-
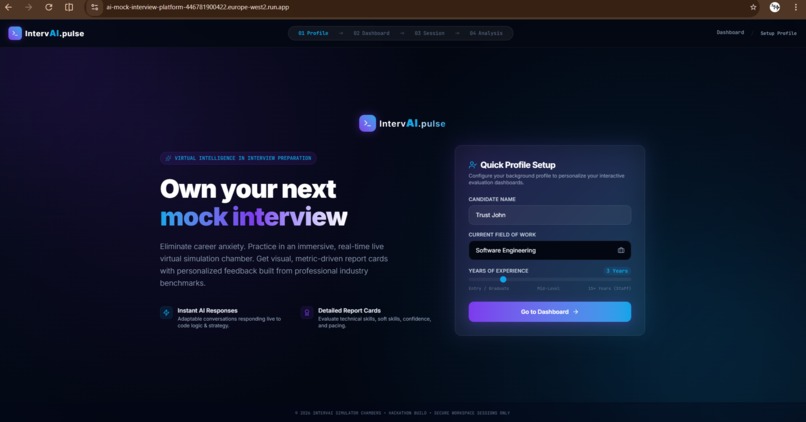
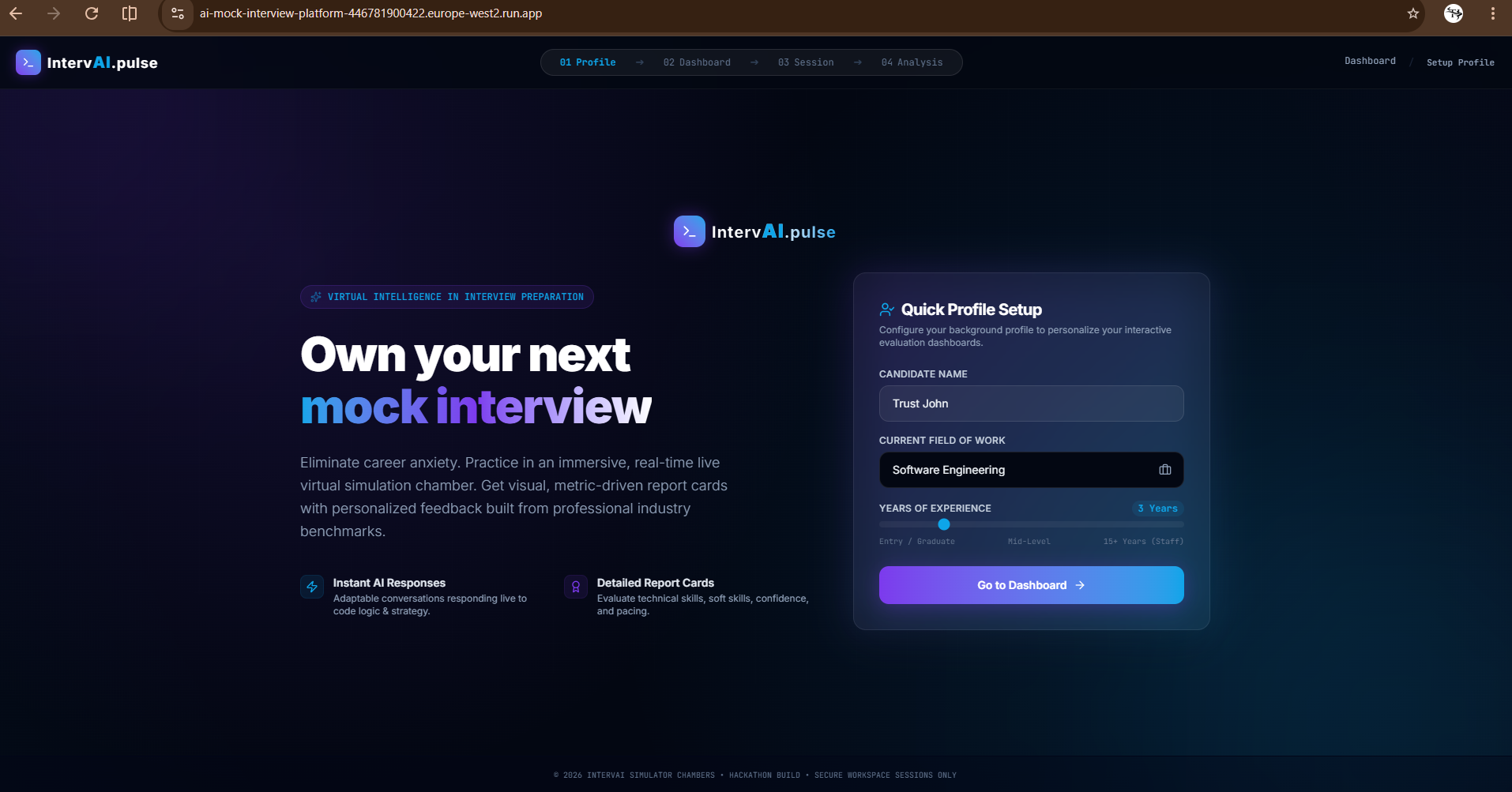
Home Page
-
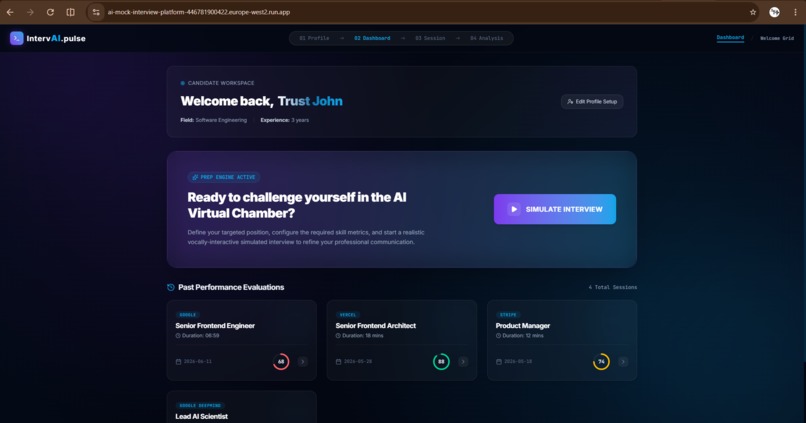
