-
-
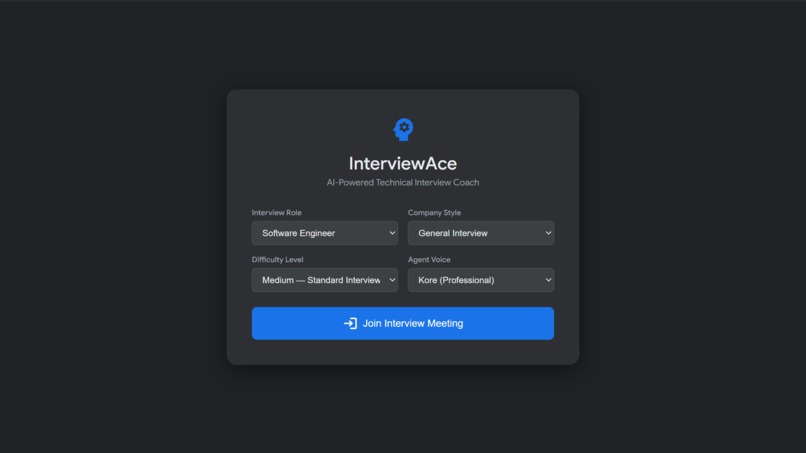
Initial Interview Selection page
-
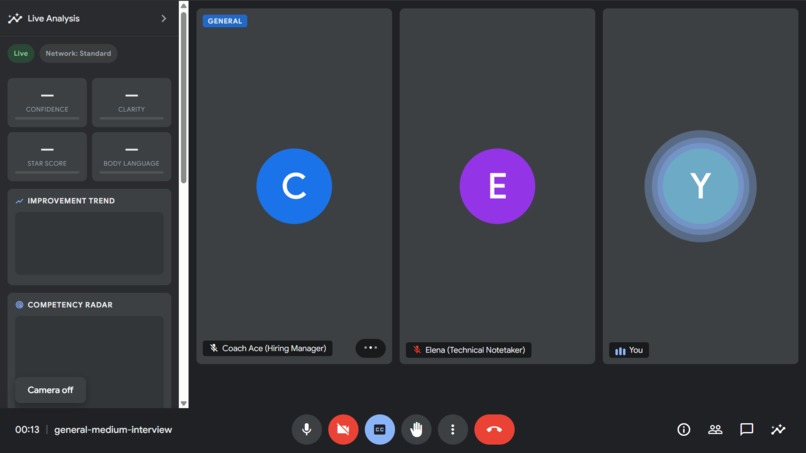
Initial Google Meet Inspired UI
-
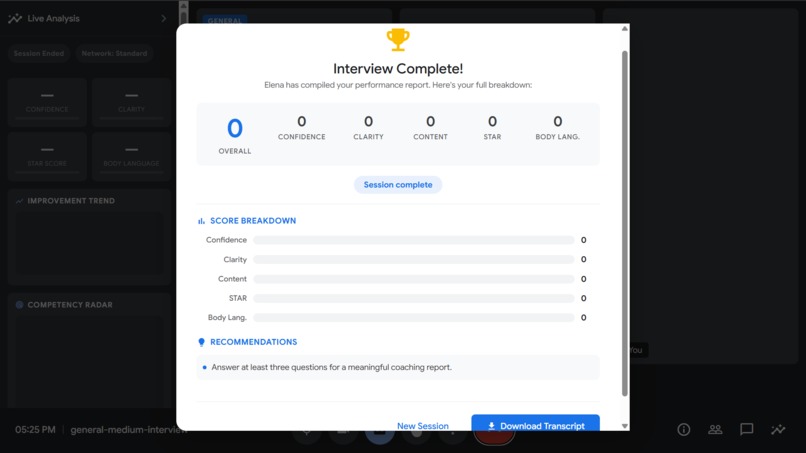
Initial Feedback section - Post Interview
Inspiration
Getting a job at a top tech company is one of the most competitive challenges a developer faces. Mock interview services charge $150–$300 per session — completely out of reach for most candidates, especially students. Existing AI tools are text-only chatbots that miss the entire non-verbal dimension of real interviews: your posture, your eye contact, whether you're saying "um" every five seconds, and whether your answers actually follow a coherent structure.
We wanted to build something that felt like sitting across from a real interviewer at Google — one who watches you, listens to you, and gives you honest feedback in real time. Not a chatbot. An actual live experience. The Gemini Live API made that possible for the first time.
What it does
InterviewAce is a real-time, multimodal AI interview coach that replicates a genuine Google Meet-style technical interview.
