

Inspiration
Job interviews are a skill, and like any skill, you get better by doing them, not reading about them. But practice opportunities are scarce. You can't ask a friend to grill you on system design for an hour, and most "interview prep" tools are just glorified flashcard apps.
We wanted to build the thing we wished existed when we were preparing for interviews ourselves: something you could point at any job posting and immediately get a realistic, voice-based mock interview tailored to that specific role, followed by a brutally honest breakdown of how you did.
What We Learned
The most important thing we learned is that the quality of an AI interview lives or dies on context. Early prototypes asked generic questions and it felt pointless, like practicing with someone who hadn't read the job description. The moment we added enrichment (scraping the actual posting, pulling real interview questions from Glassdoor and Blind, extracting the tech stack and seniority level), the experience went from "toy demo" to something we'd actually use ourselves.
We also underestimated how much work goes into making a conversation feel natural when it's stitched together from APIs. Speech recognition, language models, and text-to-speech are three separate systems with different latencies, failure modes, and quirks. Stitching them into a fluid back-and-forth conversation where the AI's voice starts playing instantly, silence is detected gracefully, and page refreshes don't break everything was the real engineering challenge, not the AI itself.
Finally, we learned that constraining an LLM is harder than prompting one. Getting the model to ask good questions was easy. Getting it to stop talking after asking them, to resist the urge to add encouragement, commentary, or follow-ups, required multiple layers of guardrails we never anticipated.
How We Built It
interview.me is a TypeScript monorepo with a React 19 frontend and an Express 5 backend, deployed on DigitalOcean App Platform with a managed PostgreSQL database.
When a user pastes a job URL, the backend kicks off an enrichment pipeline: Jina Reader scrapes the posting for requirements and tech stack, Serper searches for real-world interview questions and company culture insights, and DigitalOcean Gradient AI (minimax-m2.5) synthesizes everything into a tailored interviewer persona and reference brief. A background phase continues enriching after the session starts, scraping additional sources and aggregating interview intel.
The interview itself is entirely voice-driven. ElevenLabs powers the interviewer's voice, streamed in real time through the browser's MediaSource API so audio begins playing the moment the first bytes arrive, no waiting for the full response. The candidate speaks through the Web Speech API, with custom silence detection and auto-restart logic to keep recognition alive. The frontend orchestrates the whole loop as a state machine: the AI speaks, listens, processes, and responds, turn after turn.
