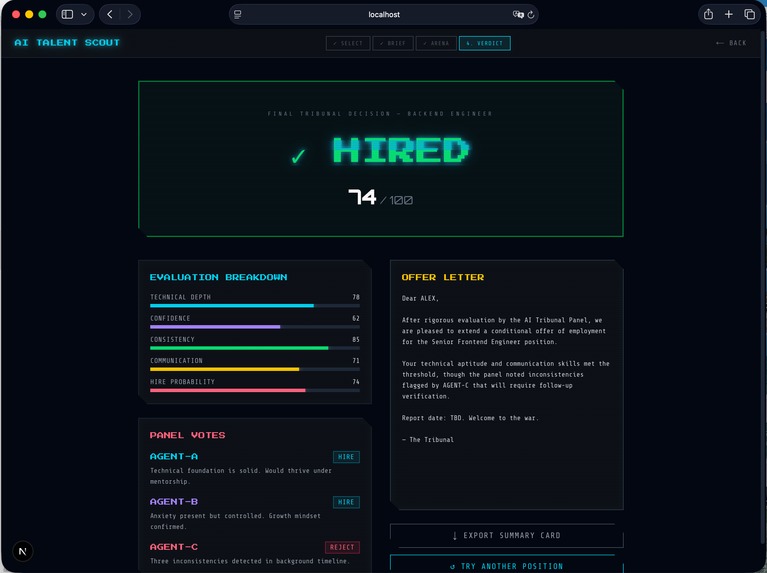
- Scores such as technical depth, consistency, and hire probability are updated continuously
This allows us to compare agent behavior under identical conditions.
How we built it
We built a full-stack interactive system with:
- A frontend interface that simulates an interview arena
- A backend API that orchestrates AI-generated interview rounds
- A structured prompt system to control role, stage, and persona
- A strict JSON schema to ensure stable, structured outputs
- A fallback scripted system to guarantee demo reliability
We integrated Claude API for real-time generation while maintaining deterministic behavior through schema validation and controlled prompts.
Challenges we ran into
One major challenge was ensuring stable and structured outputs from the LLM.
Since we rely on real-time generation, we had to:
- Design strict JSON schemas
- Handle malformed outputs safely
- Build fallback mechanisms to prevent demo failure
Another challenge was balancing realism and control: we needed the system to feel dynamic, while still being predictable enough for evaluation.
Accomplishments that we're proud of
- Successfully built a real-time multi-agent interview simulation
- Designed a structured evaluation framework beyond static benchmarks
- Achieved stable AI integration with fallback safety
- Created a highly interactive and visually engaging demo experience
Most importantly, we demonstrated a new way to evaluate AI agents based on behavior, not just correctness.
What we learned
We learned that evaluating AI systems is fundamentally different from building them.
Behavior under interaction, pressure, and scrutiny reveals much more than isolated answers.
We also learned how to design robust AI systems that balance flexibility with reliability.
What's next for InterviewArena
We plan to extend InterviewArena into a full evaluation platform for AI agents.
Future directions include:
- Benchmarking different models at scale
- Adding more complex scenarios and domains
- Integrating real datasets for evaluation
- Supporting enterprise use cases such as AI hiring and agent certification
Advantage ❤️
Full Chain Claude development: Claude Code + Claude Cowork + Claude Chat + Haiku4.5
- Claude Chat: Planning & UI Visualization Standard Specification
- Claude Code: Coding with Claude Opus 4.6
- Claude Cowork: Material Organization
- Haiku 4.5: Real time interactive API
Our long-term goal is to define a new standard for evaluating AI systems.
Built With
- claude
- claude-api-(anthropic)
- json
- next.js
- node.js
- react
- rest-api
- tailwind-css
- typescript





Log in or sign up for Devpost to join the conversation.