When you join a session, you're placed in a pixel-perfect Google Meet replica with "Coach Ace" — a senior AI hiring manager who:
- 🗣️ Speaks to you naturally via Gemini 2.5 Flash Native Audio with sub-500ms latency and natural barge-in support
- 👀 Watches your body language through your webcam — analysing posture, eye contact, facial expressions, and gestures in real time
- 🎤 Listens for filler words — "um", "uh", "like", "you know" — and tracks them with a live counter
- 📊 Scores your answers silently across Confidence, Clarity, Content, and STAR method structure
- 🏢 Adapts to company interview styles — Google, Amazon (Leadership Principles), Meta, Apple, Microsoft, Netflix, Airbnb, Stripe, and Uber
- 🔍 Uses Google Search grounding via ADK's built-in tool to give accurate, hallucination-free company-specific context
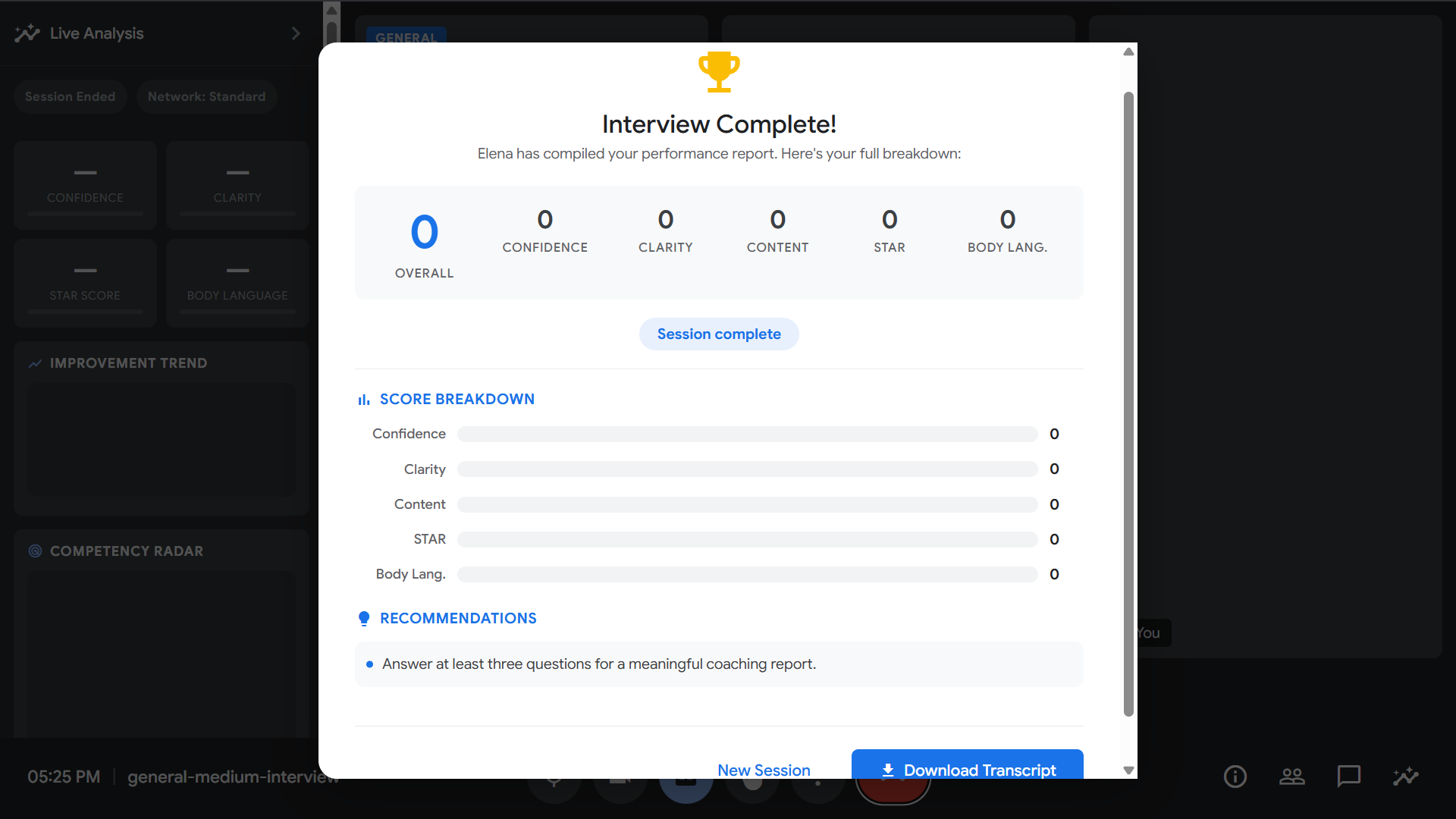
- 📝 Generates a full session report with a downloadable transcript and performance breakdown when the interview ends
The entire experience is voice-driven. No typing. No text boxes. Just a real conversation with an AI that actually watches and listens.
How we built it
InterviewAce is built on the official ADK bidirectional streaming pattern (LiveRequestQueue) for real-time voice + vision interaction.
Backend
- Google ADK orchestrates the entire agent pipeline.
Coach Aceis a single ADKAgentwith a carefully engineered persona: a senior hiring manager with 15 years at Google, Meta, Amazon, and Apple. - Gemini 2.5 Flash Native Audio powers real-time bidirectional audio streaming via the Live API (
bidiGenerateContent). - FastAPI + Uvicorn serve as the WebSocket server that bridges the browser to the ADK runner.