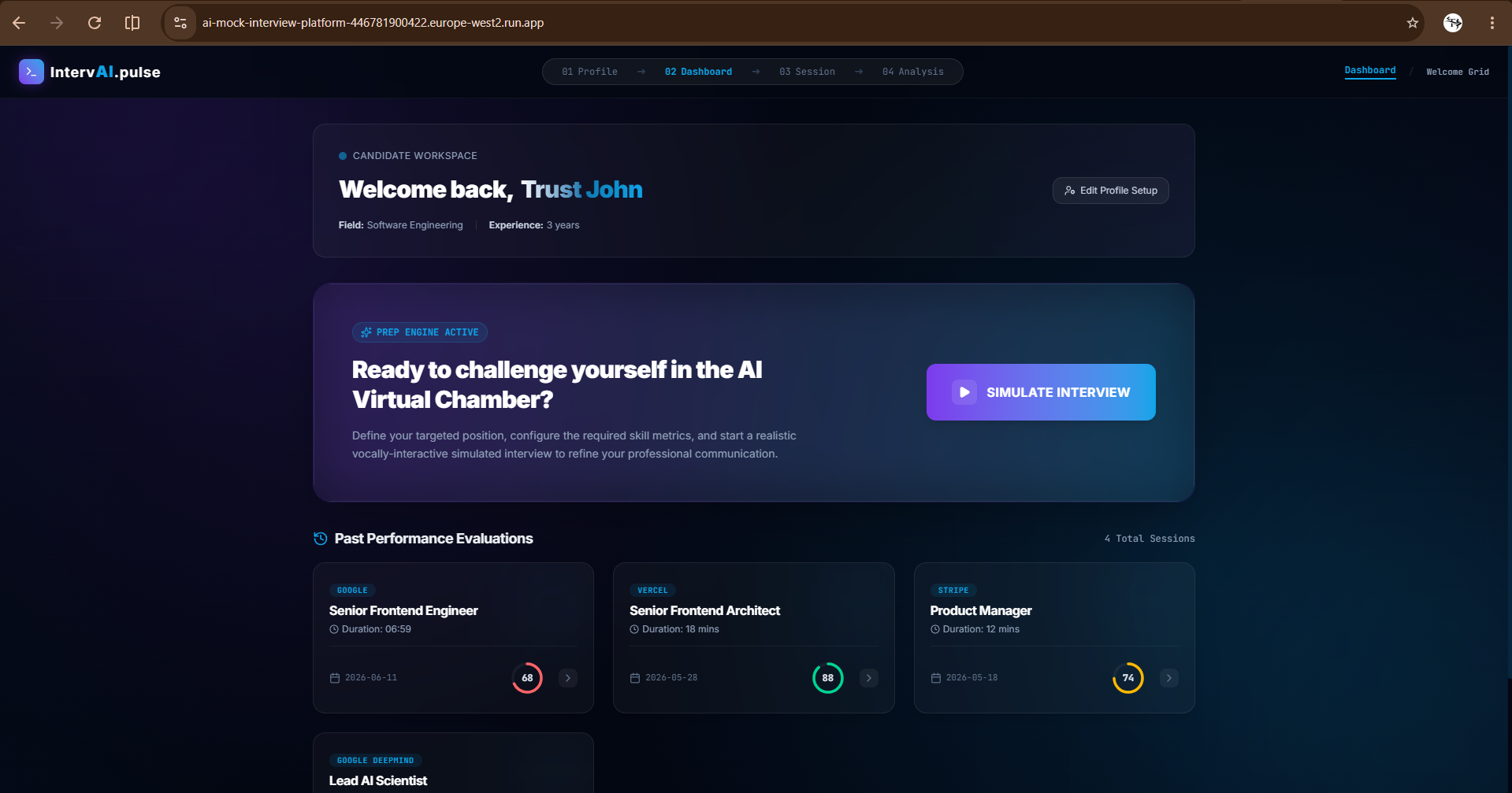
User Dashboard
-
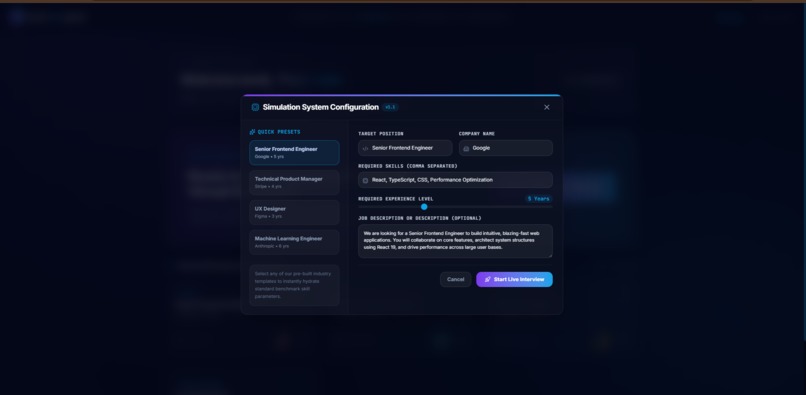
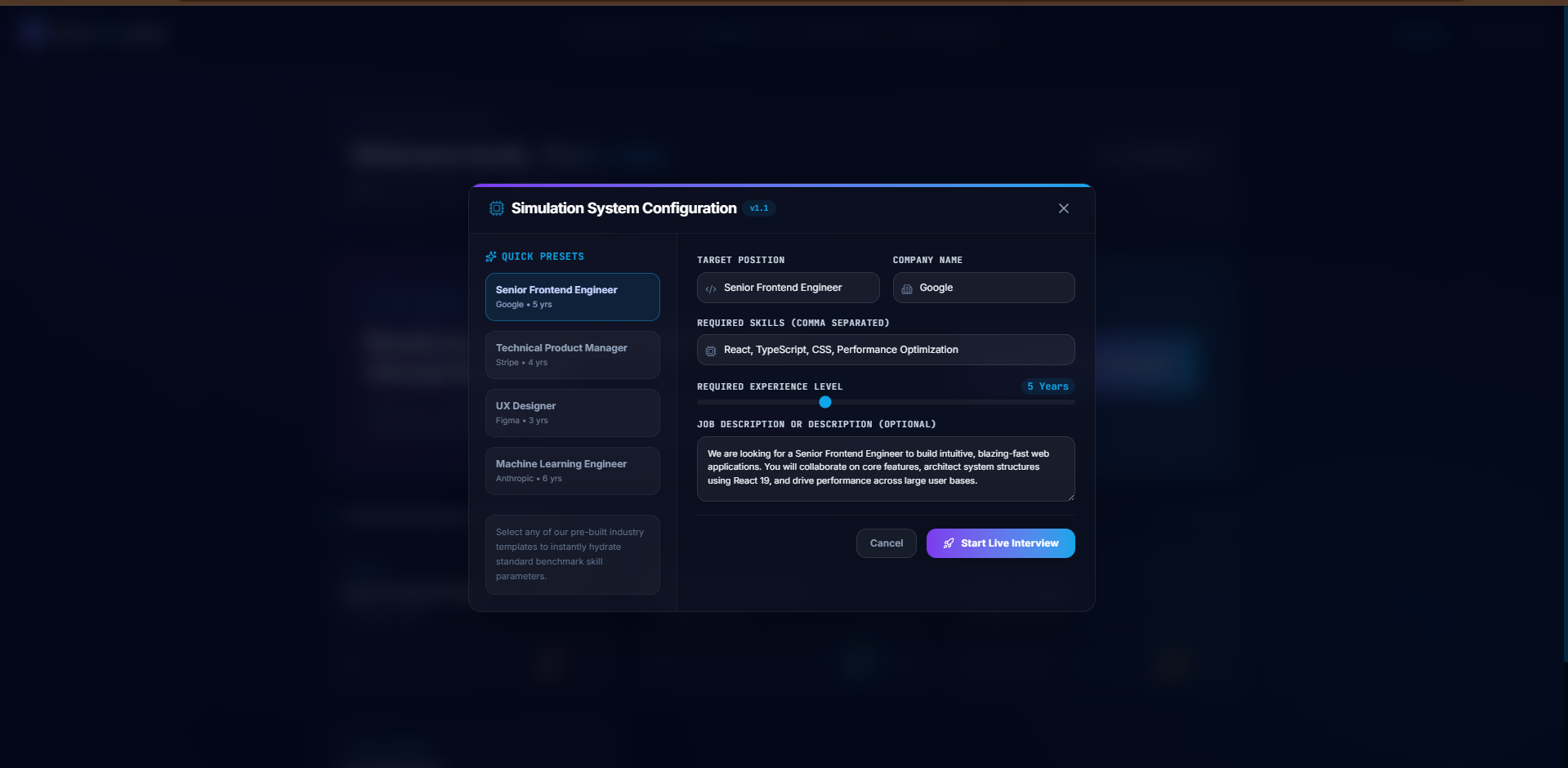
