-
-
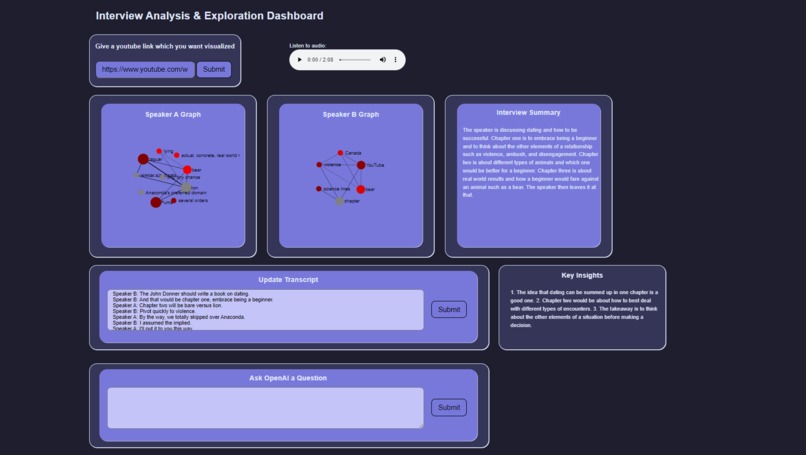
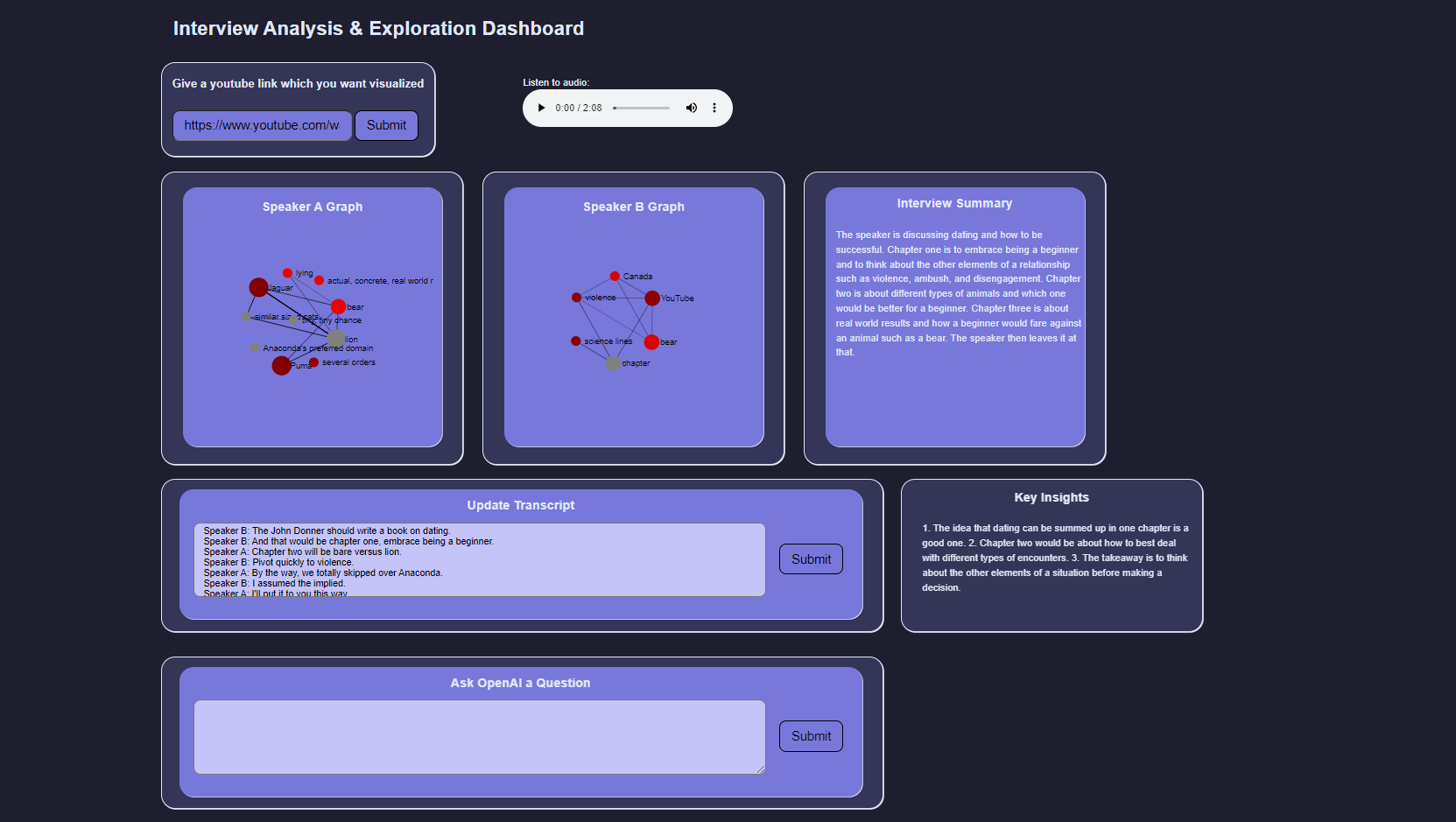
Dashboard example
Inspiration
Interviews are a vital component of collecting data, both in industry, such as in UXR, and in academia, e.g., in the social sciences. Analyzing and transcribing interviews is a time-consuming and costly task that often requires multiple tools (e.g., separate transcription & analysis software, with much manual effort). We thought that building a single solution that helps analyze and understand interviews would be a great potential solution to this problem.
What it does
Given a YouTube video containing an interview with two speakers, we produce graphs outlining key phrases and their relationship that each speaker mentioned. We also produce a summary and key insights from the discussion. The user is also able to adjust the produced transcript to re-create the summary and key insights and is able to use OpenAI to ask questions about the interview.
How we built it
We used Flask to run a service locally with a simple front end (just HTML template rendering with some Javascript & CSS). First, we use youtube-dl to download the YouTube video corresponding to the link the user provided. We then upload this to AssemblyAI and request a transcript + key phrases/words, sentiment, and speaker information. Given this, we can produce graphs, where the nodes correspond to a key phrase from a speaker (node size is the phrase frequency, color is the sentiment), and the links between nodes are determined by the similarity of phrases, which is computed using a sentence-transformer (i.e., produce embeddings for each phrase, compute cosine similarity).
We then use OpenAI to further analyze the output of the interview. Using some prompts + the conversation transcript, we ask OpenAI to produce a summary and key insights from the interview. Additional updates and questions are also handled through OpenAI.
Challenges we ran into
There were three main challenges that we faced:
- OpenAI cannot handle very long inputs (i.e., a transcript of a video over 5 minutes might have too many tokens). Solution: For long transcripts, we split it into sections and shrink each through OpenAI using a prompt (i.e., "Rewrite the following conversation, removing uninteresting and irrelevant sentences" + rest of the conversation). After shrinking, we join the sections again. This is recursively repeated until the full prompt is sufficiently succint. This shorter prompt is then used for any future OpenAI calls.
- The time it takes to download a YouTube video and then process this through AssemblyAI is quite long. Solution: We saved mp3s and transcript information of videos that we have processed in the past. So if we ever want to re-run for a video, it only needs to redo the OpenAI calls.
- We're not very familiar with existing frontend frameworks, hence we used a basic HTML templates + CSS/JS. Although we are very proud of how beautiful our dashboard looks, there are some minor improvements that could have been made...
- The key phrases are not always the most intuitive/nice to use
Accomplishments that we're proud of
- We produced a service with multiple features despite being a team of two people
- The caching/saving solution was quite fun to build and worked nicely
- For the most part, we wrote pretty clean and easy to understand code (referring to the backend...)
What we learned
- We gained a better understanding of existing services for using SATO AI models
- We learned Flask.
- We learned some new javascript libraries (Axios, d3.js)
- We learned collaboration and the power of friendship
What's next for Interview Analysis & Exploration Dashboard
- Improve key phrases and topic extraction
- Allow more user interaction with the data
- Allow upload of an mp3, rather than just a YouTube video link
- Further explore prompt engineering
- Further discussion with experts that might use such a platform, to gain a better understanding of what they would like to see

Log in or sign up for Devpost to join the conversation.