- 11 custom ADK tools across 3 tiers fire autonomously during the interview:
- Tier 1 (Core Analysis):
save_session_feedback,detect_filler_words,analyze_body_language,evaluate_star_method - Tier 2 (Deep Coaching):
analyze_voice_confidence,get_improvement_tips,fetch_grounding_data,adjust_difficulty_level - Tier 3 (Reporting):
get_session_history,save_session_recording,generate_session_report - Grounding: ADK's built-in
google_search
- Tier 1 (Core Analysis):
Frontend
- Vanilla JavaScript with no framework dependencies — keeping the bundle lightweight for low-latency streaming
- Web Audio API for PCM audio recording (16kHz) and real-time playback
- MediaDevices API for adaptive webcam frame capture (0.33–1 fps, bandwidth-adaptive)
- The UI is a pixel-perfect Google Meet replica with closed captions, live analytics sidebar, volume visualiser rings, equaliser bars, STAR method badges, a session timer, and a post-session feedback modal
Infrastructure
- Deployed on Google Cloud Run as a serverless container (Dockerfile +
cloudbuild.yaml) - Session state managed with ADK's
InMemorySessionService
Challenges we ran into
1. Real-time audio + vision synchronisation
Streaming PCM audio at 16kHz and JPEG frames simultaneously over a single WebSocket without dropped frames or audio glitches required careful flow control. We had to implement bandwidth-adaptive frame rate throttling (0.33–1 fps) and decouple audio and video queues inside LiveRequestQueue.
2. Agent interruption handling
When the user starts speaking mid-response, the agent must stop cleanly without corrupting the audio buffer. Implementing reliable barge-in support through the ADK streaming layer took multiple iterations and careful handling of interrupted turn signals.
3. Tool calling latency Background tools (filler word detection, body language analysis) need to feel invisible — the user should never notice a pause because the agent called a tool. We tuned tool invocation to happen silently between turns and stream analytics updates to the UI asynchronously via JSON side-channel messages over the same WebSocket.
4. Hallucination in company-specific contexts
Early versions of the agent would confidently make up interview question formats for specific companies. We solved this with a two-layer grounding strategy: a curated local knowledge base (grounding_data.py) for coaching facts, and ADK's built-in google_search for live company-specific verification.
5. Google Meet UI fidelity Building a pixel-perfect Meet replica in vanilla JS — with animated volume rings, equaliser bars, real-time caption overlays, and a live analytics sidebar — without any UI framework was a significant frontend engineering challenge.
Accomplishments that we're proud of
- ✅ True multimodal live agent — simultaneous PCM audio + webcam vision streamed to Gemini in real time, not turn-by-turn
- ✅ Sub-500ms voice response latency in production on Cloud Run
- ✅ 11 autonomously-invoked ADK tools that analyse the candidate silently without interrupting the conversation flow
- ✅ Zero hallucination on company facts — dual grounding eliminates fabricated interview question formats
- ✅ Natural barge-in support — the agent handles interruptions gracefully, exactly like a human interviewer would
- ✅ End-to-end deployment on Google Cloud Run with CI/CD via Cloud Build
- ✅ Accessibility — a full mock interview experience with no monetary barrier to entry ## What we learned
What we learned
- The ADK
LiveRequestQueuepattern is extremely powerful but requires careful queue management to avoid race conditions between audio, vision, and tool-call result streams. - Native audio models behave differently from text models — the latency profile, turn-taking mechanics, and interruption handling are fundamentally different and demand a completely different system design mindset.
- Grounding is not optional for agentic applications — without it, even capable models confidently hallucinate domain-specific facts. The two-layer grounding approach (local KB + live search) proved far more reliable than prompt engineering alone.
- Vanilla JS is underrated for latency-sensitive audio/video applications — frameworks add overhead that matters at the PCM level.
- Deploying a WebSocket-based application to Cloud Run requires
--session-affinityto ensure persistent connections aren't load-balanced mid-session.
What's next for InterviewAce
- 🔐 User authentication & persistent history — track progress across sessions with a full dashboard
- 📈 Trend analytics — visualise improvement in filler words, STAR scores, and confidence over time
- 🎯 Role-specific question banks — curated question sets for SWE, PM, Data Science, and Design roles
- 🤝 Peer mock interview mode — two users matched together with AI facilitation
- 📱 Mobile support — optimised PWA for on-the-go practice
- 🌐 Multi-language support — extend to non-English speakers leveraging Gemini's multilingual audio capabilities
- 🏆 Leaderboard & streaks — gamification layer to drive consistent practice habits ```
Built With
- cloud
- docker
- fastapi
- gemini-2.5-flash
- gemini-live-api
- google-adk
- google-cloud-run
- google-search-grounding
- mediadevices-api
- python
- uvicorn
- vanilla-javascript
- web-audio-api
- websockets


Log in or sign up for Devpost to join the conversation.