Enter Interview Details
-
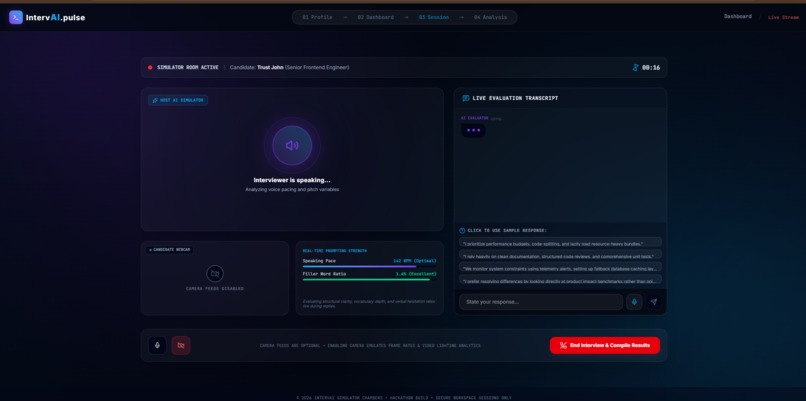
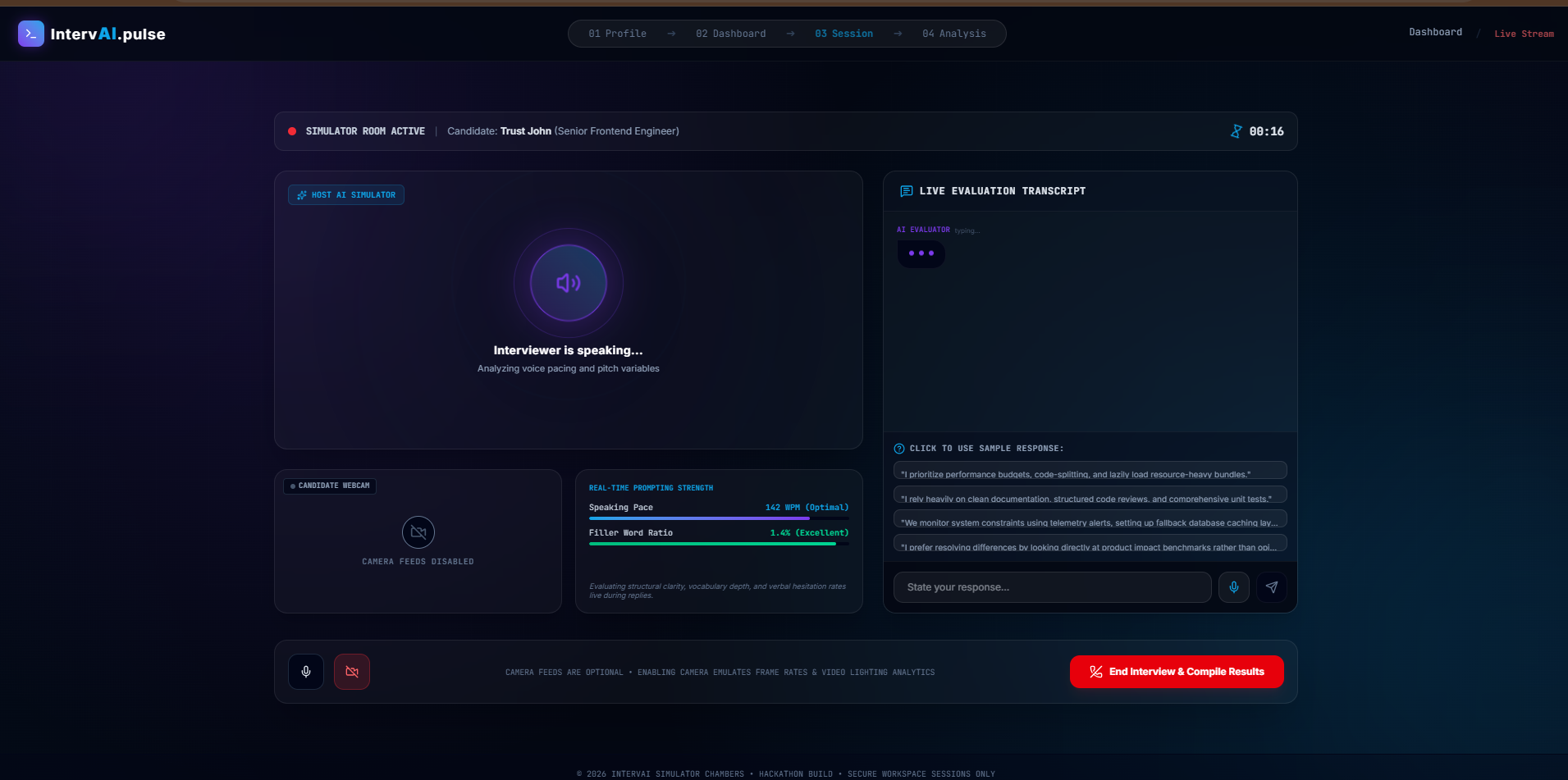
Live Interview Session
