-
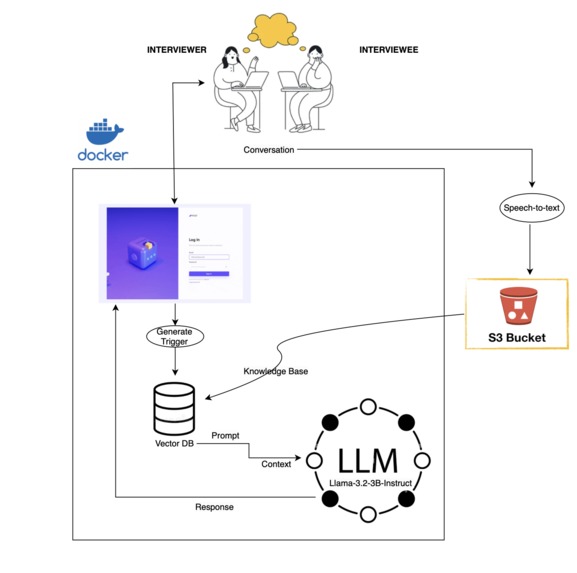
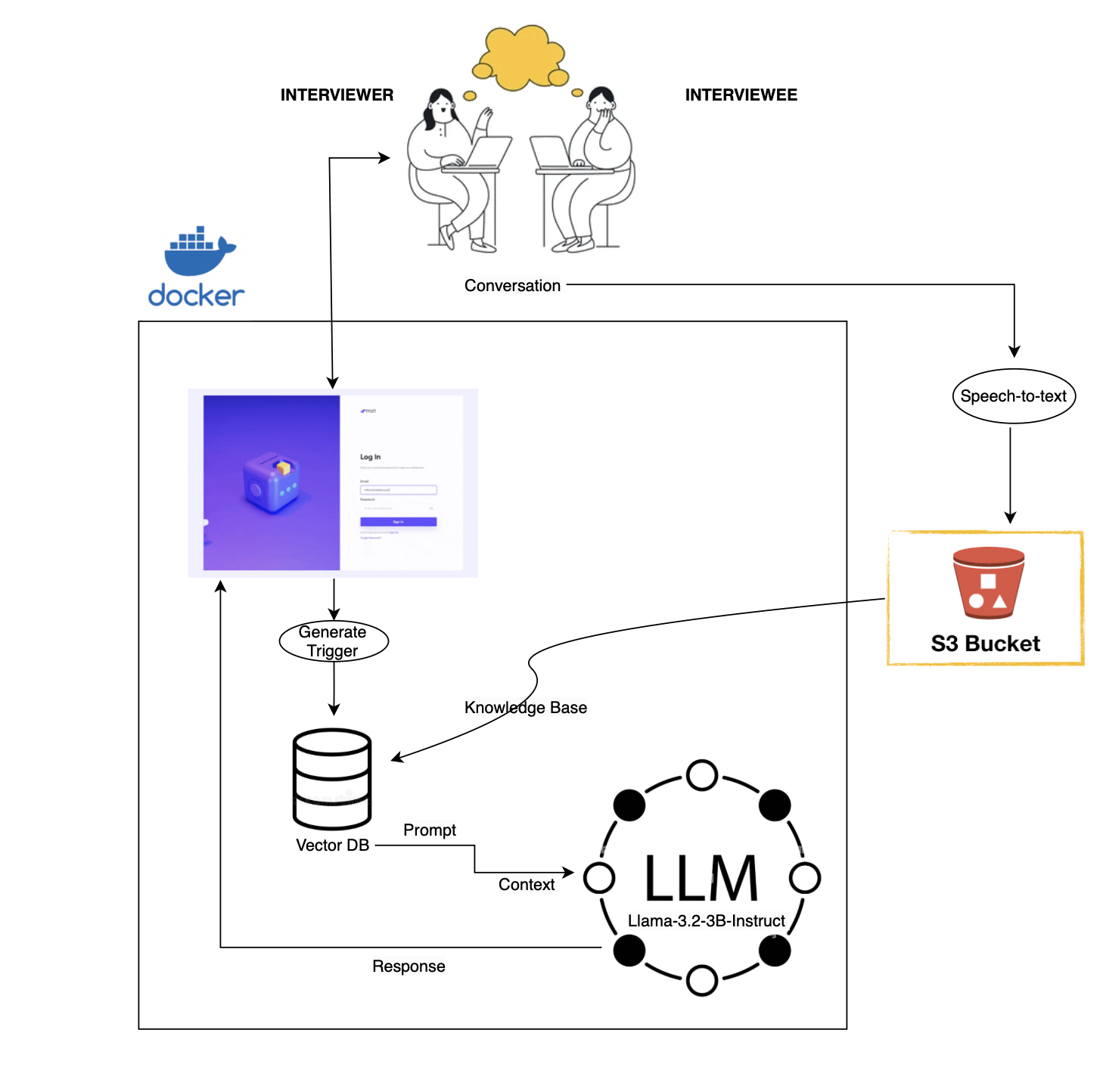
Design and Architecture Diagram
-
Interview AI in action
Inspiration
During previous stints at our companies, we regularly interviewed people who applied in accordance to the Job Description, but there were times where we needed an extra hand. This can also help in situations where the tech stack is niche and the way of working is unique to the team, as in using certain tools and technologies in a slightly different way than it typically is used. In these circumstances, even with experience using a tech stack or implementing a process, there could be memory fade, and a great follow-up question that could help assess a candidate might get missed. This could potentially lead to the wrong candidate being hired, which could lead to long term losses in terms of either shipping speed, knowledge, or even revenue.
What it does
It listens in on the interview as it is happening, and using its preloaded context which consists of tech stack knowledge, processes used in the team, and other general information as its knowledge base, formulates and assists the interviewer in creating real time, personalised question for the interviewee by assessing their responses to the questions that the interviewer is asking. This can help assess the candidate better, and make sure that the employers hire exactly the person they are looking for to take their team and product forward.
How we built it
First, we started by building a tech layer using VOSK that listens to the interview, and captures it in real time. Then, this converted text is piped to a S3 DB, from where it can be used for both the current solution, and for further analytics. In the current solution, on scheduled intervals, the converted text is fed to a Huggingface transformer layer, which converts the sentences into embedding, and stores them into the FAISS Index, which is an in-memory vector DB. Here, using Langchain, we combine the vector embedding, the pre-stored context on any specific thing