Behind the scenes, the backend manages the interview arc. Each turn gets injected guidance (warm-up → behavioral → technical → closing), a strict brevity constraint so the interviewer stays concise, and behavior detection that catches candidates going off-script: asking questions back, giving one-word answers, or trying to end early.
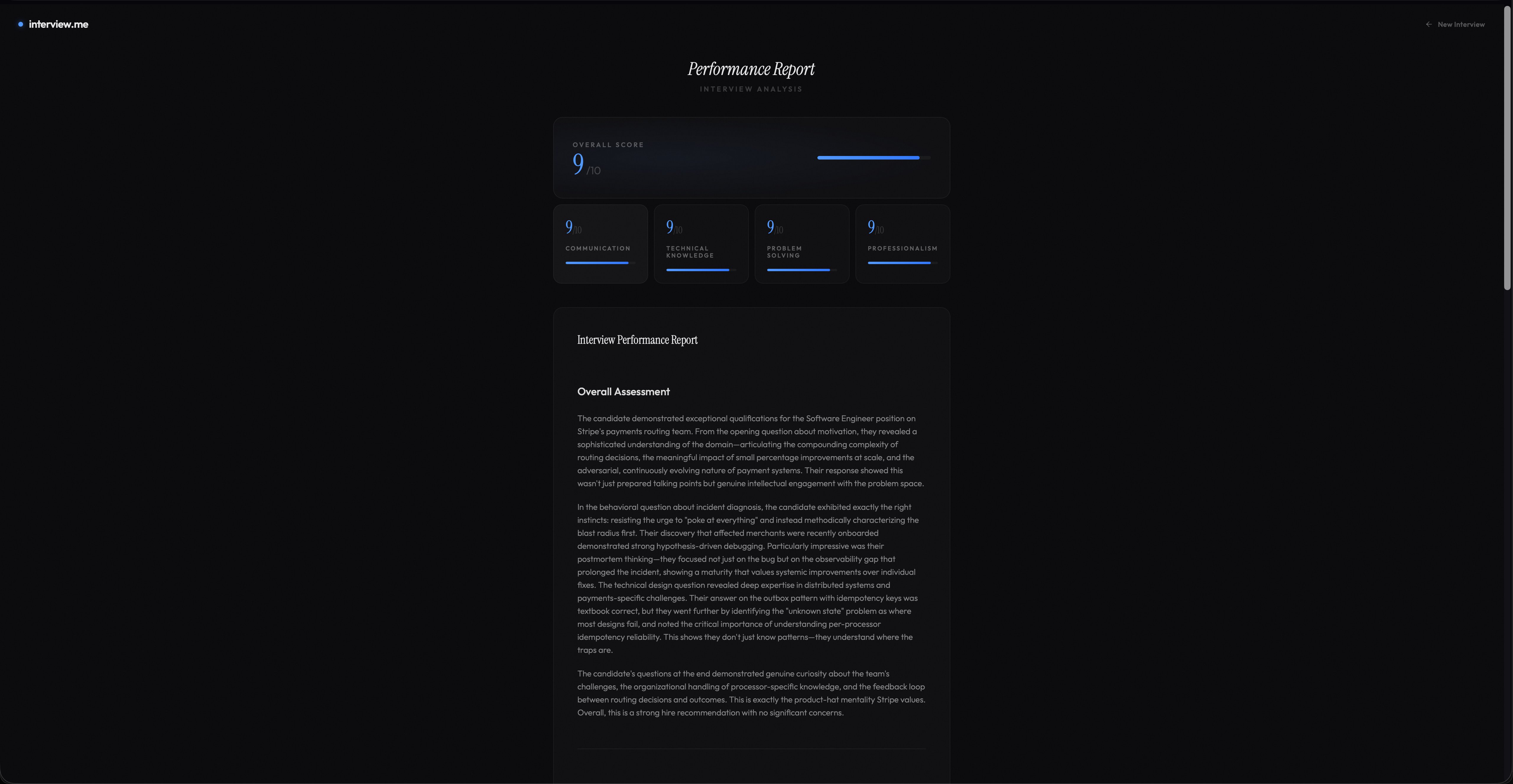
When the interview wraps up, the LLM evaluates the full transcript and streams a scored performance report with feedback on every question: what landed, what didn't, and where to focus next.
The UI is built with shadcn/ui, Framer Motion, and a custom canvas-based animated avatar that responds to the interviewer's speaking state. Dark theme, clean typography (Instrument Serif + Outfit), and smooth page transitions throughout.
Challenges We Faced
Enforcing brevity on the interviewer. LLMs are naturally verbose; they want to acknowledge, encourage, and elaborate. A real interviewer asks one question and waits. We discovered that prompt placement matters as much as prompt content: a brevity constraint only works when it's the last system message the model sees. We combined that with per-turn token caps (256 tokens early, 384 later) and a hard 40-word limit to keep the AI disciplined.
Real-time audio streaming. Conversational latency kills immersion. If the user finishes talking and waits three seconds for a response, it stops feeling like a conversation. We stream ElevenLabs audio through the MediaSource API, buffering MP3 chunks into a SourceBuffer that plays as data arrives. Managing buffer state, handling cancellations mid-stream, and falling back gracefully when the connection drops took significantly more iteration than expected.
Browser speech recognition is unreliable. Chrome's Web Speech API silently terminates sessions, fires false error events, and gives no way to distinguish "the user stopped talking" from "I decided to stop listening." We built a resilience layer with auto-restart (up to 3 retries), dual silence timers, and an internal flag to differentiate intentional stops from browser-forced ones.
Handling unpredictable candidates. People don't behave like scripts. Some try to interview the interviewer. Some give one-word answers. Some try to wrap up after two questions. We added pattern detection for these behaviors; the AI redirects gracefully without breaking character, keeping the interview productive regardless of what the candidate throws at it.
Session recovery. If a user refreshes mid-interview, the state needs to recover cleanly, no duplicate messages, no lost context. The reconnection logic inspects the last message in the transcript: if the AI's response was lost mid-stream, it rolls back the orphaned user message and replays from the last complete turn, letting the candidate pick up naturally.
Built With
- digitalocean
- gradient
- postgresql
- react
- tailwind
- vite



Log in or sign up for Devpost to join the conversation.