-
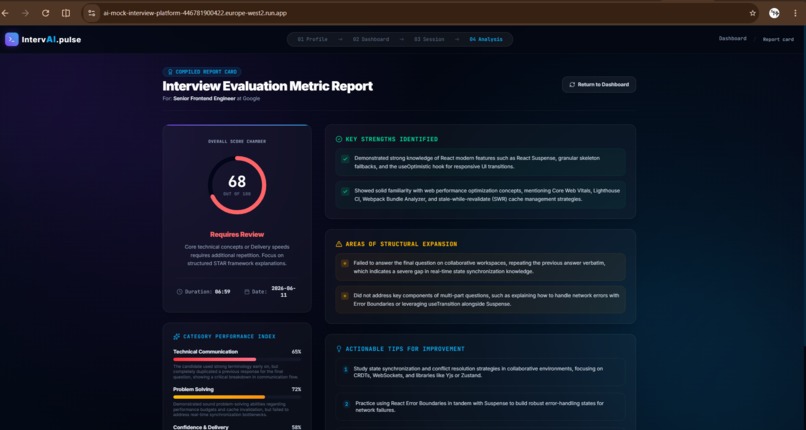
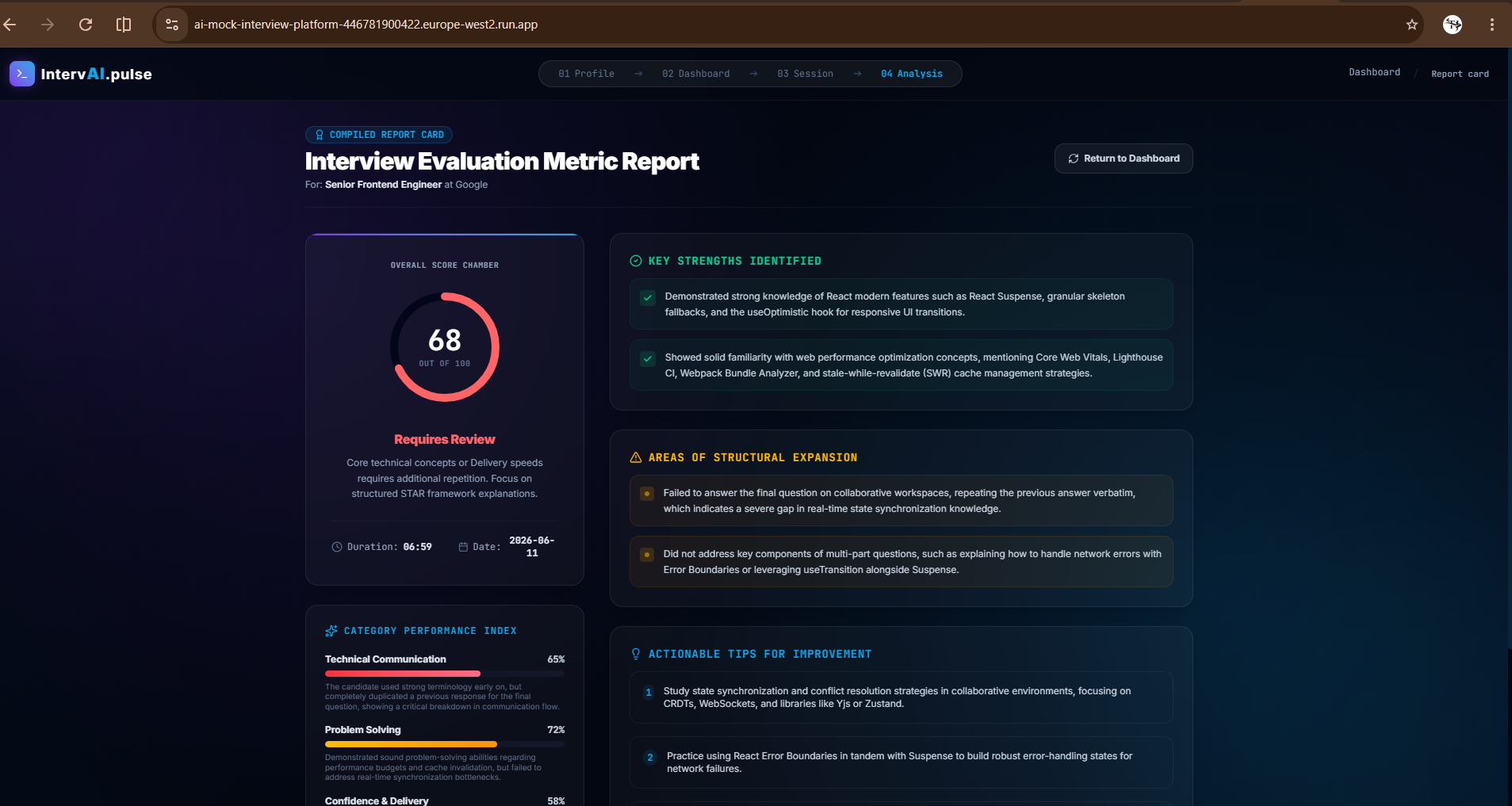
Interview Results
💡 Inspiration
Preparing for modern technical and behavioral interviews is often a dry, static, and stressful experience. Candidates are usually left reading outdated question banks or talking to silent text-box bots that do not simulate the real, high-pressure spoken rhythm of a live interview.