that the employer might be particular about or interested in. This is then passed to our custom prompt, which is all then sent to a locally running service of Meta's LLama 3.2-3B-Instruct model, which constructs and returns a good set of follow-up questions based on how the conversation is going. The systems from after the text S3 bucket and excluding the frontend are containerised, and deployed. In the end, this response is presented on a Streamlit frontend, which will keep running side by side as an assistant to the interviewer, and whenever the interviewer wants, they can have a running stream of suggested questions being generated for them.
Challenges we ran into
Compute and memory issues, LLM hosting, Architecture building and finetuning, Containerization, Multi-audio channel streaming, Frontend generation
Accomplishments that we're proud of
Staying up all night :), collaboration, learning and implementing new tech on the go, networking
What we learned
LLM Finetuning, Speech to text to vector embedding conversion, Multi audio channel transformations, Terraform deployment, Streamlit frontend deployment, Prompt engineering, Feature engineering
What's next for Interview AI
This can be a monetised using a license based model where team in a company can personalize the pre loaded context, and use it according to their teams. Adding to that, it can be a NLP based analytics and reporting solution for interviewers, to provide and analyze metrics around the people they interviewed, the responses given by successful candidates, and being able to visualize and narrow down success factors around hiring. The raw object data as well as the dashboards generated from this future scope feature can help other aspiring candidates who are looking to fine tune their skills and get hired.
Built With
- amazon-web-services
- auth0
- css
- docker
- faiss
- fastapi
- html
- huggingface
- javascript
- langchain
- llama
- llm
- pyaudio
- python
- s3
- streamlit
- transformers
- vosk

Log in or sign up for Devpost to join the conversation.