I wanted to change that. I built IntervAI—an immersive, real-time audio and video mock interview simulator. It mimics the natural flow of a live tech screening by speaking to you, listening to your verbal responses, and giving you instant feedback to help you refine your presentation on the fly.
🚀 What it does
IntervAI places you in an interactive mockup of a video interview room, complete with an active mock-webcam feed and live session timers.
- Realistic Spoken Interactions: The AI interviewer greets you, reviews your target position and job description, and asks tailored questions.
- True Voice-to-Text Dictation: Using continuous speech recognition, IntervAI captures your spoken response word-for-word and displays your live transcript, letting you converse fully without keyboard stress.
- Structured Audio Synthesis: The interviewer speaks back to you with real-time text-to-speech synthesis (TTS), creating a cohesive, conversational rhythm.
- Interactive Coached Alternatives: For every question asked, the server dynamically generates 4 diverse, high-quality sample answers representing different technical or behavioral angles. You can click these alternatives to test the interviewer's logical flow or use them as guiding templates to craft your own response.
🛠️ How I built it
I designed and constructed IntervAI as a highly optimized full-stack TypeScript application:
- Frontend: I developed a single-page application using React 18, Vite, and TypeScript, styled with a slate-dark modern aesthetic using Tailwind CSS and responsive micro-animations.
- Backend: An Express.js server serves the API endpoints, coordinating prompts, saving conversation memory, and proxying requests securely to keep API keys hidden.
- AI & Structure: I wrote the orchestration layer using the modern
@google/genaiSDK and deployed Gemini 3.5. I implemented strict JSON schema structures (Type.OBJECT) to force the model to cleanly return the spoken question and the 4 alternative demo response choices in parallel inside a single API trip. - Speech Integration: I linked browser-native
SpeechRecognitionhooks with the incoming audio stream to automatically pause dictation while the AI speaks-back, and resume listening once the interviewer finishes.
⚠️ Challenges I faced
- Speech-to-Text in Iframe Sandboxes: Capturing continuous voice transcription inside browser iframe sandboxes presents strict permission hurdles. I overcame this by explicitly requesting a native microphone stream (
getUserMedia) ahead of time, ensuring browser authorization dialogs trigger reliably across all nested boundaries. - Asynchronous Rhythm Coordination: Handling audio synthesis playback states, microphone active statuses, and loading flags without building racing conditions was challenging. I solved this by tracking real-time reference states (
useRef) to dynamically pause and resume the voice dictation loops whenever the AI is actively outputting speech. - Structured Generative Output: Getting the model to consistently generate exactly 4 distinct, ultra-high-quality, non-repetitive demo answers required rigorous JSON schema optimization and targeted contextual instruction design.
🎓 What I learned
I gained a deep appreciation for full-stack event synchronization, specifically the nuances of real-time web audio manipulation and audio buffer playbacks. Tuning the @google/genai SDK with custom schemas taught me how to turn traditional chatbot lines into highly structured, schema-compliant application state payloads.
🔮 What's next for IntervAI
I plan to expand IntervAI with:
- Behavioral AI Scorecards: Providing an action-oriented post-interview report containing granular metrics on speaking rate, technical keyword usage, filler-word counts, and sentiment analysis.
- Live Design Whiteboards: Integrating a collaborative scratchpad and terminal canvas so candidates can tackle live system design grids and algorithmic code blocks concurrently while conversing with the AI.
Built With
- express.js
- framer
- google-gemini-3.5
- lucide-icons
- motion
- node.js
- react
- tailwind-css
- typescript
- vite
- web-audio-api
- web-speech-api


Log in or sign up for Devpost to join the conversation.